python如何获得cookies全部内容
如图
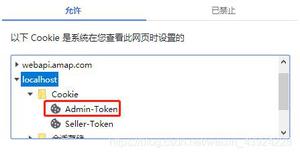
图片上是浏览器抓包的cookies结果,cookies有3个内容,分别是Hm_lpvt,Hm_lvt,__c_Fw7.
我求教的问题,python怎么得到这样的cookies?
我的做法:分别用了requests.session(),urllib2,pycurl三种方法, 却都是只获得了__c_Fw7,另外2个怎么得到呢?
补充:Hm_lpvt的values只保存在浏览器会话,它的值浏览器刷新一次就更改一次。
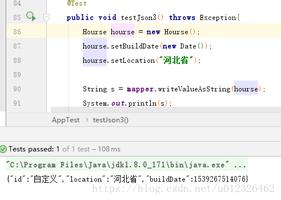
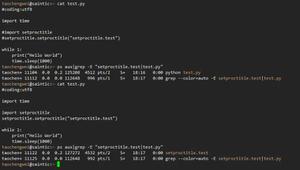
pycurl库得到cookies的截图,__c_18j9,就是上面说的__c_Fw7。
response截图,看不到 set-cookies,或许是我方法不对,才看不到?
百度response的确是有set-cookie
回答:
你可以自己写代码来控制cookie,主要就是看reqsponse的headers中的set-cookie字段,然后把它解析出来,再传到下一次的request的headers中去。
比如下面这个就是我请求www.baidu.com时的response中的set-cookie字段
'BAIDUID=A611EF4EDE31F245A2F0520055218EE2:FG=1; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, BIDUPSID=A611EF4EDE31F245A2F0520055218EE2; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, PSTM=1441330839; expires=Thu, 31-Dec-37 23:55:55 GMT; max-age=2147483647; path=/; domain=.baidu.com, BDSVRTM=0; path=/, BD_HOME=0; path=/, H_PS_PSSID=16415_1455_17156_13245_12824_12867_17105_14951_17000_16935_17004_17072_15592_12247_13932_16969_17051; path=/; domain=.baidu.com'自己解析下,再传到request中去 就行了。
回答:
浏览器会解析 html 然后访问请求页面中的 css 、图片、javascript 等资源,然后运行 js 脚本,会有各种各样的其它请求。
自己写的脚本只会请求一次,并不会解析 html 。
如果开发者把一此 cookies 藏在 js 脚本的请求中的话,你的脚本就会出现缺失 cookies 的情况。
你可以用 chrome 的开发者工具跟踪一下页面载入的所有请求,看下 set-cookies 指令是在哪一个请求中的,然后用脚本模拟。
回答:
参考我在写这个登陆极路由的代码 http://www.cnblogs.com/gayhub/p/5476712.html
必须指定正确的Content-Type,不然取不到COOKIES
抓包工具用fiddler比较好。
以上是 python如何获得cookies全部内容 的全部内容, 来源链接: utcz.com/a/158242.html