Uber因果推断

在 Uber Labs,我们的任务是利用行为科学的洞察力和方法论来帮助产品和市场团队改善客户体验。 最近,我们引入了中介模型来解决用户的痛点,它是一种来自学术研究的统计方法。
为了理解导致结果的潜在机制,中介模型超越了简单的因果关系。 使用这种类型的分析,我们可以从微调或开发产品的变化中找到优步平台上功能成功背后的基本机制。
知其然 vs 知其所以然
在 Uber,我们有一个强大的改进文化,通过频繁开展实验来测试一个变量是否会影响另一个变量,以确保可靠、安全和无缝的用户体验。
大多数时候,我们对为什么两个变量是相关的有一个假设。 例如,假设我们相信在新乘客的前几次旅行中给予他们行程折扣的促销活动可以提高新乘客的留存率。虽然一个标准的分析会告诉我们这种促销是否有助于增加新的骑手留存,但是它不会告诉我们为什么。 例如,新乘客是否会在前几次行程后因为行程费用降低而重新使用该应用程序? 或者是促销帮助新乘客熟悉了这个应用程序,或者完全是别的什么? 如果存在多种机制,哪一种机制发挥更大的作用,作用大小如何? 在一个标准的分析中,一个潜在的机制(例如,为什么会发生这样的事情)通常被认为是存在的,但是没有用数据进行实证检验。
虽然我们可能有一些证据表明两个变量是相关的,但我们可能不清楚为什么它们是相关的,当我们不明白为什么,我们不得不依赖于试验和错误。 然而,就像在学术研究中一样,知道为什么对 Uber 同样重要,因为它帮助我们为用户打造更好的产品。 例如,在上面的例子中,如果我们发现他们对应用程序的熟悉使新的乘客留在了平台上,那么我们应该优先考虑鼓励乘客使用应用程序的新的产品功能。
中介模型: 打开黑匣子
中介模型打开了实验和结果变量之间的黑匣子,从而揭示了潜在的机制,即为什么会发生某些事情。当我们有一个因果假设,而不是让它停留在那里或依赖于相关证据,中介模型让我们经验性地检验(与逻辑推断)两个变量之间的因果路径。 更重要的是,理解这些机制使我们能够更快更有效地开发出更好的产品,因为它有助于我们确定这些变化的哪些特征是使产品成功的原因。
那么,我们究竟可以通过中介建模做些什么来改善用户体验呢? 我们在下面的图1中概述了一些假设的用例:
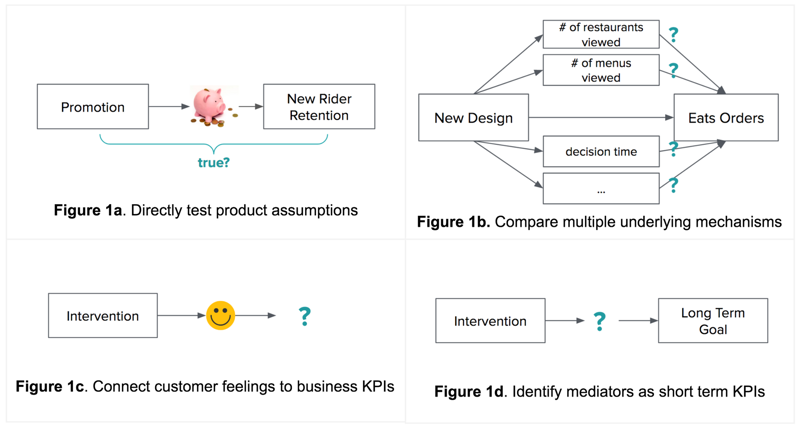
首先,我们可以使用中介建模来测试产品假设。 例如,我们可能认为,一个新的附加促销可以增加保留,因为减少旅行费用(图1a)。 通过中介建模,我们可以对这一假设进行实证检验。 我们的这些测试结果可以告诉我们我们的假设是否正确,如果正确,有多少影响是由于旅行费用的减少而不是其他机制(例如,熟悉应用程序)。
其次,我们可以使用中介建模来比较多种机制。 在一个假设的例子中,我们可能认为 Uber Eats 菜单的新设计可以通过多种机制增加订单(图1b)。 通过中介建模,我们能够估计这些机制中的每一个对实验效果(即增加订单)的影响程度,以及哪种机制发挥了最大的作用。 这些结果有助于告知我们如何设计我们的产品及其未来的迭代。
中介建模还允许我们将无形变量(如消费者情绪)与特定特性联系到业务指标。 众所周知,顾客的感受和满意度对于企业的成功至关重要。 然而,通常很难量化它们对业务的影响。 然而,中介建模使我们能够测试这些变量如何影响下游业务指标(例如,如图1c 所示的附加引用)。
此外,中介建模可以是将长期目标分解为更小的中间步骤的一种创造性方法。 例如,假设我们的目标是提高长期乘客对 Uber 的满意度。 我们如何将这个目标分解成更小的部分,并与我们的日常工作联系起来? 如果我们之前已经确定了骑手满意度背后的关键中介,那么我们就可以利用这个中介作为短期关键绩效指标(KPI)(图1 d)。 如果干预的大部分效果是通过某一特定机制引起的,那么影响该关键调解人可能是干预发挥作用的一个必要(虽然不是充分)条件。
在不同的用例中,我们识别上游或下游变量并测试它们之间的连接方式。 接下来,我们将进一步讨论这个解释,并讨论中介建模背后的概念细节。
中介模型 VS 因果推断
为了成功地执行这项技术,我们究竟需要用几个什么样的方法呢? 为了回答这些问题,我们在下面的图2中描述了最简单的中介模型:
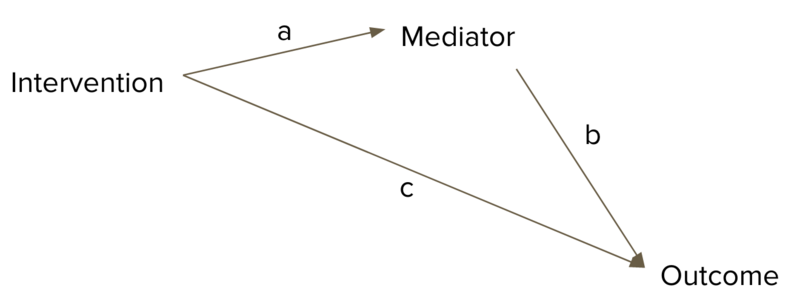
图2. 中介建模的概念框架包含了干预、中介和最终的结果
根据这种类型的模型,我们的目标是估计三个关键数量:
- 平均直接效应(ADE) :c
- 平均因果调节效应(ACME) :ab
- 平均总效应(ATE) : ab + c
近年来,研究人员已经开始理解中介模型的因果关系。这使他们能够使用为因果推断开发的正式框架将中介概念化,如由 Neyman,Rubin 和其他人开发的潜在结果方法。
为了更好地理解这个框架是如何运作的,假设我们有一个结果 y 和实验分配 t,如果一个人在实验组中 t 是1,如果一个人在对照组中 t 是0。 然后,实验分配下个体 i 的结果 y 是 Yi (t)。
现在,我们经常感兴趣的是估计实验和控制之间 y 的差异,对于个体 i
$$Yi(1)−Yi(0)$$
然而,大多数时候我们只观察到这两种结果中的一种,因为一个人通常只处于一种实验状态。 例如,如果个体 i 处于治疗状态(t1) ,那么个体的结果 Yi (0)只是一个潜在的结果,也就是说,一个可能发生但实际上没有发生的结果。
由于我们通常不能观察治疗效果在个人水平,我们估计的群体水平的平均治疗效果,这是定义为
$$E[Y_i(1)−Y_i(0)]$$
在这里,处理和控制分配的结果 y 是估计从组水平的数量。
所有这些与中介建模有什么关系? 事实证明,我们可以用上面的框架来表示三个关键的中介量。 设 m (t)对应于实验分配下的潜在介质值 t,那么,我们可以开始定义关键的介质量如下:
$$ATE=E[Y_i(1,M_i(1))−Y_i(0,M_i(0))]$$
简而言之,ATE 是实验下的潜在结果和控制分配之间的差异,当中介变化,因为它实际上与实验分配。 这解决了实验对结果的平均影响。
如前所述,中介建模的目标是将总体实验效应分解为两部分: 平均直接效应(ADE)和平均因果中介效应(ACME)。 换句话说,ADE 是实验对结果的影响,不需要经过中介变量。 因此,如果您在改变处理状态的值的同时确定中介的值,那么您将生成直接效果。 使用潜在的结果符号,我们有
$$ ADE=E[Y_i(1,M_i(t))−Y_i(0,M_i(t)) ]$$
对于 t=0, 因此,ADE 可以理解为一旦我们阻止中介变量改变实验状态,实验分配对结果的任何额外贡献。 我们使用统计模型来估计,如果中介变量是固定的,结果会是什么。)
一旦我们建立了 ADE,很明显 ACME 只是它的补充:
$$ACME=E[Y_i(t,M_i(1))−Y_i(t,M_i(0))]$$
对于 t=0, Acme 对应于潜在结果的差异,如果我们将中介变量翻转为在实验状态下它将采取的值,同时保持实验状态本身固定,将会看到这种差异。
这些定义的优点之一是它们没有提到任何特定的模型。 因此,像 Imai 等研究人员。 已经开发了使用任何有效模型估计关键中介量的算法。 这意味着,除了其他事情之外,我们可以自由地使用非参数和非线性模型来估计中介图中的关系,与过去相比,这是一个相当大的进步。例如,在传统的方法中,如 Hayes’ PROCESS 方法,中介不能是分类变量,结果变量仅限于那些可以用一般最小平方法或回归方法适当建模的变量。 过程方法对中介变量和结果变量的限制不允许我们建立离散数据模型,这使得它不适合我们在 Uber 的工作。
最后,潜在结果框架证明有助于确定中介效应的识别假设。 在随机实验的背景下,主要的假设是中介变量应该在统计上独立于 y 的潜在结果,条件是观察到的实验状态和模型中包含的预处理协变量的值。
尽管潜在结果框架有助于我们清楚地定义这一假设,但不可能最终验证这一假设是否成立。 我们能做的最好的是(1)包括任何预处理协变量,理论上的考虑建议可以去混淆介质和结果之间的关系和(2)进行敏感性分析,看看我们的估计将如何变化,如果我们的假设不满足不同程度。幸运的是,作为一个数据驱动的技术公司,我们通常有一个良好的预处理协变量集,我们可以使用在我们的模型,以减轻混淆的风险。
应用示例: 用户工单处理
现在,让我们来看一个具体的例子,通过最近对我们的顾客至上团队的分析,我们如何在 Uber 中应用中介模型。 我们想知道,如果增加一个显示司机收入的图表,是否会导致更少的支持工单。 为了帮助用户提交更少的支持工单,我们需要了解他们为什么首先要提交工单。
在之前的一个实验中,顾客至上团队发现,添加一个显示司机-合伙人每周收入的图表,显著增加了他们对自己收入的理解。 图3,下面,显示了实验组和控制组的 UI:

图3. 实验和控制盈利标签视图为我们的用户提供了略有不同的界面
在这个分析中,收益理解是通过一个单项调查来衡量的,这个调查询问了司机们对他们收益信息的理解程度,以5分为单位。
我们想知道收入理解是否是收入相关支持工单背后的一个重要的行为机制。 换句话说,我们想知道是否实验提高了对收入的理解,从而减少了支持票。 如果是这样的话,我们还想估计有多少实验效果是通过盈利理解的途径(而不是其他机制)来调节的。
为了回答这些问题,我们使用了以干预为独立变量的中介建模,以盈利理解为中介,以与盈利相关的支持票作为结果变量(图4)。 此外,我们还将驾驶员的实验前支持票和实验前收入经验(例如,以前的收入,终身旅行和活跃天数)作为控制变量。 我们通过运行一个敏感度分析以确定我们的结果对于未经测量的中介变量-结果混杂因素的强大程度。
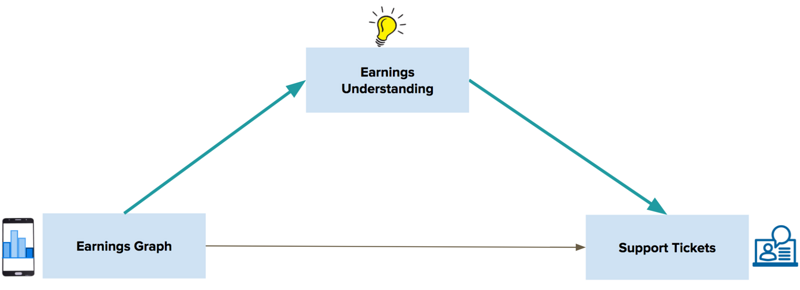
图4. 中介建模测试与收益相关的支持工单背后的基本机制
中介模型结果表明,收入理解确实是收入相关支持工单背后的一个重要机制,约占总实验效果的19% 。 基于这些结果,我们更好地理解了为什么盈利理解是减少客户支持工单的一个重要途径。
有了这些见解,我们可以更好地设计产品和沟通,提高司机对其收入的理解,从而使用户体验更加无缝和愉快。 与此同时,我们也意识到我们的团队有很大的机会进一步利用模型来揭示其余81% 影响的中介机制。 为了实现这一点,我们正在与顾客至上团队合作,测试更多剩余的行为机制。 这些结果将推进收益产品路线图的规划。
中介模型的未来
中介模型的未来是令人兴奋的: 近年来,学术研究人员已经开始研究使用高维数据进行自动中介变量选择。在这些应用中,我们可以指定潜在的数百个中介变量,它们在实验和结果之间是暂时的。 然后我们测试治疗和每个候选中介变量之间或者每个候选中介变量和结果变量之间是否存在统计学上可靠的联系。 有了这些方法,我们就有可能在前所未有的细节上揭开实验-结果关系的黑匣子。
在 Uber,我们期待测试这些数据驱动的算法,看看它们与传统的理论驱动方法相比如何。研究人员在进行研究之前,通过传统的理论驱动方法指定介质。 我们认为中介建模是另一个有趣的领域,在这里使用机器学习方法来分析实验具有很大的潜力。
如果你有兴趣利用应用行为科学为产品和城市提供动力,可以到 Uber Labs了解工作机会。
以上是 Uber因果推断 的全部内容, 来源链接: utcz.com/a/19132.html