scrapy 遍历url列表 ,循环发送请求 只循环一次的问题
一 问题描述
我把url构成列表作为爬虫请求的入口(由'http://www.bjev520.com/jsp/beiqi/pcmap/do/pcMap.jsp?cityName=省市名'构成)。
对入口地址请求后,每个对象中都还有一层带url的子集合('/jsp/beiqi/pcmap/do/pcmap_Detail.jsp?charingId=ID号'构成)。
我再对子列表的url进行逐个请求并保存详尽信息。这里相当于有两层循环。
但是我现在运行后,程序只能爬取最外层入口url列表第一个对象下的所有信息,第一个对象的所有信息爬去后,没有继续遍历最外层url列表的下一个对象就结束了。

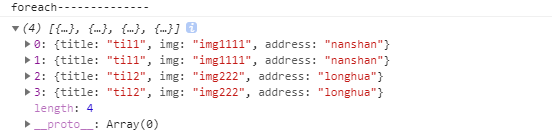
这就是从入口url列表第一个对象请求后获得的真实界面,我们看到第二层的子url集合就在左侧(此处显示了3个)
二 spider代码展示
项目结构
注:正常的用scrapy建立一个爬虫项目,我只是test,所以没有用到item pipelines。
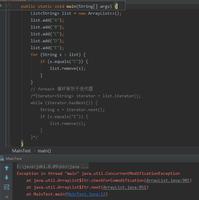
# coding:utf-8import scrapy
class TestSpider(scrapy.Spider):
name = "test"
city_name = ['新疆', '吉林']
url_source = 'http://www.bjev520.com'
base_url = 'http://www.bjev520.com/jsp/beiqi/pcmap/do/pcMap.jsp?cityName={city}'
left_url = 'http://www.bjev520.com/jsp/beiqi/pcmap/pages/pcmap_Left.jsp'
def start_requests(self):
# 用for和字符串插入的方法构成省市链接循环入口
for city in self.city_name:
yield scrapy.Request(url=self.base_url.format(city=city), callback=self.parse_first)
def parse_first(self, response):
# 省市链接入口请求完毕后,这个网站要你继续发起个left_url的链接请求,才能把每个省市下的子列表即是带href的列表获得
yield scrapy.Request(url=self.left_url, callback=self.parse_second)
def parse_second(self, response):
# 获得子列表html页面,把其中带href的每个个体详细页面循环遍历进入并发起请求
message = scrapy.Selector(response).xpath('//a[contains(@href, "/jsp")]/@href').extract()
for piles in message:
yield scrapy.Request(url=(self.url_source+piles), callback=self.parse_content)
def parse_content(self, response):
# 主要是查看遍历子详细页面的数
print('1')
三 运行结果:
从运行结果可以看出,爬虫结束只请求到了最外层入口第一个对象的所有子url就结束了,最外层入口url列表的第二个对象就没再遍历了。
我现在不知道我是哪个地方逻辑除了问题或者scrapy方法思路雍错,使得程序只遍历了一个对象,循环就不再继续了,请大家帮助解答一下,感恩!
回答:
首先,你2个城市的第二层url是同一个,所以被重复检查的filter个屏蔽了一个。
如果不想被屏蔽。
def parse_first(self, response): # 省市链接入口请求完毕后,这个网站要你继续发起个left_url的链接请求,才能把每个省市下的子列表即是带href的列表获得
yield scrapy.Request(url=self.left_url, dont_filter=true, callback=self.parse_second)
以上是 scrapy 遍历url列表 ,循环发送请求 只循环一次的问题 的全部内容, 来源链接: utcz.com/a/164039.html