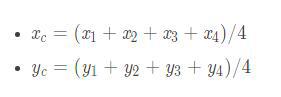如果通过FFT来提高语音质量?

思路:
通过使用快速傅立叶变换来增加语音谐波的幅度,从而提高语音质量:将时域信号转换为频域,然后处理频谱,然后将其转换回时域。
目的:
增加振幅,改善语音质量,确保音频没有削波或失真。将产生的时域信号另存为WAV(16位)并将其包括在提交中。指定增加谐波幅度的量以及声音的变化方式。
下面是获取时域图和频域图的代码,请问如何进行快速傅里叶变换,并且改善音频质量?(如果提高振幅)
# -*- coding: utf-8 -*-import scipy.io.wavfile as wf
import numpy as np
import matplotlib.pyplot as plt
fs, audio = wf.read("/Users/matzoh/Downloads/homework/44khz16bit.wav")
# fs 采样率
# audio 数据
# creating time axis
plt.subplot(2, 1, 1)
time = np.linspace(0, len(audio)/fs, len(audio))
plt.plot(time, audio)
# Adding labels
plt.title('Sound recording')
plt.xlabel('Frequency (Hz)')
plt.ylabel('amplitude')
# plt.plot(time, audio)
# ##freqaxis = np.linspace(0, fs, len(audio))
# creating frequency domain
plt.subplot(2, 1, 2)
fft = np.abs(np.fft.fft(audio))
# plt.plot(freqaxis, fft)
fft2 = fft[0:int(len(fft)/2)]
freqaxis2 = np.linspace(0, fs, len(audio)/2)
fft3 = np.fft.fft(audio)
fft3 = np.abs(fft2)/len(fft2)
fft3 = 20*np.log10(fft2)
plt.plot(fft2)
plt.loglog(fft2)
plt.show()
以上是 如果通过FFT来提高语音质量? 的全部内容, 来源链接: utcz.com/a/157714.html