Python网络编程,为何客户端Socket出现两个连接

import socketimport re
def serve_client(client_socket, client_addr):
request = client_socket.recv(1024)
if request: # recv到数据
q = request.decode("utf-8").splitlines() # 提取请求
print(q) # 看看请求是什么
file_name = re.match(r"[^/]+(/[^ ]*)", q[0]).group(1) # 从请求中提取网址
if file_name == "/":
file_name = "/index.html"
try:
f = open("." + file_name, "rb")
except: # 没有该文件返回404
content = "404 page not found".encode()
response = "HTTP/1.1 404 NOT FOUND\r\n"
response += "\r\n"
client_socket.send(response.encode("utf-8"))
client_socket.send(content)
print("没有该文件")
else: # 有网址对应的文件,发送该文件
content = f.read()
f.close()
response = "HTTP/1.1 200 OK\r\n"
response += "\r\n"
# response += content
client_socket.send(response.encode("utf-8"))
client_socket.send(content)
print("发送成功")
else: # recv不到东西
print("REQUEST为空")
def main():
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
tcp_socket.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1)
tcp_socket.bind(("", 7878))
tcp_socket.listen(128)
while True:
client_socket, client_addr = tcp_socket.accept()
print("新socket:", client_addr)
serve_client(client_socket, client_addr)
if __name__ == '__main__':
main()
打开浏览器,输入127.0.0.1:7878,按回车一次,与TCP服务器建立连接('127.0.0.1', 111111),然后顺利收发数据
控制台输出:
新socket: ('127.0.0.1', 111111)
['GET / HTTP/1.1', 'Host: 127.0.0.1:7878'....]
发送成功
新socket: ('127.0.0.1', 111112)
REQUEST为空
疑问1:为什么会马上accpet到另外一个新连接('127.0.0.1', 111112),这个新连接来自哪里?而且他会经过一段时间后会recv到空数据,这个连接的来源和作用是什么?
疑问2:当我采用网络调试助手来测试,与浏览器建立TCP连接,使用网络调试助手发送数据给浏览器时,浏览器会转圈圈,直到我把网络调试助手关闭连接,浏览器才会接到数据并停止转圈圈,但是为什么使用以上的代码充当服务器发送数据给浏览器时,浏览器却不会转圈圈呢
感谢大佬解惑,万分感激
回答:
你的学习材料有点问题。
希望你找个系统性的书籍或视频学习 socket。
比如
- 《TCP/IP 网络编程》(C语言)
- 《Python 网络编程》(英文原版名:Foundations of Python Network Programming)
- 《UNIX 网络编程》(卷1:套接字联网 API)
至于你的问题。
- 浏览器访问,行为是浏览器控制的。之所以会有两个链接,是因为浏览器访问一个链接(站点)不会只发一个 HTTP Request。你可以通过 F12 看到调试窗口,选择 Network(网络)标签。然后看看发出了几个 HTTP Request。
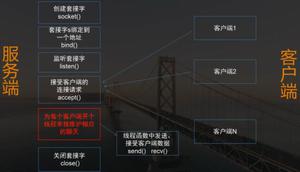
这个问题涉及到,socket 建立链接的过程;客户端先收到服务器的链接建立成功的数据包,然后等待服务器发送内容数据包。
第二点我使用的是简化的白话用词不是专业的名词。实际情况要复杂一些;就算我在这里说了,以这个问题的基础,也不会理解。
简单来说:
这首先要有 TCP/UDP 层的一些基本概念,浏览器是 IP 层+TCP 层。
TCP 层意味着服务器先有应答,建立了 socket 链接(socket 链接是编程的名词,不是 OSI 的名词);然后有数据传输。
浏览器(client)先向服务器建立链接。
然后浏览器是 HTTP 协议,作为 client 它建立链接之后,马上发出 HTTP Request(header),然后等待 server 的 response(即服务端的socket.send(content));
当你使用工具而非代码(进程)发送 content 给浏览器的时候,因为没有主动关闭工具(的 socket),所以浏览器(client)并不知道数据传输已经结束了(涉及到 HTTP 是无状态的特性)。所以浏览器会一直等待数据传输结束(以 socket 关闭为标志)。
总而言之,就算你看懂上面的意思,还是不会真正搞懂 socket 编程这套东西。
你需要有一点基础的 TCP,UDP 协议的知识(不需要很深入)。
所以在前面的三本书学习前,确认你学过了 OSI 网络模型,再专门学 TCP,UDP 协议基础知识。
使用浏览器的同时就默认你在使用 HTTP 协议
所以如果要使用浏览器的话,你还需要基本的 HTTP 协议的知识(《HTTP 权威指南》)。
这样的话遇到 socket 问题你就知道在哪里去找答案了。
这个是基础的东西,遇到这种类型的问题,然后以上网提问找答案的话,就算有人回答,网络的碎片化信息也没有办法帮你建立系统的基础的知识体系。
以上是 Python网络编程,为何客户端Socket出现两个连接 的全部内容, 来源链接: utcz.com/a/157627.html