ShardingSphere源码解析
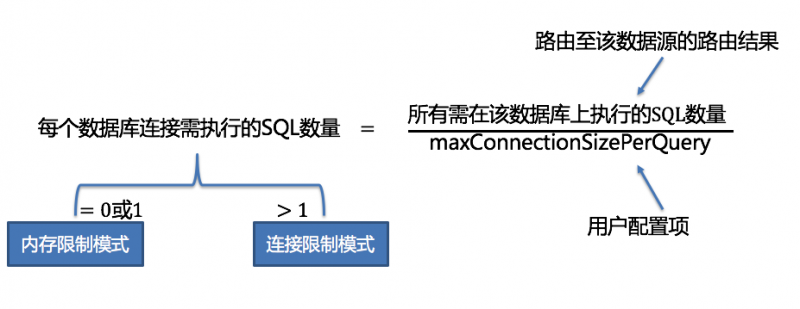
根据官网的介绍,SS去连接数据库的时候有2种模式,一种是内存限制模式,一种是连接限制模式
- 内存限制模式:使用此模式的前提是,ShardingSphere对一次操作所耗费的数据库连接数量不做限制。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,则对每张表创建一个新的数据库连接,并通过多线程的方式并发处理,以达成执行效率最大化。并且在SQL满足条件情况下,优先选择流式归并,以防止出现内存溢出或避免频繁垃圾回收情况。
- 连接限制模式:使用此模式的前提是,ShardingSphere严格控制对一次操作所耗费的数据库连接数量。 如果实际执行的SQL需要对某数据库实例中的200张表做操作,那么只会创建唯一的数据库连接,并对其200张表串行处理。 如果一次操作中的分片散落在不同的数据库,仍然采用多线程处理对不同库的操作,但每个库的每次操作仍然只创建一个唯一的数据库连接。 这样即可以防止对一次请求对数据库连接占用过多所带来的问题。该模式始终选择内存归并。
上面是官网对连接模式的定义,针对每次操作,SS都会自动去选择使用内存限制模式还是连接限制模式,我们可以通过maxConnectionSizePerQuery去配置一次查询时每个数据库所允许使用的最大连接数,如果这里配置的大于1,那么在使用连接限制模式的情况下会采用分组异步去操作数据库,ConnectionSizePerQuery配置了多少就分多少组
1.前面2节分析了sql的解析,路由,改写,现在到了sql执行这一步了,我们回到最初的execute方法中,SS执行引擎分为准备阶段和执行阶段,分别对应initPreparedStatementExecutor()和preparedStatementExecutor.execute(),下面进入initPreparedStatementExecutor方法
publicbooleanexecute()throws SQLException {try {
clearPrevious();
prepare();
initPreparedStatementExecutor();
return preparedStatementExecutor.execute();
} finally {
clearBatch();
}
}
2.PreparedStatementExecutor#init方法,executionContext参数是我们在sql改写完成之后实例化出来的对象,里面包含的属性包含sqlStatementContext和sql执行单元
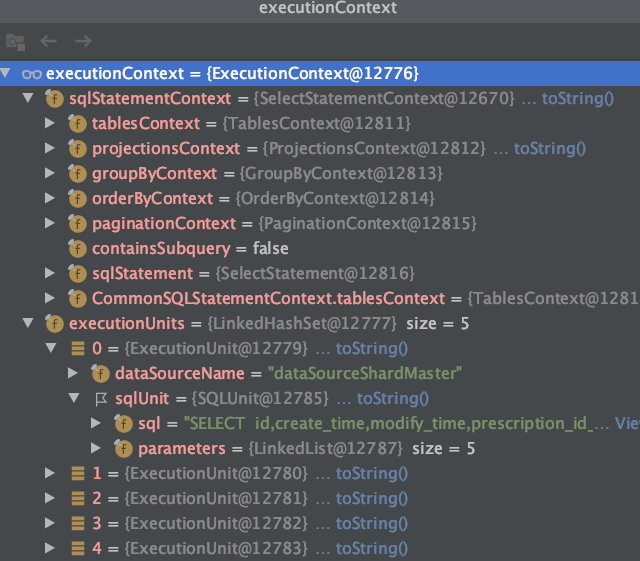
然后我们关注obtainExecuteGroups方法,这个方法里实现了执行分组
publicvoidinit(final ExecutionContext executionContext)throws SQLException {setSqlStatementContext(executionContext.getSqlStatementContext());
getInputGroups().addAll(obtainExecuteGroups(executionContext.getExecutionUnits()));
cacheStatements();
}
3.这里创建了一个回调,SQLExecutePrepareCallback包含2个方法,getConnections获取数据库连接集合,createStatementExecuteUnit创建sql执行单元,留个印象,现在我们还不知道他的具体用法,继续往后看
private Collection<InputGroup<StatementExecuteUnit>> obtainExecuteGroups(final Collection<ExecutionUnit> executionUnits) throws SQLException {return getSqlExecutePrepareTemplate().getExecuteUnitGroups(executionUnits, new SQLExecutePrepareCallback() {
@Override
public List<Connection> getConnections(final ConnectionMode connectionMode, final String dataSourceName, finalint connectionSize)throws SQLException {
return PreparedStatementExecutor.super.getConnection().getConnections(connectionMode, dataSourceName, connectionSize);
}
@Override
public StatementExecuteUnit createStatementExecuteUnit(final Connection connection, final ExecutionUnit executionUnit, final ConnectionMode connectionMode)throws SQLException {
returnnew StatementExecuteUnit(executionUnit, createPreparedStatement(connection, executionUnit.getSqlUnit().getSql()), connectionMode);
}
});
}
4.getSQLUnitGroups方法以数据源分组,把相同数据源的执行单元放到同一个组下,然后进入getSQLExecuteGroups,这里选择了连接模式
private Collection<InputGroup<StatementExecuteUnit>> getSynchronizedExecuteUnitGroups(final Collection<ExecutionUnit> executionUnits, final SQLExecutePrepareCallback callback) throws SQLException {
Map<String, List<SQLUnit>> sqlUnitGroups = getSQLUnitGroups(executionUnits);
Collection<InputGroup<StatementExecuteUnit>> result = new LinkedList<>();
for (Entry<String, List<SQLUnit>> entry : sqlUnitGroups.entrySet()) {
result.addAll(getSQLExecuteGroups(entry.getKey(), entry.getValue(), callback));
}
return result;
}
5.我现在需要执行的sql数量为5,配置的maxConnectionsSizePerQuery=3,计算desiredPartitionSize=2
private List<InputGroup<StatementExecuteUnit>> getSQLExecuteGroups(final String dataSourceName,final List<SQLUnit> sqlUnits, final SQLExecutePrepareCallback callback) throws SQLException {
List<InputGroup<StatementExecuteUnit>> result = new LinkedList<>();
int desiredPartitionSize = Math.max(0 == sqlUnits.size() % maxConnectionsSizePerQuery ? sqlUnits.size() / maxConnectionsSizePerQuery : sqlUnits.size() / maxConnectionsSizePerQuery + 1, 1);
List<List<SQLUnit>> sqlUnitPartitions = Lists.partition(sqlUnits, desiredPartitionSize);
ConnectionMode connectionMode = maxConnectionsSizePerQuery < sqlUnits.size() ? ConnectionMode.CONNECTION_STRICTLY : ConnectionMode.MEMORY_STRICTLY;
List<Connection> connections = callback.getConnections(connectionMode, dataSourceName, sqlUnitPartitions.size());
int count = 0;
for (List<SQLUnit> each : sqlUnitPartitions) {
result.add(getSQLExecuteGroup(connectionMode, connections.get(count++), dataSourceName, each, callback));
}
return result;
}
5.1 sqlUnitPartitions是根据执行的sql数量和desiredPartitionSize来给sql分组,按照上面的数据,下图展示了分组情况,分了3组,3代表了需要获取3个数据库连接

5.2 ConnectionMode计算方式如下图,我们现在sql数量5 大于 maxConnectionsSizePerQuery,所以这次的查询为连接限制模式(CONNECTION_STRICTLY)
6 通过callback的getConnection方法去获取连接,PreparedStatementExecutor.super.getConnection()获取到的是ShardingConnection,具体执行getConnections是父类AbstractConnectionAdapter中执行的
public List<Connection> getConnections(final ConnectionMode connectionMode, final String dataSourceName, finalint connectionSize)throws SQLException {return PreparedStatementExecutor.super.getConnection().getConnections(connectionMode, dataSourceName, connectionSize);
}
7.cachedConnections是一个LinkedHashMultimap对象,先判断map中有没有目标数据源的connection,如果没有那么先创建,看下createConnections方法
publicfinal List<Connection> getConnections(final ConnectionMode connectionMode, final String dataSourceName, finalint connectionSize)throws SQLException {DataSource dataSource = getDataSourceMap().get(dataSourceName);
Preconditions.checkState(null != dataSource, "Missing the data source name: '%s'", dataSourceName);
Collection<Connection> connections;
synchronized (cachedConnections) {
connections = cachedConnections.get(dataSourceName);
}
List<Connection> result;
if (connections.size() >= connectionSize) {
result = new ArrayList<>(connections).subList(0, connectionSize);
} elseif (!connections.isEmpty()) {
result = new ArrayList<>(connectionSize);
result.addAll(connections);
List<Connection> newConnections = createConnections(dataSourceName, connectionMode, dataSource, connectionSize - connections.size());
result.addAll(newConnections);
synchronized (cachedConnections) {
cachedConnections.putAll(dataSourceName, newConnections);
}
} else {
result = new ArrayList<>(createConnections(dataSourceName, connectionMode, dataSource, connectionSize));
synchronized (cachedConnections) {
cachedConnections.putAll(dataSourceName, result);
}
}
return result;
}
8.AbstractConnectionAdapter#createConnections()中,对于获取连接做了一点优化,如果是内存限制模式则需要同步去创建connection,因为可能会发生死锁,所以需要同步
if (ConnectionMode.CONNECTION_STRICTLY == connectionMode) {return createConnections(dataSourceName, dataSource, connectionSize);
}
synchronized (dataSource) {
return createConnections(dataSourceName, dataSource, connectionSize);
}
9.创建connection的是在AbstractConnectionAdapter#createConnections()中,createConnection方式是一个抽象方法,实现方法在子类ShardingConnection#createConnection中,判断是否需要连接是否需要事物,如果不需要直接通过datasource.getConnection创建连接,如果需要事物则通过shardingTransactionManager去创建连接
private List<Connection> createConnections(final String dataSourceName, final DataSource dataSource, finalint connectionSize)throws SQLException {List<Connection> result = new ArrayList<>(connectionSize);
for (int i = 0; i < connectionSize; i++) {
try {
Connection connection = createConnection(dataSourceName, dataSource);
replayMethodsInvocation(connection);
result.add(connection);
...
10.创建完connections,会通过线程安全的方式放入cachedConnections中,现在再回到SQLExecutePrepareTemplate#getSQLExecuteGroups中,getSQLExecuteGroup方法中取创建最终的执行单元
for (List<SQLUnit> each : sqlUnitPartitions) {result.add(getSQLExecuteGroup(connectionMode, connections.get(count++), dataSourceName, each, callback));
}
11.sqlUnitGroup是我们之前分组得到的每个connection中需要执行的sql的组数,我们测试场景下这里的sqlUnitGroup size是2,每个连接需要执行2次sql,调用callback的createStatementExecuteUnit创建执行单元
private InputGroup<StatementExecuteUnit> getSQLExecuteGroup(final ConnectionMode connectionMode, final Connection connection,final String dataSourceName, final List<SQLUnit> sqlUnitGroup, final SQLExecutePrepareCallback callback)
throws SQLException {List<StatementExecuteUnit> result = new LinkedList<>();
for (SQLUnit each : sqlUnitGroup) {
result.add(callback.createStatementExecuteUnit(connection, new ExecutionUnit(dataSourceName, each), connectionMode));
}
returnnew InputGroup<>(result);
}
12.最终在PreparedStatementExecutor#createPreparedStatement方法通过connection.prepareStatement来得到PreparedStatement,之后返回InputGroup StatementExecuteUnit
private PreparedStatement createPreparedStatement(final Connection connection, final String sql)throws SQLException {return returnGeneratedKeys ? connection.prepareStatement(sql, Statement.RETURN_GENERATED_KEYS)
: connection.prepareStatement(sql, getResultSetType(), getResultSetConcurrency(), getResultSetHoldability());
}
13.回到PreparedStatementExecutor#init中,现在inputGroups对象已经准备好了,然后在ShardingPreparedStatement#initPreparedStatementExecutor中,通过setParametersForStatements,replayMethodForStatements完成相关参数和属性设置
publicvoidinit(final ExecutionContext executionContext)throws SQLException {setSqlStatementContext(executionContext.getSqlStatementContext());
getInputGroups().addAll(obtainExecuteGroups(executionContext.getExecutionUnits()));
cacheStatements();
}
SQL执行准备阶段这里就结束了,接下来我们进入SQL执行的执行阶段
以上是 ShardingSphere源码解析 的全部内容, 来源链接: utcz.com/a/19235.html