lxml如何处理内容带html标签的元素?
写爬虫的时候,遇到一个元素,其text里面是html格式:
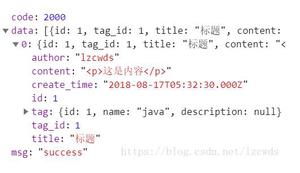
获取这个元素的text_content(),lxml就傻了,出来一大堆东西:
它不能识别出这是内容文本,所以不知道应该停止。
请问这种情况应如何处理?谢谢。
遇到问题的页面在这里:
https://www.cnblogs.com/cate/...
以上是 lxml如何处理内容带html标签的元素? 的全部内容, 来源链接: utcz.com/a/159482.html
写爬虫的时候,遇到一个元素,其text里面是html格式:
获取这个元素的text_content(),lxml就傻了,出来一大堆东西:
它不能识别出这是内容文本,所以不知道应该停止。
请问这种情况应如何处理?谢谢。
遇到问题的页面在这里:
https://www.cnblogs.com/cate/...
以上是 lxml如何处理内容带html标签的元素? 的全部内容, 来源链接: utcz.com/a/159482.html