python实现简单的新闻文章归类
上一节我们提到了三个非常经典的问题,他们分别是:
- 二分类问题(电影评论好坏倾向性判断)
- 多分类问题(将新闻按照主题分类)
- 回归问题(根据房地产数据估算房地产价格)
实际的背景是这样的:路透社将新闻分为了 46 个互斥的大类,一篇文章可能归属于其中的一类或多类,我们需要做的就是将新闻报道自动归类。问题不是与上一篇一样的非黑即白、非此即彼类型的判断了,而是考虑每篇文章是不同的各个分类的概率。稍加思考,我们就会发现这个问题虽然与上个问题有如上的不同,但是其相同部分其实更多,我们只需根据不同的特殊情况进行一定的更改就好了。具体的内容下面分别说明,相同部分简略说明,如有疑问请阅读上篇文章:
- 数据与前文一样,都可进行相同的初始化,即按照索引,将文章数据处理为单词索引的序列串,用 one-hot 方法处理向量使其可以为网络所处理。有区别的是这一次的结果,label 也需要处理,因为结果不是两个值,也是一个张量了。
- 仍然采用 relu 激活的中间层,投射的空间维度不能是 16 了,这里改成 64,原因是因为结果太多,用十六个维度去包含六十四个结果的信息,会在训练的过程中丢失过多的信息,导致准确率会有较大的下降,因此这里采用 64 层。
- 对于损失函数,上一篇的 binary_crossentropy 就不够用了,需要修改损失函数,sparse_categorical_crossentropy 适用于多分类情况的损失函数,前者与后者之间只是接口上的不同,需要注意一下。
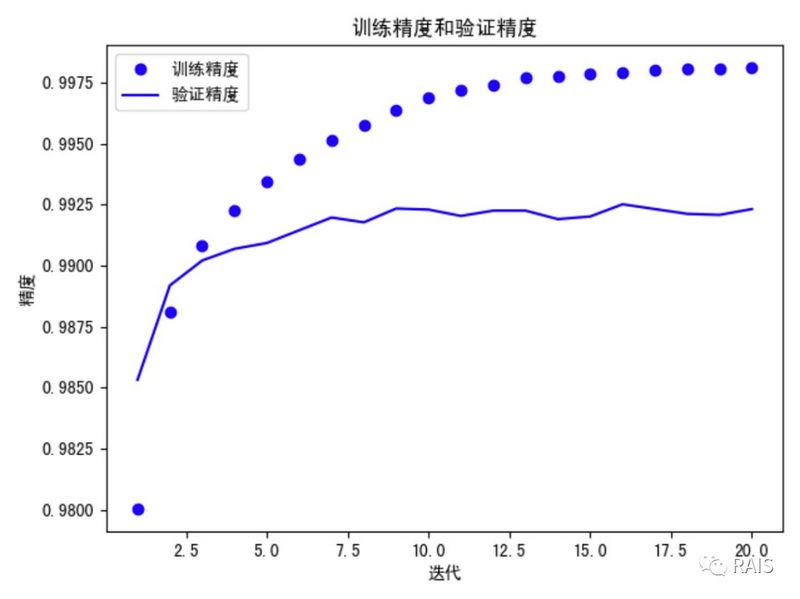
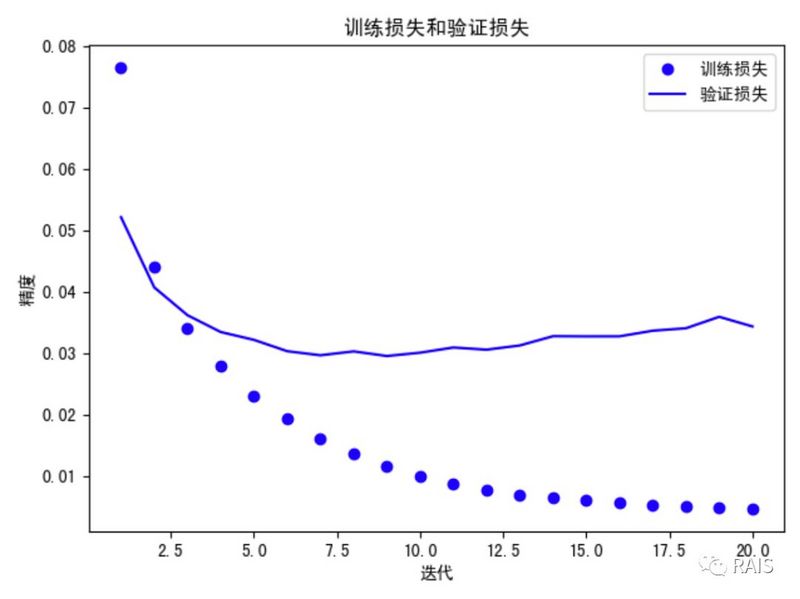
- 我们仍旧训练 20 次,也出现了上次的问题,过拟合,只不过这一次是出现在第九次的迭代后,因此我们将迭代此处改为九,重新训练网络。图我放在了代码的前面,可以查看:
- 最后一层的网络,激活不应该用 sigmoid,而应该用 softmax,这样才能输出类别上的概率分布。这一点与二分类分布不一样。
- 最后启动训练网络,进行训练,大致可以达到 80% 的准确度。
- 到这里就结束了,但是还有两个问题值得关注一下。我们用随机分类器随机对文章进行分类,准确率是 19%,上一篇中的二分类的可以达到 50%。我们最后每条测试数据得到的结果是一个 46 维度的向量,是各个类别的概率值,其相加为 1(由于运算精度问题,最后其实是跟 1 有可能有一个很小的偏差),最大概率的类别就是我们的预测类别。相关代码已经在最后给出,可以参考查看。
没有更多新的东西了,就简单介绍这些,图片代码如下给出:
#!/usr/bin/env python3import copy
import numpy as np
from keras import layers
from keras import models
from keras.datasets import reuters
def classify():
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(num_words=10000)
# print('训练集长度:', len(train_data))
# print('测试集长度:', len(test_data))
# print(train_data[10])
# 查看原文
# word_index = reuters.get_word_index()
# reverse_word_index = dict([(value, key) for (key, value) in word_index.items()])
# decoded_newswire = ' '.join([reverse_word_index.get(i - 3, '?') for i in train_data[0]])
# print(decoded_newswire)
# 输出某一标签的分类索引
# print(train_labels[3])
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
# 将编码转换成张量
# y_train = np.array(train_labels)
# y_test = np.array(test_labels)
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)
# one_hot_train_labels = to_categorical(train_labels)
# one_hot_test_labels = to_categorical(test_labels)
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])
# model.compile(optimizer='rmsprop', loss='sparse_categorical_crossentropy', metrics=['acc'])
# model.compile(optimizer='rmsprop', loss='binary_crossentropy', metrics=['acc'])
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
history = model.fit(partial_x_train, partial_y_train, epochs=9, batch_size=512, validation_data=(x_val, y_val))
# 图片输出测试结果
# loss = history.history['loss']
# val_loss = history.history['val_loss']
# epochs = range(1, len(loss) + 1)
# plt.plot(epochs, loss, 'bo', label='训练损失')
# plt.plot(epochs, val_loss, 'b', label='验证损失')
# plt.title('训练损失和验证损失')
# plt.xlabel('迭代')
# plt.ylabel('精度')
# plt.legend()
# plt.show()
# plt.clf()
# acc = history.history['acc']
# val_acc = history.history['val_acc']
# plt.plot(epochs, acc, 'bo', label='训练精度')
# plt.plot(epochs, val_acc, 'b', label='验证精度')
# plt.title('训练精度和验证精度')
# plt.xlabel('迭代')
# plt.ylabel('精度')
# plt.legend()
# plt.show()
results = model.evaluate(x_test, one_hot_test_labels)
# 80%
print(results)
# 如果是随机分类器
test_labels_copy = copy.copy(test_labels)
np.random.shuffle(test_labels_copy)
hits_array = np.array(test_labels) == np.array(test_labels_copy)
# 19%
print(float(np.sum(hits_array)) / len(test_labels))
# 预测值
predictions = model.predict(x_test)
print(predictions[10].shape)
print(np.sum(predictions[10]))
print(np.argmax(predictions[10]))
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
if __name__ == "__main__":
classify()
以上是 python实现简单的新闻文章归类 的全部内容, 来源链接: utcz.com/a/15048.html