从源码看 LinkedHashMap
前言
在阅读这篇文章之前,我们应该已经了解了 HashMap 的底层实现。
HashMap 是一个存储键值对的集合,jdk1.8 中底层的数据结构有数组+链表+红黑树,对于 get 、 put 操作,时间复杂度是O(1)的,是不是很优秀?
但是, HashMap 插入元素之后,对它进行遍历,遍历的结点顺序是无序的,如果我们希望遍历的顺序是可预测的呢?这时, LinkedHashMap 闪亮登场!

从 LinkedHashMap 的源码中可以看到, LinkedHashMap 继承了 HashMap ,实现了 Map 接口。继承,使 LinkedHashMap 包含 HashMap 的所有成员(除了 private 成员),而且和 HashMap 具有相同的基础接口。
那么 LinkedHashMap 是如何在 HashMap 的基础上,实现可预测的迭代顺序的?
以下,我们将从 LinkedHashMap 的 Entry 结点类和部分属性、 put 操作、 get 操作和 containsValue 操作来了解它。
源码
看源码是很好的学习方式。但在之前我也看过集合类的相关源码,由于停留在能看懂、理解主要思想的地步,在实习面试的时候被问到表现的也不尽人意。所以,不仅仅是看源码,还要思考和总结,还可以多看些博客,也学习别人的思考和总结。
嗯,那我们来看源码吧。
Entry结点类和部分属性
/*** LinkedHashMap 的 Entry 结点类继承自 HashMap 的 Node 结点
* 类,添加了 before 、 after 指针,用来维护双向链表的顺序。
* @param <K>
* @param <V>
*/
staticclassEntry<K,V> extendsHashMap.Node<K,V> {
Entry<K,V> before, after;
Entry(int hash, K key, V value, Node<K,V> next) {
super(hash, key, value, next);
}
}
privatestaticfinallong serialVersionUID = 3801124242820219131L;
/**
* 双向链表的头节点
*/
transient LinkedHashMap.Entry<K,V> head;
/**
* 双向链表的尾节点
*/
transient LinkedHashMap.Entry<K,V> tail;
/**
* true - 按访问顺序
* false - 按插入顺序
*/
finalboolean accessOrder;
LinkedHashMap 的结点类 Entry 继承了 HashMap 的 Node 类,多了两个属性 before 和 after。 before 是指向前一个结点的指针, after 是指向后一个结点的指针。
我动手画了画HashMap 和 LinkedHashMap 的大致存储结构,如下图。
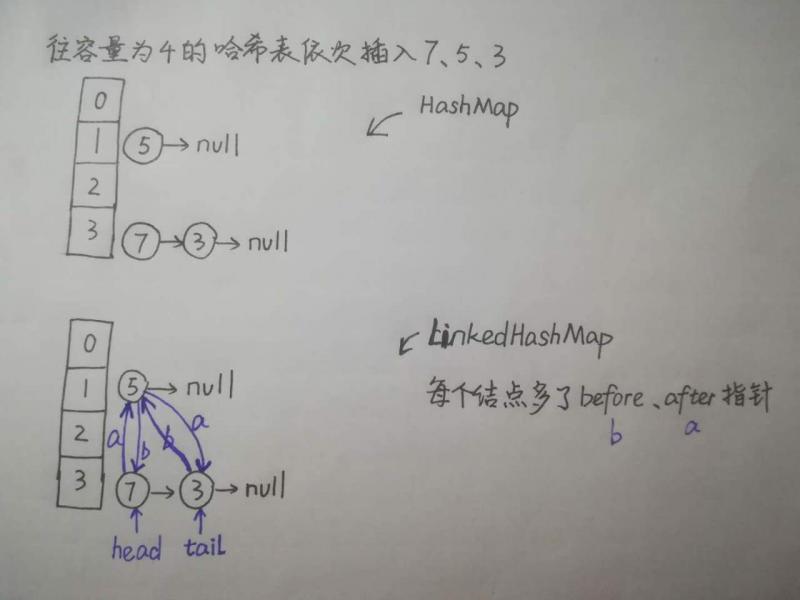
HashMap 和 LinkedHashMap 最大的不同是什么呢?LinkedHashMap 前面多了个 Linked ?我们可不是这么表面的人。从图中可以看到,通过 after、before 指针,LinkedHashMap 另外维护了一条双向链表。
现在我们可以从双向链表的头节点 head 开始,根据 after 指针指向的结点逐个遍历,得到的是有一定顺序的序列。
我们再看回上面贴的源码, LinkedHashMap 还有一个属性 accessOrder。我们一直说到 LinkedHashMap 可以实现可预测的迭代顺序,这个顺序是指什么顺序呢?
默认情况下,LinkedHashMap 的双向链表维护的顺序是结点插入的顺序,头节点是最早插入的结点。如果我们在构造函数中传入 accessOrder 为 true,双向链表维护的是结点访问的顺序,头节点是最久未访问的结点。构造函数我就不贴代码了,我们接着看!
put操作
我们在 LinkedHashMap 中找不到 put 方法,这是因为它并没有重写父类 HashMap 的 put 方法。这里用到了一种典型的设计模式:模板方法模式。
模板方法模式,在《大话设计模式》中是这样说的:
模板方法模式,定义一个操作中的算法的骨架,而将一些步骤延迟到子类中。模板方法模式使得子类可以不改变一个算法的结构即可重定义该算法的某些特定步骤。
LinkedHashMap 只是重写了父类 HashMap 的 putVal 方法中的某些方法。
我们来回顾下 putVal 方法的具体流程和了解 LinkedHashMap 重写的方法。
首先第一步判断哈希表是否为空或长度是否为0,如果是的话,调用 resize()方法。
找到结点对应的桶的位置,如果桶中没有结点则 new 一个结点。

这里,LinkedHashMap 重写了 newNode 方法。下面是 LinkedHashMap 重写的 newNode 方法,其中,LinkedHashMap 创建的是自己类中的 Entry 结点,并且要维护双向链表,在双向链表的尾部添加新创建的结点。
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e){LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
/**
* 在双向链表的尾部添加结点
* @param p
*/
privatevoidlinkNodeLast(LinkedHashMap.Entry<K,V> p){
LinkedHashMap.Entry<K,V> last = tail;
tail = p;
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
}
如果桶中有结点的话,判断头结点和要插入的结点是否相等。如果相等,执行第8步。
如果不相等,且是树结点,用红黑树插入。
如果是链表结点,遍历链表。
遍历时,如果链表长度大于等于8,树形化。
遍历时,如果结点和要插入的结点相等,不再继续遍历。
要插入的结点已存在且onlyIfAbsent是false,将value赋值给已存在结点,返回旧的value。
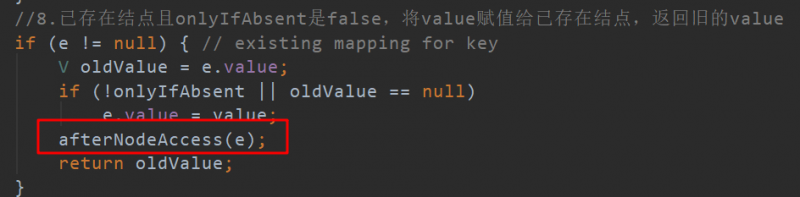
这里,LinkedHashMap 重写了 afterNodeAccess 方法,这个方法在 HashMap 中是个空方法。afterNodeAccess 翻译过来是 “在结点访问之后”,LinkedHashMap 在访问结点后要做什么呢?
我们看下面的 afterNodeAccess 方法的实现,方法中它是判断了 accessOrder 为 true 并且我们传入的结点参数不是尾节点时,才会做一些额外的操作。accessOrder 在上面提到了,如果它是true,双向链表维护的顺序是结点访问的顺序。这一点正是通过 afterNodeAccess 方法实现的。
LinkedHashMap 访问一个结点之后,会调用 afterNodeAccess 方法,如果accessOrder 为 false或者结点是已经是最后一个结点,就不需要其它操作来维护链表。否则,需要将我们访问的结点放到双向链表的尾部。
voidafterNodeAccess(Node<K,V> e){ // move node to last
LinkedHashMap.Entry<K,V> last;
// 如果accessOrder为true,代表按访问顺序维护链表
// 则将e移至链表尾部
if (accessOrder && (last = tail) != e) {
LinkedHashMap.Entry<K,V> p =
(LinkedHashMap.Entry<K,V>)e, b = p.before, a = p.after;
p.after = null;
//先把原来的结点删除
if (b == null)
head = a;
else
b.after = a;
if (a != null)
a.before = b;
else
last = b;
//再在尾部添加结点
if (last == null)
head = p;
else {
p.before = last;
last.after = p;
}
tail = p;
++modCount;
}
}
modCount++。
判断是否需要扩容。
调用afterNodeInsertion方法。
afterNodeInstertion 在 HashMap 中也是个空方法,LinkedHashMap重写了它,用来执行插入元素后的额外操作。
我们看下面的源码。源码中注释说"possibly remove eldest",可能删除掉最老的。
这个方法的思路是,如果不是构造函数调用,且哈希表中存在元素,且需要删除 eldest 元素,则从链表和哈希表中删除双向链表头结点。
removeEldestEntry 方法在 LinkedHashMap 默认返回 false 。我们可以通过重写这个方法来实现LRU缓存。
voidafterNodeInsertion(boolean evict){ // possibly remove eldest
LinkedHashMap.Entry<K,V> first;
//evict是false,是构造方法调用,就不用再判断需不需要删除eldest元素
if (evict && (first = head) != null && removeEldestEntry(first)) {
K key = first.key;
removeNode(hash(key), key, null, false, true);
}
}
/**
* 每次插入新Node时,是否需要删除最老的结点。
* @return true-删除最老结点,false-不删除
*/
protectedbooleanremoveEldestEntry(Map.Entry<K,V> eldest){
returnfalse;
}
get操作
LinkedHashMap 重写了 get方法。
LinkedHashMap 的 get 操作比 HashMap 多了一步,判断 accessOrder 是否为true,如果是,需要更新访问的结点在双向链表中的位置。
public V get(Object key){
Node<K,V> e;
// 寻找key对应结点
if ((e = getNode(hash(key), key)) == null)
returnnull;
// 如果需要按访问时间排序,则更新结点在双向链表中的位置
if (accessOrder)
afterNodeAccess(e);
return e.value;
}
containsValue操作
因为LinkedHashMap中使用双向链表维护了所有Node,所以只需要遍历双向链表即可遍历所有Node。而不用遍历哈希表。
/*** LinkedHashMap的containsValue方法
*/
publicbooleancontainsValue(Object value){
for (LinkedHashMap.Entry<K,V> e = head; e != null; e = e.after) {
V v = e.value;
if (v == value || (value != null && value.equals(v)))
returntrue;
}
returnfalse;
}
下面是 HashMap 中的 containsValue方法。HashMap 中需要遍历每个桶,看看桶是否是空的,不是的话再去一个一个判断结点是不是我们要找的。
/*** HashMap的containsValue方法
*/
publicbooleancontainsValue(Object value){
Node<K,V>[] tab; V v;
if ((tab = table) != null && size > 0) {
for (int i = 0; i < tab.length; ++i) {
for (Node<K,V> e = tab[i]; e != null; e = e.next) {
if ((v = e.value) == value ||
(value != null && value.equals(v)))
returntrue;
}
}
}
returnfalse;
}
总结
- LinkedHashMap 继承了 HashMap ,实现了 Map 接口。 LinkedHashMap 和 HashMap 的区别在于, LinkedHashMap 底层的数据结构实现不仅有数组+链表+红黑树,另外还维护了一个双向链表,用来维护顺序。
- LinkedHashMap 的链表结点类 Entry 继承了 HashMap 的 Node 类,增加了两个指针 before 和 after ,用来维护双向链表。
- LinkedHashMap 结点顺序默认是插入顺序(最近插入的在尾部),还维护了一个参数 accessOrder ,如果在构造时传入该参数是 true ,那么双向链表维护的顺序是结点访问顺序(最近访问的在尾部)。
- put()操作: LinkedHashMap 没有重写 HashMap 的 put 操作。重写了newNode 方法,afterNodeAccess 方法,afterNodeInsertion 方法。
- get()操作:LinkedHashMap 重写了 get 方法。LinkedHashMap 的 get 操作比 HashMap 多了一步,判断 accessOrder 是否为true,如果是,需要更新访问的结点在双向链表中的位置。
- LinkedHashMap 可以用来实现 LRU 算法。
如果有错误的地方欢迎大家指出!
以上是 从源码看 LinkedHashMap 的全部内容, 来源链接: utcz.com/a/21241.html