
用python爬取《财富》中国500强数据
修改《财富》世界500强源代码(源代码正确可运行),想要爬取《财富》中国500强的数据却失败,作为一个新入编程的小白实在搞不懂什么原因,想要大神帮忙解答
以下是爬取《财富》世界500强的源代码:
# 导入正则表达式import re
import time
# 导入requests库
import requests
# 导入BeautifulSoup库
from bs4 import BeautifulSoup
# 请求的URL路径,2020年财富世界500强排行榜
url = "http://www.fortunechina.com/fortune500/c/2020-08/10/content_372148.htm"
# 发送GET请求,返回一个响应对象
response = requests.get(url)
# 响应内容编码方式
print("response.encoding = ", response.encoding)
# 响应内容编码方式修改为'utf-8'
response.encoding = 'utf-8'
# 响应内容编码方式
print("response.encoding = ", response.encoding)
# HTTP响应内容的字符串形式,即URL对应的页面内容
text = response.text
print("text = ", text)
# 使用html5lib解析器,以浏览器的方式解析文档,生成HTML5格式的文档
soap = BeautifulSoup(text, "html5lib")
print("soap.text = ", soap)
# 查找符合查询条件的第一个标签节点(tbody)
top500 = soap.find('tbody')
# 以可写方式打开csv文件
# file1 = open('top500.csv', 'w', encoding='utf-8-sig'
file1 = open('top500.csv', 'w', encoding='utf-8')
# 用于测试编码错误的例外
# file1 = open('top500.csv','w')
newLine = ''
i = 0
# 传入正则表达式,通过正则表达式re模块的compile()函数进行匹配
# 找到标签为"td"的信息:全部2020年财富全球500强数据含标签
for tag in top500.findAll(re.compile("^td")):
# print(" tag.string = ", tag.string
i += 1
# 纵向2020年财富全球500强数据,1个公司数据合并一行中..., 以"|"分隔
newLine = newLine + tag.string + "|"
# print("newLine = ", newLine)
if i == 6:
# 2020年财富全球500强数据,1行为1个公司数据,以"|"分隔
print("newLine = ", newLine)
# 单行写入文件
file1.writelines(newLine + "n")
i = 0
newLine = ''
# 关闭文件
file1.close()
代码运行成功且生成一个top500.csv的文件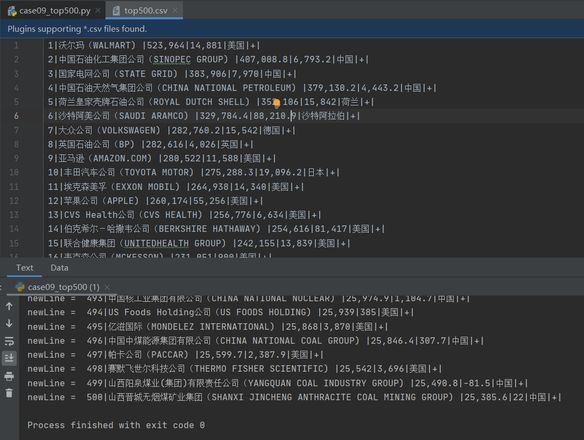
当想要爬取《财富》中国500强是却失败了,以下代码我只更改了相应的链接,其他地方没有更改,程序报错:
# 导入正则表达式import re
import time
# 导入requests库
import requests
# 导入BeautifulSoup库
from bs4 import BeautifulSoup
# 请求的URL路径,2020年财富世界500强排行榜
url = "http://www.fortunechina.com/fortune500/c/2020-07/27/content_369925.htm"
# 发送GET请求,返回一个响应对象
response = requests.get(url)
# 响应内容编码方式
print("response.encoding = ", response.encoding)
# 响应内容编码方式修改为'utf-8'
response.encoding = 'utf-8'
# 响应内容编码方式
print("response.encoding = ", response.encoding)
# HTTP响应内容的字符串形式,即URL对应的页面内容
text = response.text
print("text = ", text)
# 使用html5lib解析器,以浏览器的方式解析文档,生成HTML5格式的文档
soap = BeautifulSoup(text, "html5lib")
print("soap.text = ", soap)
# 查找符合查询条件的第一个标签节点(tbody)
top500 = soap.find('tbody')
# 以可写方式打开csv文件
# file1 = open('top500.csv', 'w', encoding='utf-8-sig'
file1 = open('top500.csv', 'w', encoding='utf-8')
# 用于测试编码错误的例外
# file1 = open('top500.csv','w')
newLine = ''
i = 0
# 传入正则表达式,通过正则表达式re模块的compile()函数进行匹配
# 找到标签为"td"的信息:全部2020年财富全球500强数据含标签
for tag in top500.findAll(re.compile("^td")):
# print(" tag.string = ", tag.string
i += 1
# 纵向2020年财富全球500强数据,1个公司数据合并一行中..., 以"|"分隔
newLine = newLine + tag.string + "|"
# print("newLine = ", newLine)
if i == 6:
# 2020年财富全球500强数据,1行为1个公司数据,以"|"分隔
print("newLine = ", newLine)
# 单行写入文件
file1.writelines(newLine + "n")
i = 0
newLine = ''
# 关闭文件
file1.close()
运行结果如下: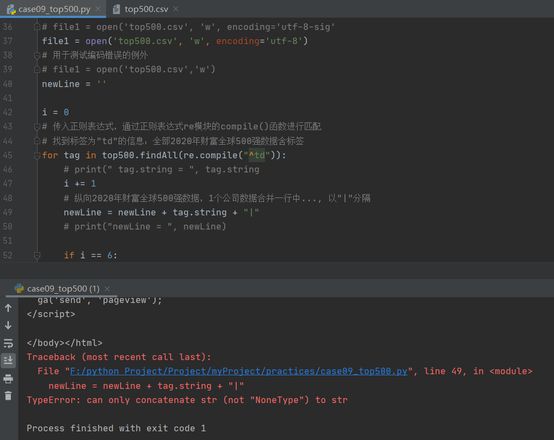
搞不太懂为什么,想要大神能够帮忙解答修改下!!
回答:
这个报错很明显,在拼接字符串上报的错误,也就是49行
newLine = newLine + tag.string + "|"拼接字符串中,出现了一个NoneType类型,所以报错了
拼接时,有三个newLine、tag.string、“|”,newLine和"|"不会有问题,那问题出在tag.string上.
嗯,那直观点,也不用Debug了,就加一个print来看
print("tag.string:",tag.string) newLine = newLine + tag.string + "|"
执行输出
tag.string: None // 可以明显看到结果了Traceback (most recent call last):
File "/home/zhaow/PycharmProjects/Python_Course/1.笔记/2.Python函数.py", line 41, in <module>
newLine = newLine + tag.string + "|"
TypeError: can only concatenate str (not "NoneType") to str
修改下代码
if tag.string is not None: newLine = newLine + tag.string + "|"
再次执行就不会报错了。
以上是 用python爬取《财富》中国500强数据 的全部内容, 来源链接: utcz.com/a/156899.html




