python 使用 Selenuim怎么抓取动态生成的html内容???
python 使用 Selenuim抓取的网页内容,但是动态生成的部分无法拿到?还有其它办法可以拿到吗
回答:
用selenium执行js是可以往下滚动页面,实现ajax的加载的。
spider.driver.execute_script('window.scrollTo(0, document.body.scrollHeight)')
就好像这个scrapy的语句。
不过selenium有些网站是有防护的。头条就有这种防护,也就是如果用的可视化浏览器可以看到不会加载任何的新闻内容的。
你可以试试在实例化webdriver后加入这条语句
self.driver.execute_cdp_cmd("Page.addScriptToEvaluateOnNewDocument", { "source": """
Object.defineProperty(navigator, 'webdriver', {
get: () => undefined
})
"""})
这个试过对12306有效。
如果不行可以换splash试试。
回答:
你需要了解Selenuim抓取动态内容的机制,即被js解析后的页面内容,大致流程如下
selenium -> webdriver -> chromedriver -> cdp协议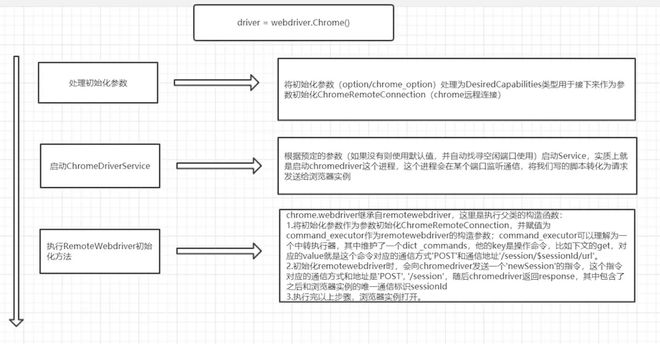
推荐https://learnku.com/articles/...
以上是 python 使用 Selenuim怎么抓取动态生成的html内容??? 的全部内容, 来源链接: utcz.com/a/163889.html