关于覆盖索引,多列联合索引,不满足最左前缀原则也能命中索引?

有一张 file 表,(shareid,uk,pid) 三个字段建立了联合索引,表数据量大概500万条。
CREATE TABLE `file` ( `id` int(11) NOT NULL AUTO_INCREMENT,
`fs_id` bigint(20) unsigned NOT NULL COMMENT '文件ID',
`filename` varchar(255) COLLATE utf8_unicode_ci NOT NULL COMMENT '文件名',
`shareid` bigint(20) unsigned NOT NULL,
`uk` bigint(20) NOT NULL DEFAULT '0' COMMENT '用户ID',
`pid` varchar(32) CHARACTER SET latin1 COLLATE latin1_bin NOT NULL,
PRIMARY KEY (`id`) USING BTREE,
KEY `idx_share_uk_pid` (`shareid`,`uk`,`pid`) USING BTREE
) ENGINE=InnoDB
现在要通过 pid 查询 id 和 fs_id 两列:
方法一、
使用 pid 作为查询条件进行查询,执行计划显示使用了覆盖索引。
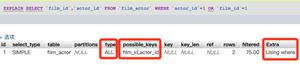
mysql> EXPLAIN SELECT SQL_NO_CACHE `id` FROM file WHERE pid='fRLr9QLMjDKgwkHF0f1lmg' limit 1;+----+-------------+-------+------------+-------+---------------+------------------+---------+------+---------+----------+--------------------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+-------+---------------+------------------+---------+------+---------+----------+--------------------------+
| 1 | SIMPLE | file | NULL | index | NULL | idx_share_uk_pid | 50 | NULL | 5351369 | 10.00 | Using where; Using index |
+----+-------------+-------+------------+-------+---------------+------------------+---------+------+---------+----------+--------------------------+
1 row in set (0.07 sec)
查询 id 使用的实际时间是 1.08 秒
mysql> SELECT SQL_NO_CACHE `id` FROM file WHERE pid='fRLr9QLMjDKgwkHF0f1lmg' limit 1;+---------+
| id |
+---------+
| 5416222 |
+---------+
1 row in set (1.08 sec)
再通过 id 查 fs_id 所用的之间只有 0.08 秒。
mysql> SELECT SQL_NO_CACHE `id`,`fs_id` FROM file WHERE id=5416222;+---------+-----------------+
| id | fs_id |
+---------+-----------------+
| 5416222 | 773216656487988 |
+---------+-----------------+
1 row in set (0.08 sec)
方法二
当企图直接用一次查询查出 id 和 fs_id 时:
mysql> EXPLAIN SELECT SQL_NO_CACHE `id`,`fs_id` FROM file WHERE pid='fRLr9QLMjDKgwkHF0f1lmg' limit 1;+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
| 1 | SIMPLE | file | NULL | ALL | NULL | NULL | NULL | NULL | 5351369 | 10.00 | Using where |
+----+-------------+-------+------------+------+---------------+------+---------+------+---------+----------+-------------+
1 row in set (0.31 sec)
执行计划显示没有用到索引
mysql> SELECT SQL_NO_CACHE `id`,`fs_id` FROM file WHERE pid='fRLr9QLMjDKgwkHF0f1lmg' limit 1;+---------+-----------------+
| id | fs_id |
+---------+-----------------+
| 5416222 | 773216656487988 |
+---------+-----------------+
1 row in set (20.89 sec)
这条语句消耗了 20 秒的时间,将近是上面两条语句消耗时间的和的20倍。
问题:
- 为什么不满足最左前缀原则也能命中覆盖索引?
- InnoDB的查询不就是先从普通索引中查出主键,再利用主键回表去查询其他的列。方法一就是模拟的这个过程,为什么方法二回比方法一慢这么多?
回答:
1、mysql分析器判断当前sql是否能用到索引,方法1不满足最左前缀排除,需要全表扫描;
但发现id和pid都在索引中,正常索引中条数原小于全表条数,所以会直接读取索引记录(也就是覆盖索引)
2、其二,方法1由于不满足最左前缀,也是需要依次扫描idx_share_uk_pid索引所有记录,考虑到索引是按顺序排列,即使前两个字段都需要扫描,但比对到第三个字段时就能快速过滤,类似于for循环中直接continue(有史记载)
3、方法2为什么没走索引,fs_id不在索引列中,即使先走覆盖索引,仍要回表把fs_id查询出来,因此mysql就直接使用全表查询。
最后一点,楼上说的limit 1去掉是没道理的,目测explain出来的结果是一样的
回答:
1.首先 possible_keys 是可能会用到。并不是用到了。
方法1 说明没有用到 树形查找的索引。走了覆盖索引。
2.你的方法1 应该没有回表吧? 因为ID 是 PK 。走了索引覆盖。
方法二应该会走回表的。 不过可以肯定的是 索引覆盖 肯定要比回表快的。但是差距这么大 ,所以 你把方法二的 limit 1 去掉。我觉得速度会快。。。你试下
3.另外rows 5351369 多行。瓶颈应该都在回表这里了。和全表查询没啥区别了
回答:
SELECT SQL_NO_CACHEidFROM file WHERE pid='fRLr9QLMjDKgwkHF0f1lmg' limit 1;查询的id字段本身是主键且pid是联合索引的一部分,所以会直接扫描索引且是覆盖索引。SELECT SQL_NO_CACHEid,fs_idFROM file WHERE pid='fRLr9QLMjDKgwkHF0f1lmg' limit 1;fs_id 不属于联合索引的一部分,所以一定要通过主键反查,自然会慢。
以上是 关于覆盖索引,多列联合索引,不满足最左前缀原则也能命中索引? 的全部内容, 来源链接: utcz.com/a/157470.html