
Python随机采样及概率分布(二)
前言:
之前的《Python中的随机采样和概率分布》我们介绍了Python中最简单的随机采样函数。接下来我们更进一步,来看看如何从一个概率分布中采样,我们以几个机器学习中最常用的概率分布为例。
1. 二项(binomial)/伯努利(Bernoulli)分布
1.1 概率质量函数(pmf)

二项分布P(X=x; n, p)可以表示进行独立重复试验n次,每次有两成功和失败可能结果(分别对应概率p和1−p),共成功x次的概率。
1.2 函数原型
random.binomial(n, p, size=None)
参数:
n: int or array_like of ints 对应分布函数中的参数 n,>=0,浮点数会被截断为整形。p: float or array_like of floats 对应分布函数参数p, >=0并且<=1。size: int or tuple of ints, optional 如果给定形状为(m,n,k),那么m×n×k个随机样本会从中抽取。默认为None,即返回一个一个标量随机样本。
返回:
out: ndarray or scalar 从带参数的概率分布中采的随机样本,每个样本表示独立重复实验n次中成功的次数。
1.3 使用样例
设进行独立重复实验10次,每次成功概率为0.5,采样样本表示总共的成功次数(相当于扔10次硬币,正面朝上的次数)。总共采20个样本。
import numpy as npn, p = 10, .5
s = np.random.binomial(n, p, 20)
print(s) # [4 5 6 5 4 2 4 6 7 2 4 4 2 4 4 7 6 3 5 6]
可以粗略的看到,样本几乎都在5周围上下波动。我们来看一个有趣的例子。一家公司钻了9口井,每口井成功的概率为0.1,所有井都失败了,发生这种情况的概率是多少?我们总共采样2000次,来看下产生0结果的概率。
s = sum(np.random.binomial(9, 0.1, 20000) == 0)/20000.print(s) # 0.3823
可见,所有井失败的概率为0.3823,这个概率还是蛮大的。
2. 多项(multinomial)分布
2.1 概率质量函数(pmf)

也就是说,多项分布式二项分布的推广:仍然是独立重复实验n次,但每次不只有成功和失败两种结果,而是k种可能的结果,每种结果的概率为pi。多项分布是一个随机向量的分布,x=(x1,x2,...,xk)意为第i种结果出现xi次,P(X=x; n, p)也就表示第i种结果出现xi次的概率。
2.2 函数原型
random.multinomial(n, pvals, size=None)
参数:
n: int 对应分布函数中的参数 n。pvals: sequence of floats 对应分布函数参数p, 其长度等于可能的结果数k,并且有0⩽pi⩽1。size: int or tuple of ints, optional 为输出形状大小,因为采出的每个样本是一个随机向量,默认最后一维会自动加上k,如果给定形状为(m,n),那么m×n个维度为k的随机向量会从中抽取。默认为None,即返回一个一个k维的随机向量。
返回:
out: ndarray 从带参数的概率分布中采的随机向量,长度为可能的结果数k,如果没有给定 size,则shape为 (k,)。
2.3 使用样例
设进行独立重复实验20次,每次情况的概率为1/6,采样出的随机向量表示每种情况出现次数(相当于扔20次六面骰子,点数为0, 1, 2, ..., 5出现的次数)。总共采1个样本。
s = np.random.multinomial(20, [1/6.]*6, size=1)print(s) # [[4 2 2 3 5 4]]
当然,如果不指定size,它直接就会返回一个一维向量了
s = np.random.multinomial(20, [1/6.]*6)print(s) # [4 1 4 3 5 3]
如果像进行多次采样,改变 size即可:
s = np.random.multinomial(20, [1/6.]*6, size=(2, 2))print(s)
# [[[4 3 4 2 6 1]
# [5 2 1 6 3 3]]
# [[5 4 1 1 6 3]
# [2 5 2 5 4 2]]]
这个函数在论文<sup>[1]</sup>的实现代码<sup>[2]</sup>中用来设置每一个 client分得的样本数:
for cluster_id in range(n_clusters):weights = np.random.dirichlet(alpha=alpha * np.ones(n_clients))
clients_counts[cluster_id] = np.random.multinomial(clusters_sizes[cluster_id], weights)
# 一共扔clusters_sizes[cluster_id]次筛子,该函数返回骰子落在某个client上各多少次,也就对应着该client应该分得的样本数
3.均匀(uniform)分布
3.1 概率密度函数(pdf)
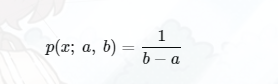
均匀分布可用于随机地从连续区间[a,b)内进行采样。
3.2 函数原型
random.uniform(low=0.0, high=1.0, size=None)
参数:
low: float or array_like of floats, optional 对应分布函数中的下界参数 a,默认为0。high: float or array_like of floats 对应分布函数中的下界参数 b,默认为1.0。size: int or tuple of ints, optional 为输出形状大小,如果给定形状为(m,n,k),那么m×n×k的样本会从中抽取。默认为None,即返回一个单一标量。
返回:
out: ndarray or scalar 从带参数的均匀分布中采的随机样本
3.3 使用样例
s = np.random.uniform(-1,0,10)print(s)
# [-0.9479594 -0.86158902 -0.63754099 -0.0883407 -0.92845644 -0.11148294
# -0.19826197 -0.77396765 -0.26809953 -0.74734785]
4. 狄利克雷(Dirichlet)分布
4.1 概率密度函数(pdf)
P(x;α)∝∏i=1kxαi−1ix=(x1,x2,...,xk),xi>0,∑i=1kxi=1α=(α1,α2,...,αk).αi>0
4.2 函数原型
random.dirichlet(alpha, size=None)
参数:alpha: sequence of floats, length k 对应分布函数中的参数向量 α,长度为k。size: int or tuple of ints, optional 为输出形状大小,因为采出的每个样本是一个随机向量,默认最后一维会自动加上k,如果给定形状为(m,n),那么m×n个维度为k的随机向量会从中抽取。默认为None,即返回一个一个k维的随机向量。
返回:
out: ndarray 采出的样本,大小为(size,k)。
4.3 使用样例
设α=(10,5,3)(意味着k=3),size=(2,2),则采出的样本为2×2个维度为k=3的随机向量。
s = np.random.dirichlet((10, 5, 3), size=(2, 2))print(s)
# [[[0.82327647 0.09820451 0.07851902]
# [0.50861077 0.4503409 0.04104833]]
# [[0.31843167 0.22436547 0.45720285]
# [0.40981943 0.40349597 0.1866846 ]]]
这个函数在论文[1]的实现代码[2]中用来生成符合狄利克雷分布的权重向量
for cluster_id in range(n_clusters):# 为每个client生成一个权重向量,文章中分布参数alpha每一维都相同
weights = np.random.dirichlet(alpha=alpha * np.ones(n_clients))
clients_counts[cluster_id] = np.random.multinomial(clusters_sizes[cluster_id], weights)
到此这篇关于Python随机采样及概率分布(二)的文章就介绍到这了,更多相关Python随机采样及概率分布内容请搜索以前的文章或继续浏览下面的相关文章希望大家以后多多支持!
以上是 Python随机采样及概率分布(二) 的全部内容, 来源链接: utcz.com/z/257006.html




