Python爬取拉勾网爬取几页后就开始报错
引入requests、bs4、fake_useragent,爬取网页时爬取几页就开始在get_content()报错。如果设置的页码是1-10,可以爬取到1-6页的数据;如果设置的页码是8-15,可以爬取到8-12的数据。
def download_page(url): try:
headers = {'User-Agent':UserAgent().random}
r = requests.get(url, headers=headers,timeout=5)
r.raise_for_status()
return r.text
except:
print("download_page错误")
def get_content(html, page):
try:
output = """第{}页 \n 公司{} \n 工资{} 工作地址{} --------------------------------\n"""
soup = BeautifulSoup(html, 'html.parser')
page = str(page)
con = soup.find('div', class_='s_position_list')
con_list = con.find('ul', class_='item_con_list').find_all('li', class_='con_list_item')
print(con_list)
for i in con_list:
company = i.find('div', class_='company_name').find('a').string
money = i.find('span', class_='money').string
address = i.find('span', class_='add').get_text()
save_txt(output.format(page, company, money, address))
except:
print('get-content错误')
爬取的部分内容如下.txt格式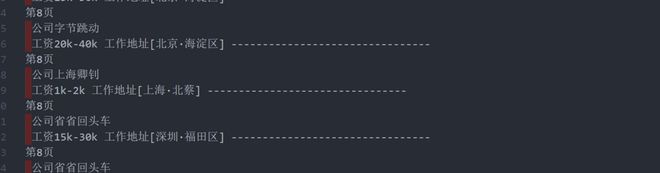
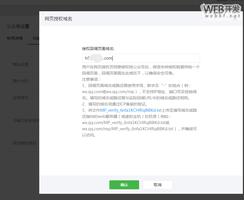
爬取过于频繁会错误,但过会儿又可以进行爬取,请问如何解决
回答:
批量抓取一般建议使用scrapy,像ip代理,频繁抓取报错等等你目前遇到以及未遇到的问题,scrapy已经有成熟的方案。
回答:
一个是需要控制抓取频率,二个是代理ip。
回答:
except Exception as e: print('错误原因', e)
print('get-content错误')
这样写就知道具体是什么,然后再百度google搜
以上是 Python爬取拉勾网爬取几页后就开始报错 的全部内容, 来源链接: utcz.com/a/164358.html