LevelDB Filter
Bloom Filter
LevelDB 可以设置通过 bloom filter 来减少不必要的读 I/O 次数。
1970 年,Burton Howard Bloom 在论文 Space/Time Trade-offs in Hash Coding with Allowable Errors 提出了 bloom filter。
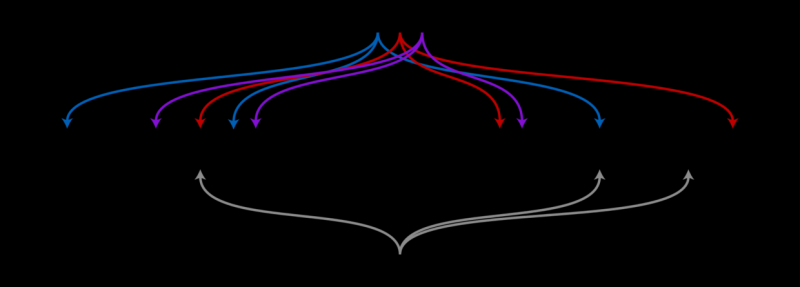
Bloom filter 的实现一般由一个或多个 bitmap 和多个哈希函数组成,可以用于检索一个元素是否在一个集合中。
- 优点是空间效率高、查询时间是常数复杂度,并且和每个 key 的长度无关。
- 缺点是有一定的误识别率(false positive,通常平均每个元素只需要不到 10 bits 的空间就能把错误率控制在 1% 左右),同时不支持删除操作。
- 关于删除操作,也许有人会想把 bitmap 变成整数数组,然后每插入一个元素就把对应的计数器加 1,删除元素时将计数器减掉就可以了。这样做有两个问题:
- 消耗的内存大大增加。如果使用 uint8 的整数数组,内存是原来的 8 倍,并且最大只能计数到 255。而使用 uint16、uint32 会消耗更多的内存。
- 要保证安全地删除元素,首先我们必须保证删除的元素的确在 bloom filter 中。这一点单凭这个过滤器是无法保证的。
假设 m 为 bitmap 的长度,n 是元素的总数,k 是哈希函数的个数,则平均每个 key 消耗的内存 bits_per_key = m / n。
对于给定的 bits_per_key,要使误识别率最低,则 k 的取值为 bits_per_key * ln2。
如果我们希望误识别率为 e,则
比如当 e = 0.01 时,可以通过公式简单计算得到 bits_per_key ~= 9.567。也就是说,一个 key 消耗不到 10 bits 就能将误识别率控制在 1% 左右。
具体的数学推导过程可以参考 bloom filter 的维基百科。
实现
LevelDB 中的 bloom filter 的实现是 BloomFilterPolicy,它继承了 FilterPolicy 抽象类,实现了两个接口:
- CreateFilter - 根据 key 列表创建 filter。
- KeyMayMatch - 判断一个 key 是否可能存在。如果 key 存在,一定返回 true。如果 key 不存在,可能返回 true 也可能返回 false。
以上是 LevelDB Filter 的全部内容, 来源链接: utcz.com/a/18781.html