
Sunday字符串匹配算法比KMP算法快七倍
前言
上一篇我用动画的方式向大家详细说明了KMP算法(没看过的同学可以回去看看)。
这次我依旧采用动画的方式向大家介绍另一个你用一次就会爱上的字符串匹配算法:Sunday算法,希望能收获你的点赞关注收藏与转发哟!
KMP算法是一个里程碑似的算法,它的出现宣告了人类是找到线性时间复杂度的字符串匹配算法的。在这之后,出现了许多的字符串匹配算法,比如BM算法和Sunday算法。
这些算法在时间复杂度上都已经达到了线性时间。但是在实际应用的时候所耗费的时间却还是有所不同。
BM算法在实际应用中的效率已经达到了KMP算法的四五倍。
而Sunday算法的效率甚至犹在BM算法之上。
并且若是两种算法都了解的同学会明白:
Sunday算法比起BM算法来,真的极其容易理解。
正文
行,咱对Sunday算法的吹捧先到这为止,下面开始正戏!
PS:以下将带匹配字符串称为文本串,将用来匹配的字符串称为模式串。
为什么说Sunday算法极易理解呢?
因为它比暴力匹配算法只多了一个步骤而已!
话不多说,直接上我精心制作的GIF动态图:

可以看到,我们只移动了三次,就直接找到了最终的结果。
Sunday算法是从前往后匹配的算法(BM算法是从后向前的),在匹配失败时重点关注的是文本串中参加匹配的最末位字符的下一位字符。
- 如果该字符没有在模式串中出现则直接跳过,即移动位数 = 模式串长度 + 1。
- 否则,其移动位数 = 模式串长度 - 该字符最右出现的位置(以0开始) = 模式串中该字符最右出现的位置到尾部的距离 + 1。
Sunday算法最巧妙的地方,就在于它发现匹配失败之后可以直接考察文本串中参加匹配的最末尾字符的下一个字符。
在python代码中,我们利用字典来存储模式串中每个字符最后出现的索引,这样在前期只需O(M),M为模式串长度的时间即可做完前期准备,然后再进行查询都是O(1)的时间。
同时为了防止越界,我在下面贴出来的python代码中手动在字符串末尾加上了一个''字符。
代码
class Sunday(object):def __init__(self, pattern:str):
# 模式串和其长度
self.pattern, self.length = pattern, len(pattern)
# 根据模式串构建的偏移字典
self.shift_dict = {}
# 构建字典
for index, value in enumerate(pattern):
self.shift_dict[value] = self.length - index
def match(self, text:str):
i = 0
text_length = len(text)
text += ''
while i <= text_length - self.length:
j = 0
while self.pattern[j] == text[i + j]:
j += 1
if j >= self.length:
return i
offset = self.shift_dict[text[i+self.length]] if text[i+self.length] in self.shift_dict else self.length + 1
i += offset
return -1
s = Sunday('nihao')
print(s.match('dasoijfoasjdoifjasdoifjoinihao'))
代码十分的简单,同时,我构造了一个类,是为了在同一个模式串下能够复用它的位置字典,简化代码。
Sunday算法与KMP算法大比拼
在写完代码之后,我对KMP算法和Sunday算法的匹配时间进行了一个粗略的检测,检测结果如下:

amazing!,Sunday算法的平均匹配速度达到了KMP算法的七倍左右!
对KMP和Sunday各自构造了一个对象,然后每次生成一个随机的十万个字符长度的字符串让它们俩分别开始匹配。
生成-->匹配这个过程循环一百遍,最终计算平均时间。如果有大佬觉得不放心的,我在下方放出检测代码,大家可以自行修改测试,拿去即可用!
检测代码如下
class KMP():def __init__(self, ss: str) -> list:
self.length = len(ss)
self.next_lst = [0 for _ in range(self.length)]
self.next_lst[0] = -1
i = 0
j = -1
while i < self.length - 1:
if j == -1 or ss[i] == ss[j]:
i += 1
j += 1
if ss[i] == ss[j]:
self.next_lst[i] = self.next_lst[j]
else:
self.next_lst[i] = j
else:
j = self.next_lst[j]
self.pattern = ss
def match(self, ss:str):
ans_lst = []
j = 0
for i in range(len(ss)):
if ss[i] != self.pattern[j]:
j = self.next_lst[j] if self.next_lst[j] != -1 else 0
if ss[i] == self.pattern[j]:
j += 1
if j == self.length:
return i + 1 - self.length
return -1
class Sunday(object):
def __init__(self, pattern:str):
# 模式串和其长度
self.pattern, self.length = pattern, len(pattern)
# 根据模式串构建的偏移字典
self.shift_dict = {}
# 构建字典
for index, value in enumerate(pattern):
self.shift_dict[value] = self.length - index
def match(self, text:str):
i = 0
text_length = len(text)
text += ''
while i <= text_length - self.length:
j = 0
while self.pattern[j] == text[i + j]:
j += 1
if j >= self.length:
return i
offset = self.shift_dict[text[i+self.length]] if text[i+self.length] in self.shift_dict else self.length + 1
i += offset
return -1
import random
import time
sunday = Sunday('helloworld')
kmp = KMP('helloworld')
kmp_average_time = 0
sunday_average_time = 0
for i in range(100):
ss = ''.join([chr(random.randint(97, 122)) for _ in range(100000)])
st = time.process_time()
sunday.match(ss)
ed = time.process_time()
sunday_average_time += ed - st
st = time.process_time()
kmp.match(ss)
ed = time.process_time()
kmp_average_time += ed - st
print('kmp平均时间: {}'.format(kmp_average_time / 100))
print('sunday平均时间: {}'.format(sunday_average_time / 100))
以上是 Sunday字符串匹配算法比KMP算法快七倍 的全部内容, 来源链接: utcz.com/a/18390.html



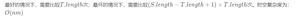
![正则表达式中 [\s\S]* 什么意思 居然能匹配所有字符 [] 不是范围描述符吗?](/wp-content/uploads/thumbs/270159_thumbnail.jpg)

