分布式系统学习笔记2:分布式节点之间的通信技术(1)并发服务技术、RPC 与 RMI 概述
点对点之间的最基本、最底层的方式,是直接基于 TCP 或者 UDP 建立 Socket 连接。这样的连接相当于在两个机器之间建立一个字节流管道。
并发服务技术
服务端同时对多个客户端的请求进行服务,而非串行服务。主流的并发服务实现方法
基于多线程
每来一个请求,就创建一个线程来服务这个请求。多个请求就创建多个线程。该方案的优点是逻辑简单,每个线程内部的逻辑都是一样的,可以一串顺下来。比如先读再解码再跑业务最后编码约定好的返回值,把返回值写回去。
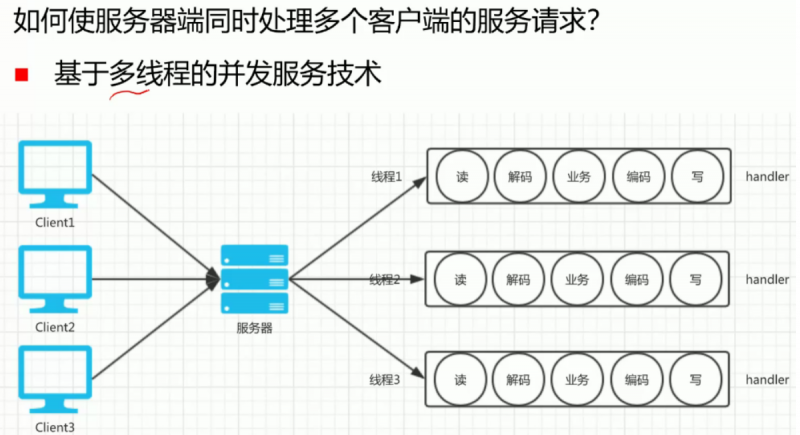
每个线程内部逻辑就是一条线,比较简单。
缺点:
频繁创建、销毁线程,开销较大;
线程过多时切换成本太高
线程池技术。在池子中创建多个休眠的线程,来了请求就唤醒线程(成本低)
基于线程池
在一个池子中创建多个休眠的线程,来了请求就唤醒线程(成本低)
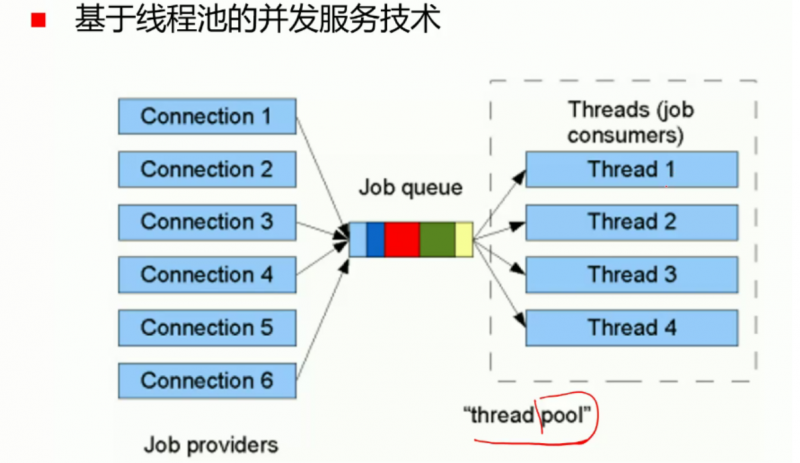
- 避免了进程创建与销毁的开销;
- 可以限制线程数的上限;
- 如果请求过多,队列就炸了(我真的一点也装不下了.jpg)。炸了就说明服务器顶不住了,要用多个服务器来处理客户端的请求了;
- 多个服务器并发处理请求,就叫【负载均衡】——多个服务器并发处理客户端的请求。
达到线程数上限之后,前几个已经来的请求可以由服务端并发服务,但新来的请求就会被放入队列,等待线程池中有空闲线程之后再进行相应。这样可以防止线程过多造成拥塞。
无论是多线程并发服务还是线程池,都存在切换问题,切换过多都会造成较大的开销。
事件驱动技术(多路复用技术)
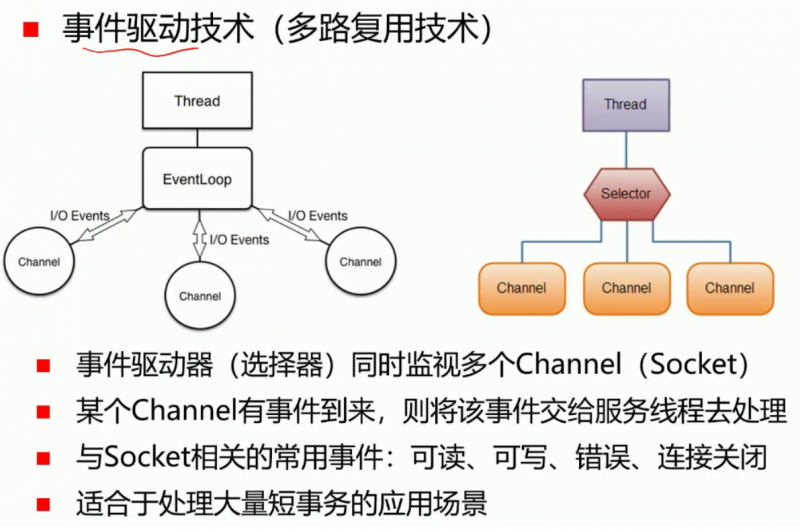
- 在一个(或非常少量的)线程中,串行地处理不同客户端的事件。举个银行的例子:
- 一个只开了两个服务窗口的银行,柜员的服务方式未必是等待服务完一个客户之后再去服务下一个客户(这个是多线程编程思想)
- 其实可以这么搞:看到第一个客户来了,可以先让他去填单子,然后填单子的时候去服务第二个客户。
- 第二个客户做其他事情时,柜员询问第一个客户是否填完了单子,如果填完了就处理,如果没填完就再让第三个客户来。
- 该技术的核心思想,就是把客户端的请求分解成很多的小事件,让这些事件串行处理。
- 用这种处理方式的前提是,我们的业务场景下,对请求的处理和响应是可分解的:
- 比如订单查询:我们发起一个订单查询请求时,负责接受订单查询任务的服务器,就可以把读库的操作发到数据库,之后先去接受其他客户端的请求。等待数据库返回结果之后,再把我们需要的数据返回来。
远程过程调用 RPC
RPC 可以隐藏调用细节,让我们调用服务端子程序的感觉就像调用本地子程序一样

- 对于被调用者而言,其在被调用时也无法分辨该调用来自本地还是远程。
- RPC 将面向过程的通用编程模型扩展到了分布式环境。
- RPC 可以实现跨进程、跨语言、跨网络、跨平台的过程调用。
- gRPC 几乎可以实现所有主流编程语言互相调用
- RPC 强化了【面向接口编程】的编程风格。比如主程序和功能模块可以交给不同的人去做。这不同的人在正式开工之前要定义好接口。开工时就功能模块负责实现接口,主程序调用接口。
- 实现 RPC 必须有 RPC 中间件的支持。上面这几点能做好,都要靠中间件来进行支撑。底层通信细节就由中间件来实现。
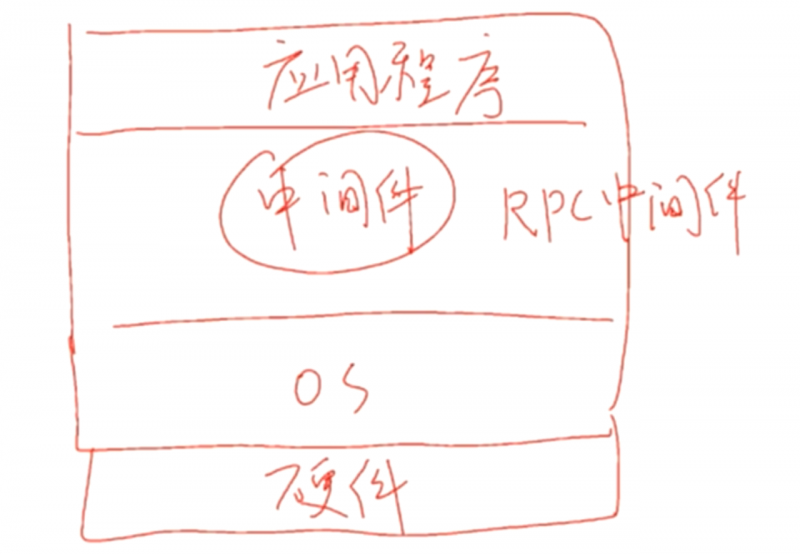
- PRC 中间件依赖 Socket API 实现 RPC
同步调用:会在下个过程进行的时候阻塞等待,返回后才会继续执行。

异步调用:发起调用后会继续执行,中间不进行等待。在一个时间段中两边并行。远程执行完毕时发来通知。
gRPC 支持两种方式。
远程方法调用 RMI
这玩意和 RPC 不是一个东西。RMI 让我们可以像访问本机对象一样来访问远程主机中的对象(读,调用方法),RMI 还支持直接用对象作为参数来调用方法。
与 RPC 需要 RPC 中间件支持一样,RMI 也需要 RMI 中间件的支持。RMI 中间件一般支持整个系统范围内的垃圾回收(系统会不断扫描整个系统中各个主机是否有任何代码在引用某个对象,如果都没有,就回收了)。
RMI 中间件需要实现的东西
RMI 需要使用 Socket 实现调用者与被调用者之间的通信协议(RPC协议);
使用 socket 实现通信协议。通信协议需要包含包格式的设计、交互模式(一问一答,或多问多答等)。需要解决一些怎样通过调用信息(要调用的方法、参数等)来决定具体调谁、怎么返回之类的问题
实现过程参数的序列化、反序列化;运算结果的序列化、反序列化。(序列化可以将一段内存转化为字节流,以便通过 Socket 进行收发);
面向对象中,我们可以定义一个内存对象
比如,Student
这个 Student 对象在内存中的前 4byte 是学号,后面几个 byte 存的是姓名等其他信息
把这样的内存转化为一个字节序列的过程叫做序列化;接收端把这个东西从字节序列恢复成内存对象,就叫做反序列化
这里存在一些问题,并没有【直接读内存把数据编码、接收解码平铺到内存里】那么简单:
编码问题:如果直接用dump,可能会由于异构导致【大端小端】问题、编码方式问题等;
(dump:一般指将数据导出、转存成文件或静态形式。比如可以理解成:把内存某一时刻的内容,dump(转存,导出,保存)成文件)
元数据传递问题:两边的软件使用不同语言编写(比如 C++、Java),这两种语言的对象之间是不兼容的。
(元数据:描述包含对象的那一段内存中该怎么分段、哪一段代表什么)
对象引用问题:比如对象里面有个指针成员,该指针指向了另一个对象。这种【嵌套对象】的情况如何整个实现序列化。
通信过程中的错误处理
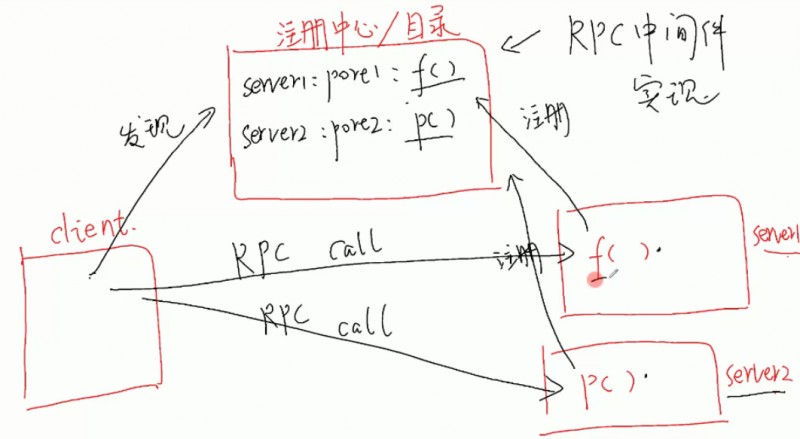
过程服务过程(或远程对象)的集中注册与发现(目录服务)
- 目录服务也可称为【注册中心/目录】
- 为了避免客户端和服务端的紧耦合关系(如果客户端必须知道服务端的地址和接受调用的端口号就叫紧耦合),于是 rpc 搞了一个注册中心,不同的服务器想要暴露的方法都在注册中心进行注册。注册中心记录服务器端点和该服务器暴露的方法的对应关系。
- client 可以在注册中心发现有哪些方法在哪些服务器上,再根据这个信息直接点对点地进行 rpc call。这个注册中心由 rpc 中间件实现
RPC 与 RMI 原理简述
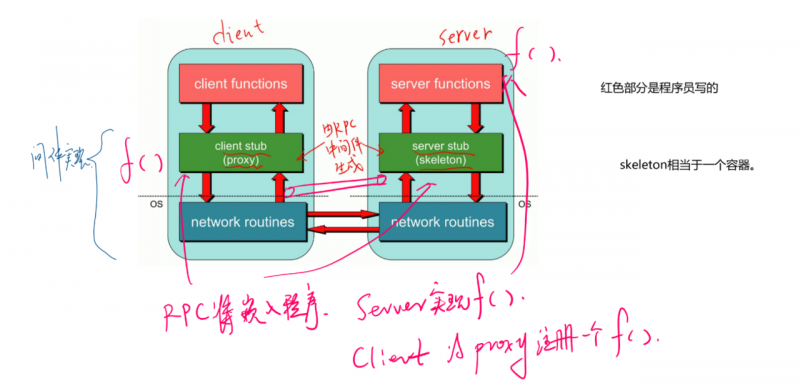
RPC 中间件会在我们的 client 进程中生成叫做 proxy 或者 client stub (存根)的模块。在 server 端生成一个 skeleton。
中间件生成的这两个模块会嵌入到两边的进程空间中。
比如说 服务端生成了一个 f 函数,那 proxy 就也会生成一个 f。当客户端要调用 f 的时候就调用这个 proxy 里面的 f。proxy 中的 f 不实现具体逻辑。
当 client 调用 f 时,proxy 在这里会建立一个连接到服务端的 skeleton 模块 的 socket 连接,并把参数序列化传输给 skeleton 模块。skeleton 模块在 server 内部再扮演调用者的角色,调用 f 函数的实现,f 返回值返回给 skeleton 之后再由 skeleton 通过 socket 发送给调用者,层层返回直到 client 的调用者。
这里的关键,就是两边的 proxy 和 skeleton。skeleton 相当与容器。
上面的图中只有红色部分由开发者编写,两边只关注自己的逻辑即可。其他工作都由中间件来做。
客户端的 stub 并不是预先生成好的,其根据服务端暴露的接口动态生成。它要暴露和两端一模一样的接口,两端命名相同。
JDK 1.5 以后,由于 java 的反射机制日益牛逼,RMI 做到了可以在运行时动态生成客户端 proxy 和服务器的 skeleton
以上是 分布式系统学习笔记2:分布式节点之间的通信技术(1)并发服务技术、RPC 与 RMI 概述 的全部内容, 来源链接: utcz.com/a/19259.html