Mybatis XMLStatementBuilder工作原理
负责解析CRUD元素的XMLStatementBuilder对象的工作原理
前言
本篇文章主要负责介绍XMLStatementBuilder对象的相关内容,XMLStatementBuilder对象的实现说难不难,说简单也不简单,在这篇文章中,我们可能会回顾很多之前学过的内容,这样做的目的一方面是为了保持阅读的连贯性,另一方面也是为了加深对前面学习过的内容的印象.
XMLStatementBuilder的用途和效果
单纯从效果上来看,XMLStatementBuilder对象的作用是将用户的CRUD配置解析成相对应的MappedStatement对象.
关于MappedStatement对象,我们在前面的文章中虽然稍有提及,但是基本没做什么介绍,现在,我们先通过一张图来简单了解一下MappedStatement对象,以便于进行后面的内容,更多关于MappedStatement对象的细节,在后面我们再慢慢补充进来:
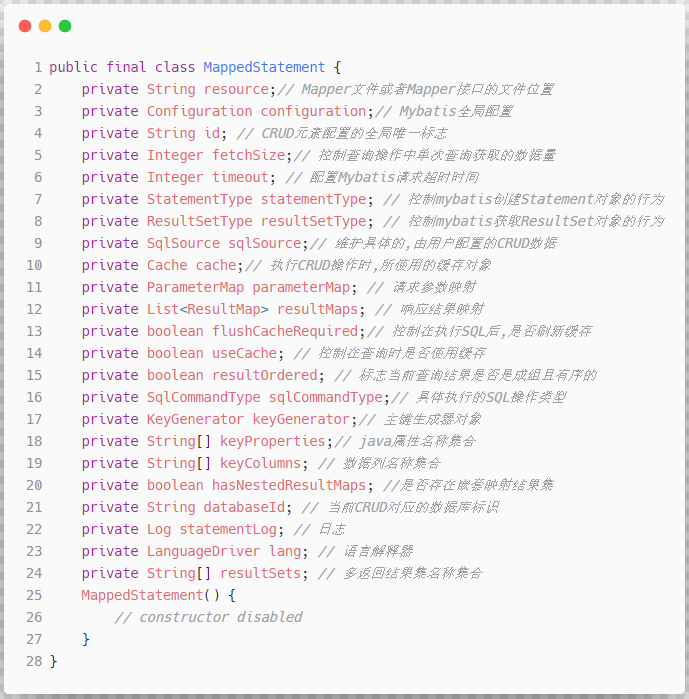
强烈建议认真观看上图中每一个属性的定义和描述信息,在真正了解了这些属性定义之后,接下来的学习过程就会非常容易理解了.
通过前面文章的学习,实际上我们已经接触了上图中涉及到的绝大多数属性,剩余的极个别属性,我们接下来会进行详细的探究.
理论上来讲XMLStatementBuilder对象将CURD元素转换成MappedStatement对象的过程,主要就是获取上述属性并进行处理的过程.
所以,无论XMLStatementBuilder对象parseStatementNode()方法看起来有多复杂,实质上都是简单的属性取值操作.

我们先总体看一下parseStatementNode()方法,然后再去细致的进行分析:
/*** 完成指定Statement的解析操作
*/
publicvoidparseStatementNode(){
// step1: 基础属性的取值操作
// 获取声明语句的唯一标志
String id = context.getStringAttribute("id");
// 获取对应的数据库唯一标志
String databaseId = context.getStringAttribute("databaseId");
// 校验数据库类型是否匹配
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
// 如果数据库类型不一致,跳过处理
return;
}
// 获取内容的大小限制
Integer fetchSize = context.getIntAttribute("fetchSize");
// 超时时间
Integer timeout = context.getIntAttribute("timeout");
// 参数映射
String parameterMap = context.getStringAttribute("parameterMap");
// 参数类型
String parameterType = context.getStringAttribute("parameterType");
// 解析参数类
Class<?> parameterTypeClass = resolveClass(parameterType);
// 响应映射
String resultMap = context.getStringAttribute("resultMap");
// 响应类型
String resultType = context.getStringAttribute("resultType");
// 语言类型
String lang = context.getStringAttribute("lang");
// 获取语言驱动
LanguageDriver langDriver = getLanguageDriver(lang);
// 解析响应类类型
Class<?> resultTypeClass = resolveClass(resultType);
// 解析不可重复响应集合
String resultSetType = context.getStringAttribute("resultSetType");
// 解析语句的声明类型,mybatis目前支持三种,prepare、硬编码、以及存储过程调用
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 解析响应集合类型
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
String nodeName = context.getNode().getNodeName();
// 根据节点的名称获取SQL语句类型
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
// 判断是否为查询语句
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
// 是否刷新缓存,非查询语句(insert|update|delete)才会刷新缓存
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
// 是否应用缓存,查询语句(select)才会应用缓存
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
// 查询结果是否有序且成组
boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
// step2: 特殊元素的解析操作
// 解析内部的Include标签
// Include Fragments before parsing
XMLIncludeTransformer includeParser = new XMLIncludeTransformer(configuration, builderAssistant);
// 解析并处理include标签
includeParser.applyIncludes(context.getNode());
// 解析select声明语句的selectKey内容
// Parse selectKey after includes and remove them.
processSelectKeyNodes(id, parameterTypeClass, langDriver);
// 解析SQL内容
// Parse the SQL (pre: <selectKey> and <include> were parsed and removed)
SqlSource sqlSource = langDriver.createSqlSource(configuration, context, parameterTypeClass);
// 获取select声明语句的resultSets属性声明
String resultSets = context.getStringAttribute("resultSets");
// 获取update声明语句的resultSets属性声明
String keyProperty = context.getStringAttribute("keyProperty");
// 获取insert声明语句的keyColumn属性声明
String keyColumn = context.getStringAttribute("keyColumn");
// 配置主键生成器
KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
// 合并命名空间
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
// 获取主键生成器
if (configuration.hasKeyGenerator(keyStatementId)) {
// 已有直接获取
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
// 没有则生成
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
// step3: MappedStatement对象的构建工作
// 构建整体配置
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
}
我将上述代码实现按照执行顺序,大致分为了三部分,第一部分是基础属性的取值操作,第二部分是子元素的解析操作,第三部分则是MappedStatement对象的构建工作.
现在,我们就按照顺序一一来探究这三部分的实现.
基础属性的取值操作
首先是基础属性的取值操作,这一部分基本就是简单的属性获取操作,整体来说可能相对比较枯燥,但是我建议还是要认真的看一遍,加深印象.
同时,为了加深对这些属性的理解和记忆,我会在其中穿插着描述每个属性的作用.
id属性
// 获取声明语句的唯一标志String id = context.getStringAttribute("id");
首当其冲的id属性,在select,insert,update以及delete四个元素中都有相应的定义.
id属性的取值要和Mapper接口中的方法名称一一对应,同时鉴于mybatis不支持Mapper接口中的重载方法,因此在同一个Mapper中,针对CRUD四种元素配置,id属性的取值应该是唯一的.
databaseId属性的获取和校验
// 获取对应的数据库唯一标志String databaseId = context.getStringAttribute("databaseId");
// 校验数据库类型是否匹配
if (!databaseIdMatchesCurrent(id, databaseId, this.requiredDatabaseId)) {
// 如果数据库类型不一致,跳过处理
return;
}
databaseId属性同样在select,insert,update以及delete四个元素中都有定义,他的作用是为当前映射语句配置指定数据库类型.
借助于DatabaseIdProvider和映射语句中配置的databaseId属性,mybatis可以在运行时根据数据源的不同来执行不同的SQL语句。
下面是mybatis筛选生效语句的逻辑:
MyBatis会加载带有匹配当前数据库的databaseId属性的语句和所有不带databaseId属性的语句。 如果同时找到带有
databaseId和不带databaseId的相同语句,则后者会被舍弃。
fetchSize属性
// 获取内容的大小限制Integer fetchSize = context.getIntAttribute("fetchSize");
fetchSize属性只存在于select元素中,该属性用于控制JDBC批量获取数据时,每次加载数据的行数,fetchSize的取值取决于具体的数据库驱动,比如:oracle数据库的默认值为10.
我们可以通过调整fetchSize的值来控制数据库每次加载的数据量,进而手动控制查询时间和内存空间的阈值.
timeout属性
// 超时时间Integer timeout = context.getIntAttribute("timeout");
timeout属性同样在select,insert,update以及delete四个元素中都有定义,它用于配置JDBC中Statement对象的请求超时时间,单位为秒.
在未抛出异常的前提下,每次数据库操作,jdbc驱动都会等待指定timeout时长.
parameterMap属性
// 参数映射String parameterMap = context.getStringAttribute("parameterMap");
parameterMap属性在select,insert,update以及delete四个元素中都有定义.
parameterMap属性用于配置入参映射关系,在文章Mybatis源码之美:3.4.解析处理parameterMap元素中,我们详细的解析了这个属性的用法,目前该属性已经被行内参数映射和parameterType属性所取代.
parameterType属性
// 参数类型String parameterType = context.getStringAttribute("parameterType");
// 解析参数类
Class<?> parameterTypeClass = resolveClass(parameterType);
parameterType属性同样在select,insert,update以及delete四个元素中都有定义.
parameterType属性用于配置当前select元素的的入参类型,他的取值是执行数据库操作时,传入当前映射语句的参数的全限定名称或者别名.
resultMap属性
// 响应映射String resultMap = context.getStringAttribute("resultMap");
resultMap属性只存在于select元素中,它用于配置结果映射,在文章Mybatis源码之美:3.5.6.resultMap元素的解析过程中,我们已经非常详细的了解了该元素.
resultType属性
String resultType = context.getStringAttribute("resultType");// ... 省略部分代码 ...
Class<?> resultTypeClass = resolveClass(resultType);
和resultMap属性类似,resultType属性也只存在于select元素中,它用于配置结果映射对象的类型,它的取值是返回对象的全限定名称或者别名.
lang属性
// 语言类型String lang = context.getStringAttribute("lang");
// 获取语言驱动
LanguageDriver langDriver = getLanguageDriver(lang);
lang属性同样在select,insert,update以及delete四个元素中都有定义,它用于指定解析当前select元素使用的脚本驱动.
在Mybatis源码之美:3.6.解析sql代码块一文中,我们已经对lang属性做了一个简单了解.
而关于LanguageDriver涉及到的相关内容,我们在上一篇文章Mybatis源码之美:3.10.1.探究CRUD元素解析工作前的知识准备中,也进行了非常细致的探究.
resultSetType和statementType
// 解析不可重复响应集合String resultSetType = context.getStringAttribute("resultSetType");
// 解析语句的声明类型,mybatis目前支持三种,prepare、硬编码、以及存储过程调用
StatementType statementType = StatementType.valueOf(context.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 解析响应集合类型
ResultSetType resultSetTypeEnum = resolveResultSetType(resultSetType);
resultSetType属性只存在于select元素中.
resultSetType属性用于控制jdbc中ResultSet对象的行为,他的取值对应着ResultSetType枚举对象的实例:
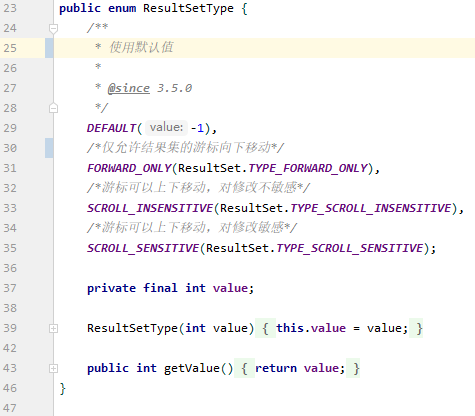
根据JDBC规范,Connection对象创建Statement对象时允许传入一个int类型的resultSetType参数来控制返回的ResultSet对象类型.
statementType属性在select,insert,update以及delete四个元素中都有定义.
select元素的statementType属性用于控制mybatis创建Statement对象的行为.
publicenum StatementType {STATEMENT/*硬编码*/,
PREPARED/*预声明*/,
CALLABLE/*存储过程*/
}
statementType属性有三个取值:STATEMENT,PREPARED以及CALLABLE,默认值为PREPARED.
更多内容,请参考文章Mybatis源码之美:3.7.深入了解select元素中关于resultSetType属性和statementType属性相关的内容.
获取SQL命令类型并处理缓存配置
String nodeName = context.getNode().getNodeName();// 根据节点的名称获取SQL语句类型
SqlCommandType sqlCommandType = SqlCommandType.valueOf(nodeName.toUpperCase(Locale.ENGLISH));
// 判断是否为查询语句
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
// 是否刷新缓存,非查询语句(insert|update|delete)才会刷新缓存
boolean flushCache = context.getBooleanAttribute("flushCache", !isSelect);
// 是否应用缓存,查询语句(select)才会应用缓存
boolean useCache = context.getBooleanAttribute("useCache", isSelect);
flushCache属性在select,insert,update以及delete四个元素中都有定义.
useCache属性只存在于select元素中.
flushCache和useCache两个属性都用于控制myabtis的缓存行为.
其中flushCache属性用于控制清除缓存的行为,当flushCache属性为true时,mybatis在执行语句之前将会清除当前语句所匹配的二级缓存和以及所有的一级缓存.
针对select类型的语句,flushCache属性的默认值为false,其余类型的语句默认值为true.
useCache属性用于控制mybatis将查询语句的结果写入二级缓存的行为,当useCache属性的值为true时,当前语句的执行结果将会被存入到二级缓存中.
resultOrdered属性
// 查询结果是否有序且成组boolean resultOrdered = context.getBooleanAttribute("resultOrdered", false);
resultOrdered属性只存在于select元素中.
resultOrdered属性是一个标志性的属性,用户可以通过配置该属性的值为true来告知mybatis当前select语句的查询结果针对于<id>元素的配置是有序的,即,多个相同<id>属性是分组且连续的,以此来避免OOM的发生.
更多关于resultOrdered属性的细节,请参考文章Mybatis源码之美:3.7.深入了解select元素中关于resultOrdered属性的相关内容.
子元素的解析操作
看完基础属性的取值操作之后,我们就来看一下子元素的解析操作.
根据CRUD元素的定义:

这里所谓的子元素,主要指的就是动态SQL元素,include元素以及SelectKey元素.
从实现上来讲,动态SQL元素的解析工作是由LanguageDriver的createSqlSource()方法来完成的.
include元素的解析工作是由XMLIncludeTransformer对象的applyIncludes()方法完成的.
SelectKey元素的解析工作则是由XMLStatementBuilder对象的processSelectKeyNodes()方法来完成的.
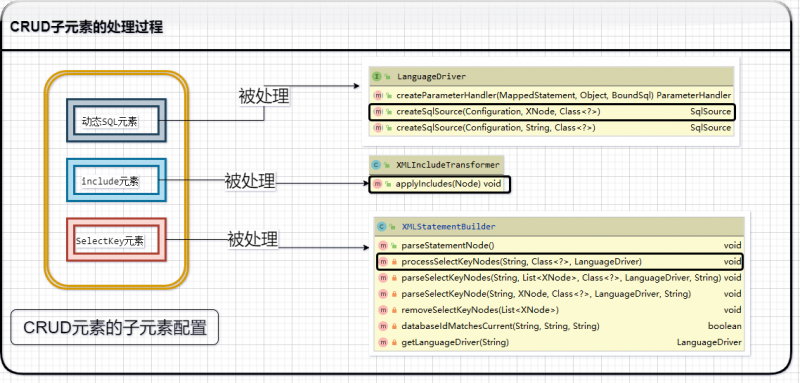
其中,LanguageDriver的createSqlSource()方法的实现,我们在文章Mybatis源码之美:3.10.1.探究CRUD元素解析工作前的知识准备一文中,已经进行了非常详尽的学习,这里就不再赘述了.
因此,我们只需要了解include元素的解析工作和SelectKey元素的解析工作即可.
include元素的解析工作
按照顺序,我们先来看一下负责解析处理include元素的XMLIncludeTransformer对象的实现.
见名知意,XMLIncludeTransformer对象的主要作用就是解析include元素,引入include元素对应的sql代码块,并替换被导入的代码块中的${}占位符.
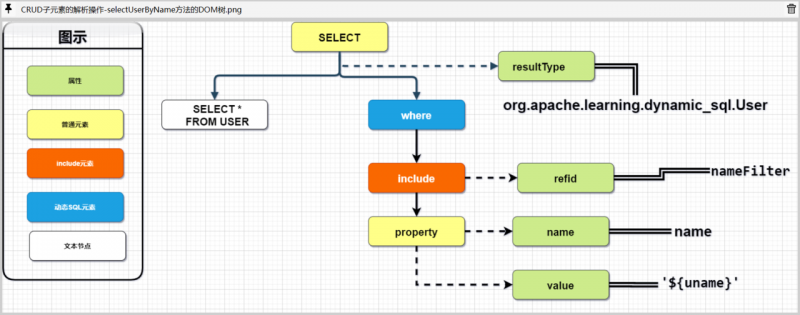
举例来说,针对原始配置:
<sqlid="nameFilter">AND name= ${name}
</sql>
<selectid="selectUserByName"resultType="org.apache.learning.dynamic_sql.User">
SELECT *
FROM USER
<where>
<includerefid="nameFilter">
<propertyname="name"value="'${uname}'"/>
</include>
</where>
</select>
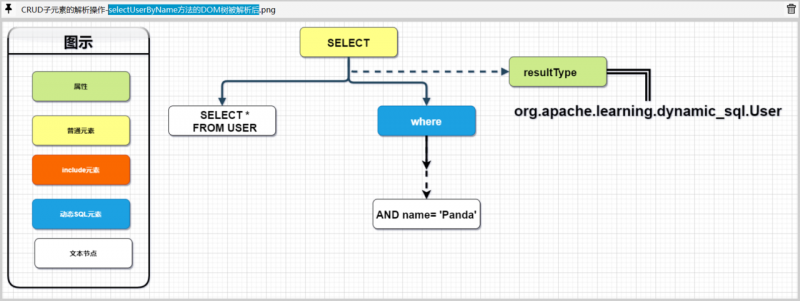
假设我们调用selectUserByName方法时,传入的uname参数是Panda,在经过处理XMLIncludeTransformer后,selectUserByName的DOM节点将会变更为:
<selectid="selectUserByName"resultType="org.apache.learning.dynamic_sql.User">SELECT *
FROM USER
<where>
AND name= 'Panda'
</where>
</select>
对比处理前后的DOM数据,我们可以发现selectUserByName配置中的include和${}占位符被处理了.
回到实现上来,XMLIncludeTransformer对象有两个常规属性定义,这两个属性是在构造方法中被赋值的:
privatefinal Configuration configuration;privatefinal MapperBuilderAssistant builderAssistant;
publicXMLIncludeTransformer(Configuration configuration, MapperBuilderAssistant builderAssistant){
this.configuration = configuration;
this.builderAssistant = builderAssistant;
}
Configuration和MapperBuilderAssistant这两个对象我们已经很熟悉了,这里就不再重复介绍了.
XMLIncludeTransformer对象的applyIncludes()方法是元素解析的入口,applyIncludes()的实现并不复杂,他将主要的处理工作都委托给了他的同名重载方法来完成:
publicvoidapplyIncludes(Node source){Properties variablesContext = new Properties();
// 获取Mybatis全局配置
Properties configurationVariables = configuration.getVariables();
if (configurationVariables != null) {
variablesContext.putAll(configurationVariables);
}
// 替换变量内容
applyIncludes(source, variablesContext, false);
}
重载的applyIncludes()方法有三个入参:Node类型的source表示需要被解析处理的元素,Properties类型的variablesContext表示用来处理${}占位符的参数集合,boolean类型的included则表示当前处理的元素是否是通过include元素引入进来的.
privatevoidapplyIncludes(Node source, final Properties variablesContext, boolean included){//...
}
因此,在调用重载的applyIncludes()方法之前,原始的applyIncludes()方法会利用mybatis的全局配置生成了处理${}占位符的参数集合,并指定include的取值为false.
included参数的取值十分重要,它的取值决定了是否解析元素中的${}占位符.
从实现上来看,重载的applyIncludes()方法根据处理元素的类型将处理操作分为三类,分别是include元素,非include元素以及纯文本节点.
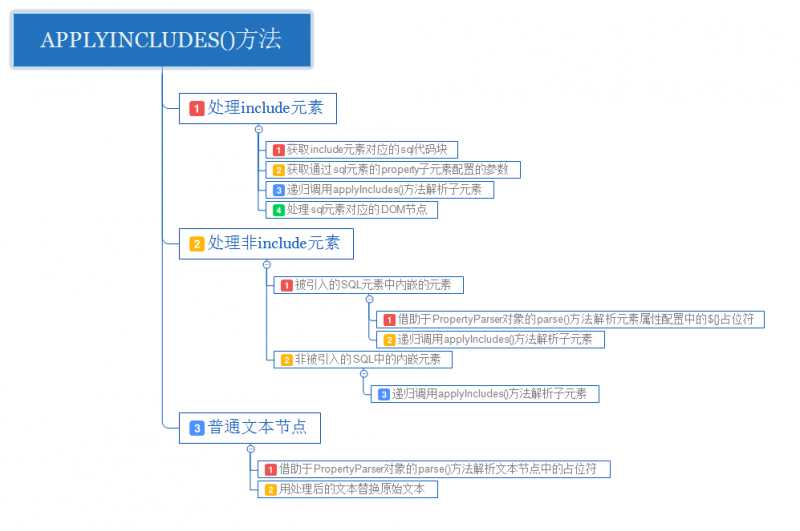
我们将上述的示例代码进行拆解,大致能够得到下列DOM结构:
下面我们就一步一步的拆解和处理上面这个DOM树.
解析纯文本节点
纯文本节点的处理操作是最简单的:
elseif (included && source.getNodeType() == Node.TEXT_NODE&& !variablesContext.isEmpty()) {
// 处理文本节点
// 这里的文本内容是具体的SQL
// 替换文本内的变量
// replace variables in text node
source.setNodeValue(PropertyParser.parse(source.getNodeValue(), variablesContext));
}
借助于PropertyParser的parse()方法,将${}占位符替换成相应的数据,并替换原始的纯文本节点.
解析非include元素
其次就是非include元素的解析处理操作,这个操作也不复杂,但是前提是我们需要明确非include元素都是哪些元素?
applyIncludes()方法的调用位置有三处,分别是:
- 由原始的
applyIncludes()方法调用,被处理的是include元素定义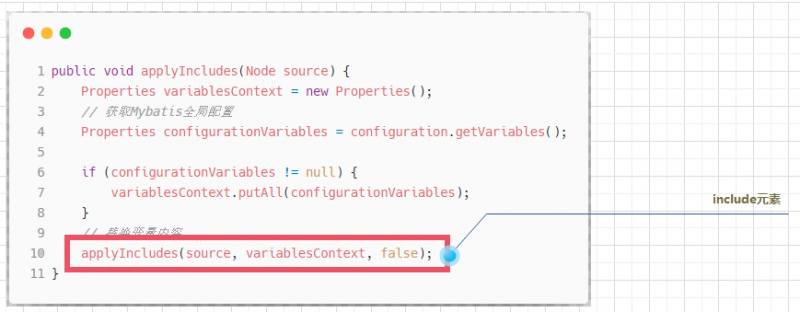
- 递归处理被
include元素引入的sql子元素的定义,被处理的sql元素定义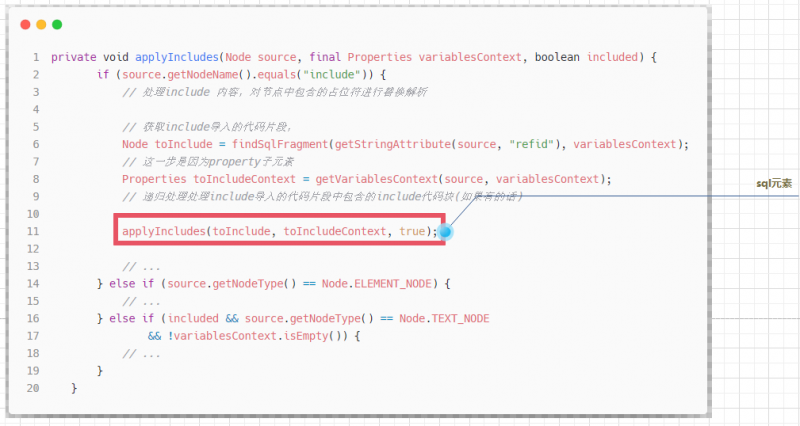
- 处理
sql元素以及动态SQL元素的子元素定义,被处理的是include和动态SQL元素定义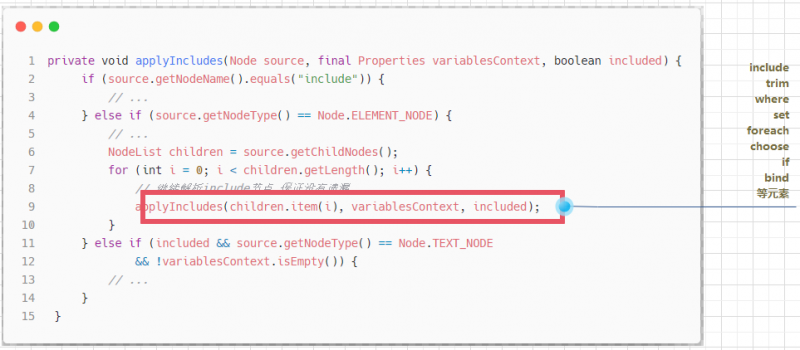
除去include元素,剩下的元素都是动态SQL元素,因此这里的非include元素指的就是动态SQL元素.
针对被引入的非include元素的解析处理操作也不复杂,同样借助于PropertyParser的parse()方法完成非include元素的属性配置中包含的${}占位符,然后递归调用重载的applyIncludes()方法完成被引入的非include元素的子元素的处理操作:
elseif (source.getNodeType() == Node.ELEMENT_NODE) {// 处理非Include内容
if (included && !variablesContext.isEmpty()) {
// 非根节点,且变量上下文不为空
// 替换变量值
// replace variables in attribute values
NamedNodeMap attributes = source.getAttributes();
for (int i = 0; i < attributes.getLength(); i++) {
Node attr = attributes.item(i);
// 处理占位符内容
attr.setNodeValue(
PropertyParser.parse(attr.getNodeValue(), variablesContext)
);
}
}
NodeList children = source.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
// 继续解析include节点.保证没有遗漏
applyIncludes(children.item(i), variablesContext, included);
}
}
解析include元素
最后就是相对比较复杂一点的include元素的处理操作,在前面的学习中,我们已经了解sql元素的解析和注册过程,在这里,我们将会使用前面注册的sql元素.
sql元素的处理工作参考文章:Mybatis源码之美:3.6.解析sql代码块.在解析处理include元素时,大致可以分为三步:
- 1.获取被引入的
sql代码块,并解析代码块中的属性定义 - 2.递归调用
applyIncludes()方法解析sql代码块中的include元素 - 3.处理
sql代码块对应的DOM节点
首先是第一步的实现,这一过程比较简单,借助于findSqlFragment()方法从Configuration对象中加载出前面保存的sql代码块:
/*** 寻址被引用的Sql代码块
*/
private Node findSqlFragment(String refid, Properties variables){
// 获取include标签引用的id
refid = PropertyParser.parse(refid, variables);
// 将该ID转换为包含命名空间的唯一标志
refid = builderAssistant.applyCurrentNamespace(refid, true);
try {
// 获取对应的代码片段
XNode nodeToInclude = configuration.getSqlFragments().get(refid);
// 返回对应节点的深度克隆(全新)
return nodeToInclude.getNode().cloneNode(true);
} catch (IllegalArgumentException e) {
thrownew IncompleteElementException("Could not find SQL statement to include with refid '" + refid + "'", e);
}
}
findSqlFragment()通过sql代码块的唯一标志从Configuration对象中取出相对应的XNode节点,并返回该节点所对应的DOM节点的全新克隆对象.
得到sql代码块之后,通过getVariablesContext()方法加载解析sql代码块中的property子元素对应的参数配置,将其存放到用于处理占位符对象的Properties类型的variablesContext对象中:
private Properties getVariablesContext(Node node, Properties inheritedVariablesContext){Map<String, String> declaredProperties = null;
NodeList children = node.getChildNodes();
for (int i = 0; i < children.getLength(); i++) {
Node n = children.item(i);
if (n.getNodeType() == Node.ELEMENT_NODE) {
// 获取include嵌套的property元素的属性名称
String name = getStringAttribute(n, "name");
// Replace variables inside
// 获取在${}占位符中的内容,如果能够不能够获取占位符对应的内容,则返回占位符本身。
String value = PropertyParser.parse(getStringAttribute(n, "value"), inheritedVariablesContext);
if (declaredProperties == null) {
declaredProperties = new HashMap<>();
}
// 保存占位符和值的对应关系
if (declaredProperties.put(name, value) != null) {
thrownew BuilderException("Variable " + name + " defined twice in the same include definition");
}
}
}
// 聚合所有的参数配置
if (declaredProperties == null) {
return inheritedVariablesContext;
} else {
Properties newProperties = new Properties();
newProperties.putAll(inheritedVariablesContext);
newProperties.putAll(declaredProperties);
return newProperties;
}
}
在处理完property子元素之后,mybatis将会递归调用applyIncludes()方法处理被引入的sql元素中的include子元素和${}占位符.
最后,mybatis再操作DOM树,以引入sql元素对应的DOM节点,替换原始的include元素对应的DOM节点.
经过一番处理之后,上文中的示例代码对应的DOM树将会变为:
这就是完整的applyIncludes()方法的实现了.
现在再回头看一下LanguageDriver的createSqlSource()方法,我们会发现他处理的DOM节点中已经不再包含include和sql元素了.
SelectKey元素的解析
selectKey元素的解析工作是由XMLStatementBuilder对象的processSelectKeyNodes()方法来完成的.
关于selectKey元素的用法和效果,我们在文章Mybatis源码之美:3.8.探究insert,update以及delete元素的用法中的selectKey子元素和KeyGenerator接口定义部分做了详细介绍,
前面我们说过,selectKey元素的用法有点像是一个阉割版的select元素,因此它的解析过程和select元素也有部分类似的地方.
负责解析selectKey元素的processSelectKeyNodes()方法会加载当前CRUD元素下的所有selectKey元素配置,并交给parseSelectKeyNodes()方法来完成处理操作.
privatevoidprocessSelectKeyNodes(String id, Class<?> parameterTypeClass, LanguageDriver langDriver){// 获取selectKey节点
List<XNode> selectKeyNodes = context.evalNodes("selectKey");
if (configuration.getDatabaseId() != null) {
// 解析指定为当前数据库类型的SelectKey
parseSelectKeyNodes(id, selectKeyNodes, parameterTypeClass, langDriver, configuration.getDatabaseId());
}
// 解析所有未指定数据库类型的SelectKey
parseSelectKeyNodes(id, selectKeyNodes, parameterTypeClass, langDriver, null);
// 移除所有selectKey节点
removeSelectKeyNodes(selectKeyNodes);
}
在processSelectKeyNodes()方法中,同样是调用了两次parseSelectKeyNodes()方法来实现对databaseId属性的支持,同时在处理了selectKey元素之后,还会调用removeSelectKeyNodes()方法从DOM树中移除selectKey元素相关的内容.
privatevoidremoveSelectKeyNodes(List<XNode> selectKeyNodes){for (XNode nodeToHandle : selectKeyNodes) {
nodeToHandle.getParent().getNode().removeChild(nodeToHandle.getNode());
}
}
至于为什么要移除selectKey元素对应的DOM节点?这是因为在将
selectKey元素转换为KeyGenerator实例之后,后续的操作就不在需要使用原始的selectKey元素配置了.
真正负责解析selectKey元素集合的parseSelectKeyNodes()方法在实现上,将所有通过databaseIdMatchesCurrent()方法校验的selectKey元素都交给了parseSelectKeyNode()方法来处理:
privatevoidparseSelectKeyNodes(String parentId, List<XNode> list, Class<?> parameterTypeClass, LanguageDriver langDriver, String skRequiredDatabaseId){for (XNode nodeToHandle : list) {
// 生成selectKey唯一标志
String id = parentId + SelectKeyGenerator.SELECT_KEY_SUFFIX;
// 获取数据库标志
String databaseId = nodeToHandle.getStringAttribute("databaseId");
if (databaseIdMatchesCurrent(id, databaseId, skRequiredDatabaseId)) {
// 解析SelectKey节点
parseSelectKeyNode(id, nodeToHandle, parameterTypeClass, langDriver, databaseId);
}
}
}
这里databaseIdMatchesCurrent()方法的实现,除了做了databaseId属性的校验之外,还额外对CRUD元素的id属性做了验证,以确保未指定databaseId属性的selectKey配置不会覆盖指定了databaseId属性的selectKey配置:
privatebooleandatabaseIdMatchesCurrent(String id, String databaseId, String requiredDatabaseId){if (requiredDatabaseId != null) {
if (!requiredDatabaseId.equals(databaseId)) {
returnfalse;
}
} else {
if (databaseId != null) {
returnfalse;
}
// skip this statement if there is a previous one with a not null databaseId
id = builderAssistant.applyCurrentNamespace(id, false);
if (this.configuration.hasStatement(id, false)) {
MappedStatement previous = this.configuration.getMappedStatement(id, false); // issue #2
if (previous.getDatabaseId() != null) {
// 确保未指定`databaseId`属性的`selectKey`配置不会覆盖指定了`databaseId`属性的`selectKey`配置.
returnfalse;
}
}
}
returntrue;
}
parseSelectKeyNode()方法的业务逻辑非常简单,他负责解析selectKey元素的配置,为其创建一个负责查询的MappedStatement对象,并利用该对象生成SelectKeyGenerator实例:
privatevoidparseSelectKeyNode(String id, XNode nodeToHandle, Class<?> parameterTypeClass, LanguageDriver langDriver, String databaseId){// 获取返回类型
String resultType = nodeToHandle.getStringAttribute("resultType");
// 解析出返回类型的实际类型
Class<?> resultTypeClass = resolveClass(resultType);
// 解析声明语句类型
StatementType statementType = StatementType.valueOf(nodeToHandle.getStringAttribute("statementType", StatementType.PREPARED.toString()));
// 解析key值
String keyProperty = nodeToHandle.getStringAttribute("keyProperty");
// 解析key指端
String keyColumn = nodeToHandle.getStringAttribute("keyColumn");
// 解析在语句之前还是之后执行
boolean executeBefore = "BEFORE".equals(nodeToHandle.getStringAttribute("order", "AFTER"));
//defaults
// 不使用缓存
boolean useCache = false;
boolean resultOrdered = false;
// 无主键生成器
KeyGenerator keyGenerator = NoKeyGenerator.INSTANCE;
Integer fetchSize = null;
Integer timeout = null;
boolean flushCache = false;
String parameterMap = null;
String resultMap = null;
// 定义查询结果ResultSet的类别
ResultSetType resultSetTypeEnum = null;
/*
===============================================================================================
创建SqlSource
===============================================================================================
*/
// 解析SQL语句
SqlSource sqlSource = langDriver.createSqlSource(configuration, nodeToHandle, parameterTypeClass);
// 解析SQL命令类型,SelectKey必然为查询(SELECT)
SqlCommandType sqlCommandType = SqlCommandType.SELECT;
// 添加声明语句的映射关系
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, null);
// 合并命名空间
id = builderAssistant.applyCurrentNamespace(id, false);
// 获取声明语句,这个位置比较有意思,builderAssistant.addMappedStatement方法可以直接返回生成的MappedStatement对象的。
MappedStatement keyStatement = configuration.getMappedStatement(id, false);
// 配置主键生成器
configuration.addKeyGenerator(id, new SelectKeyGenerator(keyStatement, executeBefore));
}
该方法的实现也不复杂,首先通过解析selectKey元素的属性配置得到创建MappedStatement对象所需的部分核心属性,之后提供一系列默认值用于创建MappedStatement对象.
然后利用LanguageDriver获取用于维护selectKey元素对应的SQL配置的SqlSource对象,然后利用这些属性构建一个用于执行查询操作的MappedStatement对象,该MappedStatement对象将会被用来获取主键数据.
最后,注册并创建selectKey元素对应的SelectKeyGenerator对象.
关于具体selectKey元素对应的MappedStatement对象的创建过程,和通过CRUD元素创建对应的MappedStatement对象基本一致,因此,后续会将二者合并介绍.
回到CRUD元素的解析处理过程中来,在处理完selectKey元素之后,接下来就是KeyGenerator对象的筛选工作.
KeyGenerator对象的筛选
为一条CRUD语句配置相应的KeyGenerator对象有两种方式,一种是配置selectKey子元素,另一种是配置useGeneratedKeys属性.
selectKey子元素配置对应着SelectKeyGenerator实现,useGeneratedKeys则对应着Jdbc3KeyGenerator实现.
mybatis在筛选有效的KeyGenerator对象时,优先使用SelectKeyGenerator,其次使用Jdbc3KeyGenerator,如果二者皆未配置,那就使用NoKeyGenerator实现:
// 配置主键生成器KeyGenerator keyGenerator;
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;
// 合并命名空间
keyStatementId = builderAssistant.applyCurrentNamespace(keyStatementId, true);
// 获取主键生成器
if (configuration.hasKeyGenerator(keyStatementId)) {
// 已有直接获取
keyGenerator = configuration.getKeyGenerator(keyStatementId);
} else {
// 没有则生成
keyGenerator = context.getBooleanAttribute("useGeneratedKeys",
configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType))
? Jdbc3KeyGenerator.INSTANCE : NoKeyGenerator.INSTANCE;
}
细看上述实现,CRUD元素上的useGeneratedKeys配置优先级要高于useGeneratedKeys的全局配置.
这里稍微一提selectKey元素唯一标志的生成规则,如果用户通过selectKey配置了KeyGenerator对象,在前面的处理过程中,将会往mybatis中注册一个和当前CRUD元素对应的KeyGenerator对象,这个KeyGenerator对象的全局唯一标志的生成策略是:CRUD元素的全局唯一标志加上!selectKey:
String keyStatementId = id + SelectKeyGenerator.SELECT_KEY_SUFFIX;MappedStatement对象的构建工作
完成了基本属性和子元素的解析工作之后,接下来就是利用得到的数据构建并注册MappedStatement对象了.
// step3: MappedStatement对象的构建工作// 构建整体配置
builderAssistant.addMappedStatement(id, sqlSource, statementType, sqlCommandType,
fetchSize, timeout, parameterMap, parameterTypeClass, resultMap, resultTypeClass,
resultSetTypeEnum, flushCache, useCache, resultOrdered,
keyGenerator, keyProperty, keyColumn, databaseId, langDriver, resultSets);
和前面文章中介绍的类似,MappedStatement对象的构建构建工作也是由MapperBuilderAssistant对象来完成的.
在MapperBuilderAssistant对象的addMappedStatement()方法中,首先校验了被引用缓存的解析情况,之后将id属性转为全局唯一标志,并在处理了parameterMap和parameterType之后,将前面解析到的数据交给MappedStatement对象的构建器MappedStatement.Builder来完成MappedStatement对象的创建工作,最后将得到的MappedStatement对象注册到mybatis中,并返回MappedStatement对象:
public MappedStatement addMappedStatement(String id,
SqlSource sqlSource,
StatementType statementType,
SqlCommandType sqlCommandType,
Integer fetchSize,
Integer timeout,
String parameterMap,
Class<?> parameterType,
String resultMap,
Class<?> resultType,
ResultSetType resultSetType,
boolean flushCache,
boolean useCache,
boolean resultOrdered,
KeyGenerator keyGenerator,
String keyProperty,
String keyColumn,
String databaseId,
LanguageDriver lang,
String resultSets)
{if (unresolvedCacheRef) {
// 未完成缓存的引用工作
thrownew IncompleteElementException("Cache-ref not yet resolved");
}
// 合并命名空间,将其转换为全局唯一的标志
id = applyCurrentNamespace(id, false);
// 判断当前语句是否为查询语句
boolean isSelect = sqlCommandType == SqlCommandType.SELECT;
// 生成映射声明
MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
.resource(resource)
.fetchSize(fetchSize)
.timeout(timeout)
.statementType(statementType)
.keyGenerator(keyGenerator)
.keyProperty(keyProperty)
.keyColumn(keyColumn)
.databaseId(databaseId)
.lang(lang)
.resultOrdered(resultOrdered)
.resultSets(resultSets)
.resultMaps(getStatementResultMaps(resultMap, resultType, id))
.resultSetType(resultSetType)
.flushCacheRequired(valueOrDefault(flushCache, !isSelect))
.useCache(valueOrDefault(useCache, isSelect))
.cache(currentCache);
// 生成参数映射声明
ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id);
if (statementParameterMap != null) {
// 加入参数映射声明
statementBuilder.parameterMap(statementParameterMap);
}
/*
* 生成映射语句
*/
MappedStatement statement = statementBuilder.build();
/*
* 添加映射
*/
configuration.addMappedStatement(statement);
return statement;
}
上述代码中,比较复杂的MappedStatement.Builder对象,我们待会在探究,现在,我们先关注一下上述代码中关于ParameterMap对象的处理操作,在getStatementParameterMap()方法中,针对用户未配置parameterMap的场景,在用户指定了parameterType的前提下,将会为其生成一个包含type属性的ParameterMap对象:
private ParameterMap getStatementParameterMap(String parameterMapName,
Class<?> parameterTypeClass,
String statementId)
{// 合并命名空间
parameterMapName = applyCurrentNamespace(parameterMapName, true);
ParameterMap parameterMap = null;
if (parameterMapName != null) {
try {
parameterMap = configuration.getParameterMap(parameterMapName);
} catch (IllegalArgumentException e) {
thrownew IncompleteElementException("Could not find parameter map " + parameterMapName, e);
}
} elseif (parameterTypeClass != null) {
// 根据参数类型生成参数映射
List<ParameterMapping> parameterMappings = new ArrayList<>();
parameterMap =
new ParameterMap.Builder(
configuration,
statementId + "-Inline",
parameterTypeClass,
parameterMappings
).build();
}
return parameterMap;
}
这就意味着,parameterMap配置的优先级要高于parameterType.
鉴于往mybatis中注册MappedStatement对象只是简单的赋值操作而已:
publicvoidaddMappedStatement(MappedStatement ms){mappedStatements.put(ms.getId(), ms);
}
因此,我们将主要精力放回到MappedStatement.Builder对象上来.
回顾addMappedStatement()方法中对MappedStatement.Builder对象的使用:
// 生成映射声明MappedStatement.Builder statementBuilder = new MappedStatement.Builder(configuration, id, sqlSource, sqlCommandType)
.resource(resource)
.fetchSize(fetchSize)
.timeout(timeout)
.statementType(statementType)
.keyGenerator(keyGenerator)
.keyProperty(keyProperty)
.keyColumn(keyColumn)
.databaseId(databaseId)
.lang(lang)
.resultOrdered(resultOrdered)
.resultSets(resultSets)
.resultMaps(getStatementResultMaps(resultMap, resultType, id))
.resultSetType(resultSetType)
.flushCacheRequired(valueOrDefault(flushCache, !isSelect))
.useCache(valueOrDefault(useCache, isSelect))
.cache(currentCache);
// 生成参数映射声明
ParameterMap statementParameterMap = getStatementParameterMap(parameterMap, parameterType, id);
if (statementParameterMap != null) {
// 加入参数映射声明
statementBuilder.parameterMap(statementParameterMap);
}
/*
* 生成映射语句
*/
MappedStatement statement = statementBuilder.build();
小小的代码中,隐藏着很多容易让人忽略的小细节,首先是MappedStatement.Builder的构造方法:
publicBuilder(Configuration configuration, String id, SqlSource sqlSource, SqlCommandType sqlCommandType){// 初始化对应的Mybatis Configuration对象的引用
mappedStatement.configuration = configuration;
// 初始化当前声明语句的唯一标志
mappedStatement.id = id;
// 初始化对应的Sql内容
mappedStatement.sqlSource = sqlSource;
// 初始化JDBC Statement对象的类型
mappedStatement.statementType = StatementType.PREPARED;
// 初始化JDBC ResultSet对象的类型
mappedStatement.resultSetType = ResultSetType.DEFAULT;
// 初始化一个空的入参映射列表
mappedStatement.parameterMap = new ParameterMap.Builder(configuration, "defaultParameterMap", null, new ArrayList<>()).build();
// 初始化一个空的返回参数映射列表
mappedStatement.resultMaps = new ArrayList<>();
// 初始化Sql命令的类型
mappedStatement.sqlCommandType = sqlCommandType;
// 初始化主键生成器
mappedStatement.keyGenerator = configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType)
? Jdbc3KeyGenerator.INSTANCE
: NoKeyGenerator.INSTANCE;
String logId = id;
if (configuration.getLogPrefix() != null) {
// 使用唯一标志生成日志前缀。
logId = configuration.getLogPrefix() + id;
}
// 初始化对应的日志记录工具
mappedStatement.statementLog = LogFactory.getLog(logId);
// 初始化脚本语言解析器
mappedStatement.lang = configuration.getDefaultScriptingLanguageInstance();
}
除了常规属性赋值之外,该方法还为MappedStatement的核心属性提供了默认值,其中值得注意的主要有下面几个部分:
statementType默认使用StatementType.PREPARED// 初始化JDBC Statement对象的类型mappedStatement.statementType = StatementType.PREPARED;
resultSetType默认使用ResultSetType.DEFAULT// 初始化JDBC ResultSet对象的类型mappedStatement.resultSetType = ResultSetType.DEFAULT;
- 提供默认的入参映射配置
// 初始化一个空的入参映射列表mappedStatement.parameterMap = new ParameterMap.Builder(configuration, "defaultParameterMap", null, new ArrayList<>()).build();
- 针对于
INSERT语句,在开启了全局useGeneratedKeys配置的前提下,默认使用Jdbc3KeyGenerator作为主键生成器.// 初始化主键生成器mappedStatement.keyGenerator = configuration.isUseGeneratedKeys() && SqlCommandType.INSERT.equals(sqlCommandType)
? Jdbc3KeyGenerator.INSTANCE
: NoKeyGenerator.INSTANCE;
- 使用默认的脚本解释器
// 初始化脚本语言解析器mappedStatement.lang = configuration.getDefaultScriptingLanguageInstance();
除了构造方法中提供了为MappedStatement属性提供默认值的行为之外,MappedStatement.Builder的其他方法调用也隐藏着一些小细节:
- 使用
,拆分keyProperty,keyColumn以及resultSets的属性值在前面的学习过程中,我们知道
keyProperty和keyColumn以及resultSets属性可以通过使用,分隔的形式来提供一组数据,这里就是针对这一特性的实现:public Builder keyProperty(String keyProperty){// 分割出所有的属性名称
mappedStatement.keyProperties = delimitedStringToArray(keyProperty);
returnthis;
}
public Builder keyColumn(String keyColumn){
// 分割出所有的列名称
mappedStatement.keyColumns = delimitedStringToArray(keyColumn);
returnthis;
}
public Builder resultSets(String resultSet){
// 分割出所有的多返回结果集的名称
mappedStatement.resultSets = delimitedStringToArray(resultSet);
returnthis;
}
privatestatic String[] delimitedStringToArray(String in) {
if (in == null || in.trim().length() == 0) {
returnnull;
} else {
return in.split(",");
}
}
- 提供对多
ResultMap对象的支持考虑到对多返回结果集(
resultSets)的支持,mybatis支持多ResultMap对象就显得很合情合理了和
keyProperty类似,我们同样可以通过使用,分隔符来为一个声明语句配置多个resultMap,以便于能够正确处理通过resultSets属性配置多返回结果集的场景.负责加载多
ResultMap对象的方法是getStatementResultMaps(),该方法除了支持多ResultMap对象之外,还能在未指定ResultMap对象时提供一个默认的ResultMap对象:private List<ResultMap> getStatementResultMaps(String resultMap,
Class<?> resultType,
String statementId)
{resultMap = applyCurrentNamespace(resultMap, true);
List<ResultMap> resultMaps = new ArrayList<>();
if (resultMap != null) {
String[] resultMapNames = resultMap.split(",");
for (String resultMapName : resultMapNames) {
try {
resultMaps.add(configuration.getResultMap(resultMapName.trim()));
} catch (IllegalArgumentException e) {
thrownew IncompleteElementException("Could not find result map " + resultMapName, e);
}
}
} elseif (resultType != null) {
ResultMap inlineResultMap = new ResultMap.Builder(
configuration,
statementId + "-Inline",
resultType,
new ArrayList<ResultMapping>(),
null).build();
resultMaps.add(inlineResultMap);
}
return resultMaps;
}
同样,在
MappedStatement.Builder处理上面得到的多ResultMap对象时,也会对hasNestedResultMaps属性做进一步的处理:public Builder resultMaps(List<ResultMap> resultMaps){mappedStatement.resultMaps = resultMaps;
for (ResultMap resultMap : resultMaps) {
// 判断是否持有内嵌的ResultMap对象
mappedStatement.hasNestedResultMaps = mappedStatement.hasNestedResultMaps || resultMap.hasNestedResultMaps();
}
returnthis;
}
hasNestedResultMaps用于表示当前MappedStatement是否持有内嵌的ResultMap对象,因此上述的处理也是合情合理的.
最后就是MappedStatement.Builder的build()方法了,该方法进行了基本的属性校验工作,并返回可用的MappedStatement对象:
public MappedStatement build(){assert mappedStatement.configuration != null;
assert mappedStatement.id != null;
assert mappedStatement.sqlSource != null;
assert mappedStatement.lang != null;
mappedStatement.resultMaps = Collections.unmodifiableList(mappedStatement.resultMaps);
// 返回MappedStatement对象
return mappedStatement;
}
探究MappedStatement的方法实现
在本文开始,我们简单的了解了MappedStatement的属性定义,但是并未对MappedStatement对象的方法进行探究,实际上在MappedStatement中,除了属性的标准getter/setter方法之外,真正对外暴露的有效方法只有getBoundSql()一个,该方法的作用是根据用户调用CRUD方法时传入的参数对象,构建并返回一个真实可用的BoundSql对象:
public BoundSql getBoundSql(Object parameterObject){// sqlSource对象的创建工作在解析Mapper Xml 文件时完成
// 获取对应的BoundSql对象
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);
// 获取Sql对应的入参映射集合
List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
// 处理嵌套的参数映射配置
// check for nested result maps in parameter mappings (issue #30)
for (ParameterMapping pm : boundSql.getParameterMappings()) {
// 对应的ResultMap配置唯一标志
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);
if (rm != null) {
// 重置是否有嵌套返回结果映射标识
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
return boundSql;
}
从实现上来看,该方法的处理流程也比较简单,实际创建BoundSql对象的工作是由SqlSource的getBoundSql()方法来完成的.
BoundSql boundSql = sqlSource.getBoundSql(parameterObject);回顾前面的学习,我们知道在SqlSource的实现类中所有的getBoundSql()方法实现最终都是由StaticSqlSource对象来完成的,负责构建StaticSqlSource对象的SqlSourceBuilder的parse()方法通过解析行内参数映射得到了StaticSqlSource对象所需的parameterMappings集合:
/*** 解析成SQL的PreStatement
*/
public SqlSource parse(String originalSql, Class<?> parameterType, Map<String, Object> additionalParameters){
ParameterMappingTokenHandler handler = new ParameterMappingTokenHandler(configuration, parameterType, additionalParameters);
// 解析 【#{】和【}】直接的内容
GenericTokenParser parser = new GenericTokenParser("#{", "}", handler);
String sql = parser.parse(originalSql);
returnnew StaticSqlSource(configuration, sql, handler.getParameterMappings());
}
因此,此时得到的BoundSql对象的parameterMappings集合是通过解析行内参数映射得到的.
在这个前提下,我们继续看getBoundSql()方法的实现.
MappedStatement对象的getBoundSql()方法主要做的是一些后置的处理操作,比如在没有配置行内参数映射的前提下,使用当前MappedStatement对象的parameterMap,重新构建BoundSql对象.
// 获取Sql对应的入参映射集合List<ParameterMapping> parameterMappings = boundSql.getParameterMappings();
if (parameterMappings == null || parameterMappings.isEmpty()) {
boundSql = new BoundSql(configuration, boundSql.getSql(), parameterMap.getParameterMappings(), parameterObject);
}
这一步的作用实现的特性是:行内参数映射的优先级高于parameterMap属性配置.最后,根据paramter元素的定义,我们是可以通过resultMap属性引用现有的ResultMap对象的:
<!ELEMENTparameterMap (parameter+)?><!ATTLISTparameterMap
idCDATA #REQUIRED
typeCDATA #REQUIRED
>
<!ELEMENTparameterEMPTY>
<!ATTLISTparameter
propertyCDATA #REQUIRED
javaTypeCDATA #IMPLIED
jdbcTypeCDATA #IMPLIED
mode (IN | OUT | INOUT) #IMPLIED
resultMapCDATA #IMPLIED
scaleCDATA #IMPLIED
typeHandlerCDATA #IMPLIED
>
因此,接下来就是根据前面的入参映射配置集合来重置当前MappedStatement对象的hasNestedResultMaps标记:
// 处理嵌套的参数映射配置// check for nested result maps in parameter mappings (issue #30)
for (ParameterMapping pm : boundSql.getParameterMappings()) {
// 对应的ResultMap配置唯一标志
String rmId = pm.getResultMapId();
if (rmId != null) {
ResultMap rm = configuration.getResultMap(rmId);
if (rm != null) {
// 重置是否有嵌套返回结果映射标识
hasNestedResultMaps |= rm.hasNestedResultMaps();
}
}
}
这样,我们就算完成了MappedStatement对象的学习工作.
截止到目前为止,我们基本完成了mybatis中Mapper文件的解析工作,接下来就是回头去看一下mybatis中针对Mapper接口的解析操作了.
以上是 Mybatis XMLStatementBuilder工作原理 的全部内容, 来源链接: utcz.com/a/18564.html