爬虫遇到随机的query string parameters,怎么破?
在分析某个页面时,发现浏览器发出的Request中带有不能理解的参数,貌似是随机的。
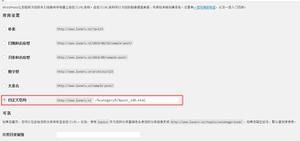
如下所列&符号之后数值:
...02-08&_=0.6968988371025702
...02-05&_=0.2527901983648131
如图:
这些“随机数”是怎么产生的?什么机制?如何解决?
准备用python的Requests来爬,但是目前发现不能构造有效的请求参数。
请各位多多指教。
另,提问标签是猜测的。
回答:
js的随机数吧,避免缓存的,随便给一个应该就行了
回答:
js中用 Math.random()
回答:
python产生随机数(0到0.05) random.uniform(0, 0.05)
回答:
js生成随机的。。。
正则匹配方法名
以上是 爬虫遇到随机的query string parameters,怎么破? 的全部内容, 来源链接: utcz.com/a/163461.html