JDBC内幕subquery
subquery
子查询指一个查询语句嵌套在另一个查询语句内部的查询,在 SELECT 子句中先计算子查询,子查询结果作为外层另一个查询的过滤条件,查询可以基于一个表或者多个表,子查询中常用的操作符有 ANY(SOME)、ALL、IN 和 EXISTS。常见形式如下

数据中间件一般处理subquery思路是拆分SQL语句,先查询内部语句结果作为外部条件继续查询,整体流程类似下图
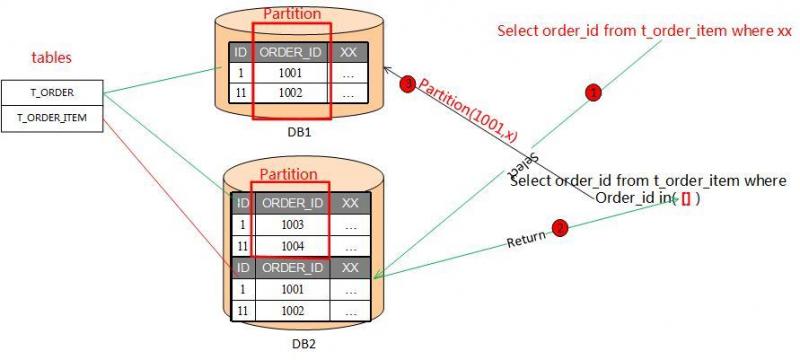
另外一种处理方式就是确定subquery内部查询与外部查询是否在同一个分片(db)上,如果可以确定这层关系,则可以将SQL直接发送到某个分片上,一般在非代理数据中间件实现中,可以考虑这种方式规避拆分subquery,尤其在oracle嵌套分页查询时需要面临这个问题。
sharding subquery
了解subquery后,我们来看看sharding-JDBC是怎么处理subquery的,希望读者对原理有了解后,能正确使用子查询,首先我们来验证上边这个场景,SQL如下
select * from t_order where order_id in (select order_id from t_order_item where order_name ='zhangsan')执行结果有点出乎意料
java.lang.IllegalStateException: Must have sharding column with subquery. at com.google.common.base.Preconditions.checkState(Preconditions.java:173)
at org.apache.shardingsphere.core.route.router.sharding.ParsingSQLRouter.checkSubqueryShardingValues(ParsingSQLRouter.java:111)
at org.apache.shardingsphere.core.route.router.sharding.ParsingSQLRouter.route(ParsingSQLRouter.java:75)
at org.apache.shardingsphere.core.route.StatementRoutingEngine.route(StatementRoutingEngine.java:56)
提示我们必须要分片键,我们可以把t_order_item表分片键改为order_name
t_order_item: actualDataNodes:ds_0.t_order_item
tableStrategy:
inline:
shardingColumn:order_name
algorithmExpression:t_order_item
databaseStrategy:
inline:
shardingColumn:order_name
algorithmExpression:ds_0
执行结果还是同样的错误,将SQL改写如下
select * from t_order where order_id in (select order_id from t_order_item where order_id =1001)执行正常,不猜了,看下源码是怎么处理的,这块和路由相关,先看下路由模块代码
public SQLRouteResult route(final String logicSQL, final List<Object> parameters, final SQLStatement sqlStatement){//此处OptimizedStatement属于ShardingSelectOptimizedStatement,主要是对SQL中的关注的部分从语法树中提取,比如order by , 聚合函数等
OptimizedStatement optimizedStatement = ShardingOptimizeEngineFactory.newInstance(sqlStatement).optimize(shardingRule, shardingMetaData.getTable(), logicSQL, parameters, sqlStatement);
boolean needMergeShardingValues = isNeedMergeShardingValues(optimizedStatement);
if (optimizedStatement instanceof ShardingConditionOptimizedStatement && needMergeShardingValues) {
checkSubqueryShardingValues(optimizedStatement, ((ShardingConditionOptimizedStatement) optimizedStatement).getShardingConditions());
mergeShardingConditions(((ShardingConditionOptimizedStatement) optimizedStatement).getShardingConditions());
}
RoutingResult routingResult = RoutingEngineFactory.newInstance(shardingRule, shardingMetaData.getDataSource(), optimizedStatement).route();
if (needMergeShardingValues) {
Preconditions.checkState(1 == routingResult.getRoutingUnits().size(), "Must have one sharding with subquery.");
}
if (optimizedStatement instanceof ShardingInsertOptimizedStatement) {
setGeneratedValues((ShardingInsertOptimizedStatement) optimizedStatement);
}
SQLRouteResult result = new SQLRouteResult(optimizedStatement);
result.setRoutingResult(routingResult);
return result;
}
optimize方法
public ShardingSelectOptimizedStatement optimize(final ShardingRule shardingRule,final ShardingTableMetaData shardingTableMetaData, final String sql, final List<Object> parameters, final SelectStatement sqlStatement)
{ WhereClauseShardingConditionEngine shardingConditionEngine = new WhereClauseShardingConditionEngine(shardingRule, shardingTableMetaData);
WhereClauseEncryptConditionEngine encryptConditionEngine = new WhereClauseEncryptConditionEngine(shardingRule.getEncryptRule(), shardingTableMetaData);
GroupByEngine groupByEngine = new GroupByEngine();
OrderByEngine orderByEngine = new OrderByEngine();
SelectItemsEngine selectItemsEngine = new SelectItemsEngine(shardingTableMetaData);
PaginationEngine paginationEngine = new PaginationEngine();
//核心点,获取条件,包括where条件和subquery条件
List<ShardingCondition> shardingConditions = shardingConditionEngine.createShardingConditions(sqlStatement, parameters);
List<EncryptCondition> encryptConditions = encryptConditionEngine.createEncryptConditions(sqlStatement);
GroupBy groupBy = groupByEngine.createGroupBy(sqlStatement);
OrderBy orderBy = orderByEngine.createOrderBy(sqlStatement, groupBy);
SelectItems selectItems = selectItemsEngine.createSelectItems(sql, sqlStatement, groupBy, orderBy);
Pagination pagination = paginationEngine.createPagination(sqlStatement, selectItems, parameters);
ShardingSelectOptimizedStatement result = new ShardingSelectOptimizedStatement(sqlStatement, shardingConditions, encryptConditions, groupBy, orderBy, selectItems, pagination);
setContainsSubquery(sqlStatement, result);
return result;
}
createShardingConditions方法
public List<ShardingCondition> createShardingConditions(final SQLStatement sqlStatement, final List<Object> parameters){if (!(sqlStatement instanceof WhereSegmentAvailable)) {
return Collections.emptyList();
}
List<ShardingCondition> result = new ArrayList<>();
//获取where条件
Optional<WhereSegment> whereSegment = ((WhereSegmentAvailable) sqlStatement).getWhere();
//关键点,查询中涉及到的所有表
Tables tables = new Tables(sqlStatement);
if (whereSegment.isPresent()) {
result.addAll(createShardingConditions(tables, whereSegment.get().getAndPredicates(), parameters));
}
//获取subquery条件
Collection<SubqueryPredicateSegment> subqueryPredicateSegments = sqlStatement.findSQLSegments(SubqueryPredicateSegment.class);
for (SubqueryPredicateSegment each : subqueryPredicateSegments) {
//获取具体的subquery查询条件
Collection<ShardingCondition> subqueryShardingConditions = createShardingConditions(tables, each.getAndPredicates(), parameters);
if (!result.containsAll(subqueryShardingConditions)) {
result.addAll(subqueryShardingConditions);
}
}
return result;
}
我们就用上边SQL看下Tables tables涉及的表
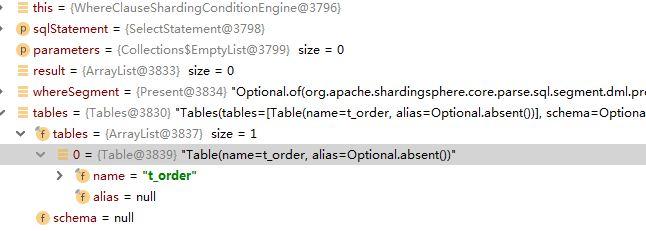
从解析结果中可以知道并未对子查询内部表名提取,则暗含着内部与外部是同一个表,验证我们猜测对不对
createShardingConditions方法获取subquery条件
private Collection<ShardingCondition> createShardingConditions(final Tables tables, final Collection<AndPredicate> andPredicates, final List<Object> parameters){ Collection<ShardingCondition> result = new LinkedList<>();
for (AndPredicate each : andPredicates) {
//从子查询条件中获取路由单元,即column-shardingValue数据结构
Map<Column, Collection<RouteValue>> routeValueMap = createRouteValueMap(tables, each, parameters);
if (routeValueMap.isEmpty()) {
return Collections.emptyList();
}
result.add(createShardingCondition(routeValueMap));
}
return result;
}
createRouteValueMap方法
private Map<Column, Collection<RouteValue>> createRouteValueMap(final Tables tables, final AndPredicate andPredicate, final List<Object> parameters) { Map<Column, Collection<RouteValue>> result = new HashMap<>();
for (PredicateSegment each : andPredicate.getPredicates()) {
Optional<String> tableName = tables.findTableName(each.getColumn(), shardingTableMetaData);
//判断当前条件中的column是不是分片键,上一步我们知道tables中只有t_order一个表
//由于当前column是 order_name 并不是t_order表的分片键,所以此处并未构造出RouteValue,
//所有就看到第一开始的异常信息 Must have sharding column with subquery.
if (!tableName.isPresent() || !shardingRule.isShardingColumn(each.getColumn().getName(), tableName.get())) {
continue;
}
Column column = new Column(each.getColumn().getName(), tableName.get());
Optional<RouteValue> routeValue = ConditionValueGeneratorFactory.generate(each.getRightValue(), column, parameters);
if (!routeValue.isPresent()) {
continue;
}
if (!result.containsKey(column)) {
result.put(column, new LinkedList<RouteValue>());
}
result.get(column).add(routeValue.get());
}
return result;
}
到这块基本处理逻辑应该了解的差不多,subquery应该是处理自生表的嵌套子查询即一个表的嵌套子查询,那我们可以推断如下的SQL应该也是可以正常执行的
select * from t_order where order_id in (select order_name from t_order_item where order_id = 1001)直接结果和推断的一样,SQL直接发往其中一个db上,这明显不正确,因为order_name 和order_id 没有任何关系,并且t_order_item的分片键并不是order_id,分析到这基本结束。
the end
由上可见sharding-JDBC对子查询支持并没有我们想象的那么强大,希望读者了解原理后可以正确的使用sharding subquery,我觉得对于subquery处理还是有不足的地方,比如类似SQL select * from t_order where order_id in (select order_name from t_order_item where order_id = 1001) 涉及多表子查询应该抛异常获取提示信息,不能直接根据 subquery条件order_id = 1001 与外部表的 路由算法直接路由,因为可能存在两张表毫无关系的情况。希望读者清楚sharding-JDBC处理对subquery的处理逻辑,正确的使用subquery
以上是 JDBC内幕subquery 的全部内容, 来源链接: utcz.com/a/19568.html