用户画像大数据环境搭建——从零开始搭建实时用户画像(四)
本章我们开始正式搭建大数据环境,目标是构建一个稳定的可以运维监控的大数据环境。我们将采用Ambari搭建底层的Hadoop环境,使用原生的方式搭建Flink,Druid,Superset等实时计算环境。使用大数据构建工具与原生安装相结合的方式,共同完成大数据环境的安装。
Ambari搭建底层大数据环境
Apache Ambari是一种基于Web的工具,支持Apache Hadoop集群的供应、管理和监控。Ambari已支持大多数Hadoop组件,包括HDFS、MapReduce、Hive、Pig、 Hbase、Zookeeper、Sqoop和Hcatalog等。
Apache Ambari 支持HDFS、MapReduce、Hive、Pig、Hbase、Zookeepr、Sqoop和Hcatalog等的集中管理。也是顶级的hadoop管理工具之一。
目前Ambari的版本已经更新到2.7,支持的组件也越来越丰富。

Hadoop的发行版本有很多,有华为发行版,Intel发行版,Cloudera发行版(CDH),MapR版本,以及HortonWorks版本等。所有发行版都是基于Apache Hadoop衍生出来的,产生这些版本的原因,是由于Apache Hadoop的开源协议决定的:任何人可以对其进行修改,并作为开源或商业产品发布和销售。
收费版本:
收费版本一般都会由新的特性。国内绝大多数公司发行的版本都是收费的,例如Intel发行版本,华为发行版本等。
免费版本:
不收费的版本主要有三个(都是国外厂商)。
Cloudera版本(Cloudera’s Distribution Including Apache Hadoop)简称”CDH“。
Apache基金会hadoop
Hontonworks版本(Hortonworks Data Platform)简称“HDP”。
按照顺序代表了国内的使用率,CDH和HDP虽然是收费版本,但是他们是开源的,只是收取服务费用,严格上讲不属于收费版本。
Ambari基于HDP安装,但是他们不同版本之间有不同的对应关系。
Ambari2.7与HDP HDF的对应关系:
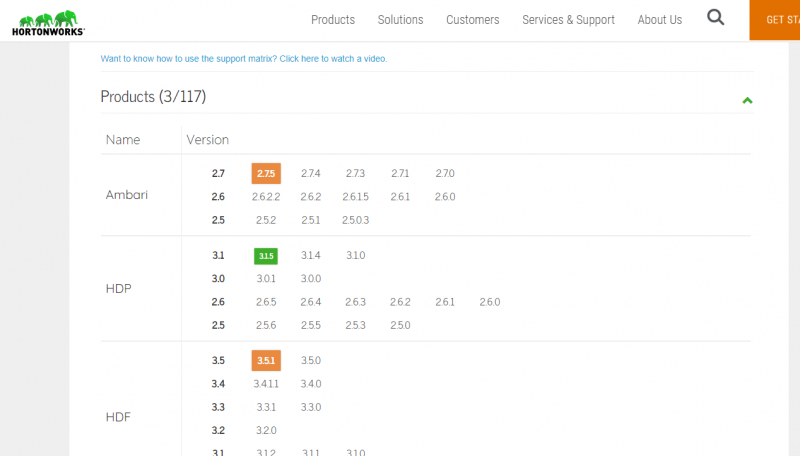
也就是支持最新的版本为HDP 3.1.5 而HDP包含了大数据的基本组件如下:
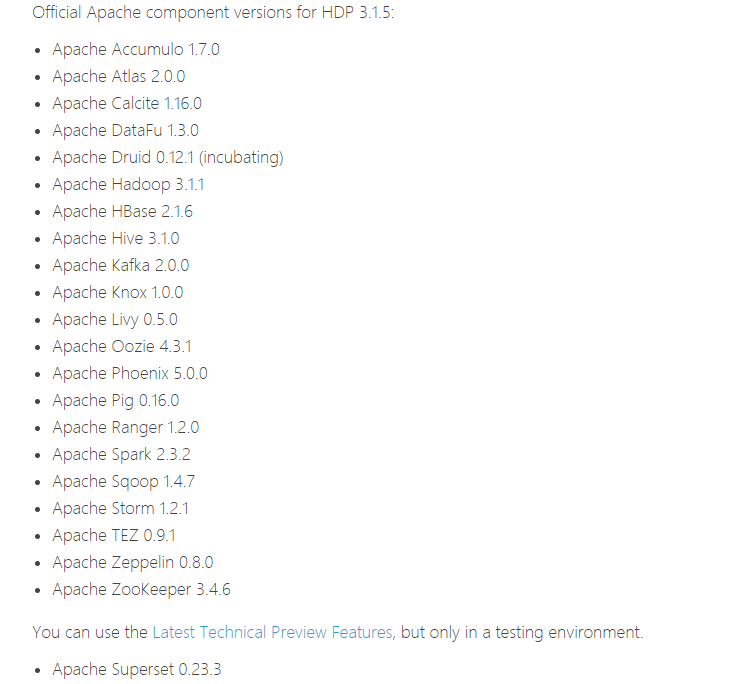
已经非常的丰富了,下面我们开始Ambari的安装。
前期准备
前期准备分为四部分
主机,数据库,浏览器,JDK
主机
请先准备好安装Ambari的主机,开发环境可以三台就ok,其他环境依据公司机器规模而确定。
假设开发环境的三台机器为:
192.168.12.101 master
192.168.12.102 slave1
192.168.12.103 slave2
主机的最低要求如下:
软件要求
在每个主机上:
yum和rpm(RHEL / CentOS / Oracle / Amazon Linux)zypper和php_curl(SLES)apt(Debian / Ubuntu)scp, curl, unzip, tar,wget和gcc*- OpenSSL(v1.01,内部版本16或更高版本)
- Python(带python-devel *)
Ambari主机应至少具有1 GB RAM,并具有500 MB可用空间。
要检查任何主机上的可用内存,请运行:
free -m本地仓库
如果网速不够快,我们可以将包下载下来,建立本地仓库。网速够快可以忽略这步。
先下载安装包

安装httpd服务
yum install yum-utils createrepo[root@master ~]# yum -y install httpd
[root@master ~]# service httpd restart
Redirecting to /bin/systemctl restart httpd.service
[root@master ~]# chkconfig httpd on
随后建立一个本地yum源
mkdir -p /var/www/html/将刚刚下载的包解压到这个目录下。
随后通过浏览器 访问 成功
createrepo ./制作本地源 修改文件里边的源地址
vi ambari.repo
vi hdp.repo
#VERSION_NUMBER=2.7.5.0-72
[ambari-2.7.5.0]
#json.url = http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json
name=ambari Version - ambari-2.7.5.0
baseurl=https://username:password@archive.cloudera.com/p/ambari/centos7/2.x/updates/2.7.5.0
gpgcheck=1
gpgkey=https://username:password@archive.cloudera.com/p/ambari/centos7/2.x/updates/2.7.5.0/RPM-GPG-KEY/RPM-GPG-KEY-Jenkins
enabled=1
priority=1
[root@master ambari]# yum clean all
[root@master ambari]# yum makecache
[root@master ambari]# yum repolist
软件准备
为了方便以后的管理,我们要对机器做一些配置
安装JDK下载地址:http://www.oracle.com/technetwork/java/javase/downloads/jdk8-downloads-2133151.html
rpm -ivh jdk-8u161-linux-x64.rpm
java -version
通过vi /etc/hostname 进行修改机器名 这里主要是为了可以实现通过名称来查找相应的服务器  各个节点修改成相应的名称,分别为master,slave1.slave2
  vi /etc/hosts
192.168.12.101 master
192.168.12.102 slave1
192.168.12.103 slave2
vi /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=master(其他的节点也对应修改)
关闭防火墙[root@master~]#systemctl disable firewalld
[root@master~]#systemctl stop firewalld
ssh免密ssh-keygen
ssh-copy-id -i ~/.ssh/id_rsa.pub remote-host
不同的环境会有不同的问题存在,大家可以参考官网手册进行相应的安装。
安装ambari-server
ambariserver将最终带我们完成大数据集群的安装
yum install ambari-serverInstalling : postgresql-libs-9.2.18-1.el7.x86_64 1/4
Installing : postgresql-9.2.18-1.el7.x86_64 2/4
Installing : postgresql-server-9.2.18-1.el7.x86_64 3/4
Installing : ambari-server-2.7.5.0-124.x86_64 4/4
Verifying : ambari-server-2.7.5.0-124.x86_64 1/4
Verifying : postgresql-9.2.18-1.el7.x86_64 2/4
Verifying : postgresql-server-9.2.18-1.el7.x86_64 3/4
Verifying : postgresql-libs-9.2.18-1.el7.x86_64 4/4
Installed:
ambari-server.x86_64 0:2.7.5.0-72
Dependency Installed:
postgresql.x86_64 0:9.2.18-1.el7
postgresql-libs.x86_64 0:9.2.18-1.el7
postgresql-server.x86_64 0:9.2.18-1.el7
Complete!
启动与设置
设置
ambari-server setup不推荐直接用内嵌的postgresql,因为其他服务还要用mysql
安装配置 MySqlyum install -y wget
wget -i -c http://dev.mysql.com/get/mysql57-community-release-el7-10.noarch.rpm
rpm -ivh mysql57-community-release-el7-10.noarch.rpm
yum -y install mysql-community-server
systemctl enable mysqld
systemctl start mysqld.service
systemctl status mysqld.service
grep "password" /var/log/mysqld.log
mysql -uroot -p
set global validate_password_policy=0;
set global validate_password_length=1;
set global validate_password_special_char_count=0;
set global validate_password_mixed_case_count=0;
set global validate_password_number_count=0;
select @@validate_password_number_count,@@validate_password_mixed_case_count,@@validate_password_number_count,@@validate_password_length;
ALTER USER 'root'@'localhost' IDENTIFIED BY 'password';
grant all privileges on . to 'root'@'%' identified by 'password' with grant option;
flush privileges;
exit
yum -y remove mysql57-community-release-el7-10.noarch
下载mysql驱动,放到三台的
/opt/ambari/mysql-connector-java-5.1.48.jar
初始化数据库
mysql -uroot -p
create database ambari;
use ambari
source /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
CREATE USER 'ambari'@'localhost' IDENTIFIED BY 'bigdata';
CREATE USER 'ambari'@'%' IDENTIFIED BY 'bigdata';
GRANT ALL PRIVILEGES ON ambari.* TO 'ambari'@'localhost';
GRANT ALL PRIVILEGES ON ambari.* TO 'ambari'@'%';
FLUSH PRIVILEGES;
完成ambari的配置
[root@localhost download]# ambari-server setupUsing python /usr/bin/python
Setup ambari-server
Checking SELinux...
SELinux status is 'enabled'
SELinux mode is 'permissive'
WARNING: SELinux is set to 'permissive' mode and temporarily disabled.
OK to continue [y/n] (y)? y
Customize user account for ambari-server daemon [y/n] (n)? y
Enter user account for ambari-server daemon (root):
Adjusting ambari-server permissions and ownership...
Checking firewall status...
Checking JDK...
[1] Oracle JDK 1.8 + Java Cryptography Extension (JCE) Policy Files 8
[2] Custom JDK
==============================================================================
Enter choice (1): 2
WARNING: JDK must be installed on all hosts and JAVA_HOME must be valid on all hosts.
WARNING: JCE Policy files are required for configuring Kerberos security. If you plan to use Kerberos,please make sure JCE Unlimited Strength Jurisdiction Policy Files are valid on all hosts.
Path to JAVA_HOME: /usr/lib/jvm/java-1.8.0-openjdk-1.8.0.242.b08-0.el7_7.x86_64/jre
Validating JDK on Ambari Server...done.
Check JDK version for Ambari Server...
JDK version found: 8
Minimum JDK version is 8 for Ambari. Skipping to setup different JDK for Ambari Server.
Checking GPL software agreement...
GPL License for LZO: https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html
Enable Ambari Server to download and install GPL Licensed LZO packages [y/n] (n)? y
Completing setup...
Configuring database...
Enter advanced database configuration [y/n] (n)? y
Configuring database...
==============================================================================
Choose one of the following options:
[1] - PostgreSQL (Embedded)
[2] - Oracle
[3] - MySQL / MariaDB
[4] - PostgreSQL
[5] - Microsoft SQL Server (Tech Preview)
[6] - SQL Anywhere
[7] - BDB
==============================================================================
Enter choice (1): 3
Hostname (localhost):
Port (3306):
Database name (ambari):
Username (ambari):
Enter Database Password (bigdata):
Configuring ambari database...
Enter full path to custom jdbc driver: /opt/ambari/mysql-connector-java-5.1.48.jar
Copying /opt/ambari/mysql-connector-java-5.1.48.jar to /usr/share/java
Configuring remote database connection properties...
WARNING: Before starting Ambari Server, you must run the following DDL directly from the database shell to create the schema: /var/lib/ambari-server/resources/Ambari-DDL-MySQL-CREATE.sql
Proceed with configuring remote database connection properties [y/n] (y)? y
Extracting system views...
.....
Ambari repo file contains latest json url http://public-repo-1.hortonworks.com/HDP/hdp_urlinfo.json, updating stacks repoinfos with it...
Adjusting ambari-server permissions and ownership...
Ambari Server 'setup' completed successfully.
随后就可以启动了
ambari-server startambari-server status
ambari-server stop
访问如下地址
http://<your.ambari.server>:8080集群安装
接下来进行集群的安装,包括命名,ssh免密,选择版本,规划集群

最终完成集群安装,我们就可以在页面管理我们的集群了。
详细官网安装文档pdf请在关注“实时流式计算” 后台回复ambari
实时计算环境搭建
由于ambari支持的druid版本较低,目前暂不支持flink,所以除kafka外的实时计算组件,需要手动安装,也方便以后的升级。
Linux系统上安装flink
集群安装
集群安装分为以下几步:
1、在每台机器上复制解压出来的flink目录。
2、选择一个作为master节点,然后修改所有机器conf/flink-conf.yaml
jobmanager.rpc.address = master主机名3、修改conf/slaves,将所有work节点写入
work01work02
4、在master上启动集群
bin/start-cluster.sh安装在Hadoop
我们可以选择让Flink运行在Yarn集群上。
下载Flink for Hadoop的包
保证 HADOOP_HOME已经正确设置即可
启动 bin/yarn-session.sh
运行flink示例程序
批处理示例:
提交flink的批处理examples程序:
bin/flink run examples/batch/WordCount.jar这是flink提供的examples下的批处理例子程序,统计单词个数。
$ bin/flink run examples/batch/WordCount.jarStarting execution of program
Executing WordCount example with default input data set.
Use --input to specify file input.
Printing result to stdout. Use --output to specify output path.
(a,5)
(action,1)
(after,1)
(against,1)
(all,2)
(and,12)
(arms,1)
(arrows,1)
(awry,1)
(ay,1)
Druid集群部署
部署建议
集群部署采用的分配如下:
- 主节点部署 Coordinator 和 Overlord进程
- 两个数据节点运行 Historical 和 MiddleManager进程
- 一个查询节点 部署Broker 和 Router进程
未来我们可以添加更多的主节点和查询节点
主节点建议 8vCPU 32GB内存
配置文件位于
conf/druid/cluster/master数据节点建议
16 vCPU 122GB内存 2 * 1.9TB SSD
配置文件位于
conf/druid/cluster/data查询服务器 建议 8vCPU 32GB内存
配置文件位于
conf/druid/cluster/query开始部署
下载最新0.17.0发行版
解压
tar -xzf apache-druid-0.17.0-bin.tar.gzcd apache-druid-0.17.0
集群模式的主要配置文件都位于:
conf/druid/cluster配置元数据存储
conf/druid/cluster/_common/common.runtime.properties替换
druid.metadata.storage.connector.connectURIdruid.metadata.storage.connector.host
例如配置mysql为元数据存储
在mysql中配置好访问权限:
-- create a druid database, make sure to use utf8mb4 as encodingCREATE DATABASE druid DEFAULT CHARACTER SET utf8mb4;
-- create a druid user
CREATE USER 'druid'@'localhost' IDENTIFIED BY 'druid';
-- grant the user all the permissions on the database we just created
GRANT ALL PRIVILEGES ON druid.* TO 'druid'@'localhost';
在druid中配置
druid.extensions.loadList=["mysql-metadata-storage"]druid.metadata.storage.type=mysql
druid.metadata.storage.connector.connectURI=jdbc:mysql://<host>/druid
druid.metadata.storage.connector.user=druid
druid.metadata.storage.connector.password=diurd
配置深度存储
将数据存储配置为S3或者HDFS
比如配置HDFS,修改
conf/druid/cluster/_common/common.runtime.propertiesdruid.extensions.loadList=["druid-hdfs-storage"]#druid.storage.type=local
#druid.storage.storageDirectory=var/druid/segments
druid.storage.type=hdfs
druid.storage.storageDirectory=/druid/segments
#druid.indexer.logs.type=file
#druid.indexer.logs.directory=var/druid/indexing-logs
druid.indexer.logs.type=hdfs
druid.indexer.logs.directory=/druid/indexing-logs
将Hadoop配置XML(core-site.xml,hdfs-site.xml,yarn-site.xml,mapred-site.xml)放在Druid中
conf/druid/cluster/_common/配置zookeeper连接
还是修改
conf/druid/cluster/_common/下的
druid.zk.service.host为zk服务器地址就可以了
启动集群
启动前注意打开端口限制
主节点:
derby 1527
zk 2181
Coordinator 8081
Overlord 8090
数据节点:
Historical 8083
Middle Manager 8091, 8100–8199
查询节点:
Broker 8082
Router 8088
记得将刚才配好的druid复制到各个节点
启动主节点
由于我们使用外部zk 所以使用no-zk启动
bin/start-cluster-master-no-zk-server启动数据服务器
bin/start-cluster-data-server启动查询服务器
bin/start-cluster-query-server这样的话 集群就启动成功了!
至此,我们的大数据环境基本搭建完毕,下一章我们将接入数据,开始进行标签的开发,未完待续~
参考文献
《用户画像:方法论与工程化解决方案》
更多实时数据分析相关博文与科技资讯,欢迎关注 “实时流式计算” 详细ambari官网安装文档pdf请在关注“实时流式计算” 后台回复ambari

以上是 用户画像大数据环境搭建——从零开始搭建实时用户画像(四) 的全部内容, 来源链接: utcz.com/a/19520.html