【Web前端问题】在javascript中,Function对象的本质是什么?
这个问题最近一直困扰着我,我感到自己无法理解Function对象的本质是什么。
如果说是一个普通的js变量。比如
var a = 5;我可以把它理解为开辟了某个内存给变量a,并把内容赋值为5。
那么如果我定义了一个函数:
var fn = function() { console.log(this); };它在内存中又是怎么存储的?
其实把我的问题再具体话一点,可以这样问:
1. Function对象中如何保存作用域链的上下文(context)
2. Function对象的函数体是以字符串的形式存储下来的吗?
再看看下面这个例子:
var fn;(function(){
var a = 5;
fn = function () {
console.log(a++);
};
})();
fn();
这是个常见的闭包例子,就拿这个例子来说,Function对象是如何把变量a保存在自己的上下文环境中的呢?
首先感谢大家热情的回答,我再补充说明一下:
我主要的问题是Function在解释器引擎(比如Google V8)里是以怎样的形式实现的?是把函数体以字符串的形式存储下来,并在执行时以类似eval方法来调用它,或者还是其他方式?所以我的实际问题可能比较底层一点。
回答:
在JS中,Function对象就是Function对象。
在引擎中,随便它怎么实现都可以,只要遵照ECMAScript Spec就行了。
不过只要不是玩具引擎,就肯定不会把代码作为字符串存储,到执行到函数时再去解析的。
要理解这个问题,你需要定个目标,你要理解到什么样的深度呢?
我有个建议,就是不要把问题描述得多么底层。这样除了提高B格之外,其实无助于理解问题。这个问题是一个语义上的问题,而非实现上的问题,不定非要你会C++、汇编才能理解。
你要知道Closure、This这些对象是如何传给函数的,即你说的闭包变量是如何传给函数的。你只需要参照ECMAScript Spec中「Creating Function Objects」、「Executable Code and Execution Contexts」这些章节就行了。
伪代码其实就是这样,对于下面的代码:
var fn;(function(){
var a = 5;
fn = function () {
console.log(a++);
};
})();
fn();
经过解析,会变成类似下面的对象:
var fn;var RANDOM_LAMBA_1={
FormalParameterList:[],
Scope:{fn:&fn}, //假设用&表示变量的地址
Code:`
var a = 5;
fn ={
FormalParameterList:[],
Code:"console.log(a++)",
Scope:{a:&a}
};
return fn;
`,
};
RANDOM_LAMBA_1.Call(this,[]);
//Call方法大概如下:
function Call(thisObject,args) {
var context={},fn=this; //this是Function对象
fn.FormalParameterList.zip(args).forEach(function (a) {
context[a[0]]=&a[1];
});
context.arguments=args;
context.this=thisObject;//将this当成一个普通变量理解就行了
with(context,fn.Scope) {
eval(fn.Code);
}
}
至于引擎中怎么实现的,展开来太多了。理解这些至少需要理解 SouceCode => Tokens => AbstractSyntaxTree .....=> JIT Code 这个流程。将代码转换成抽象语法树的部分在最初JS加载解析时就已经执行了,不然怎么能不执行函数就能报告语法错误呢?虽然Spec用eval(code)这种方式抽述,但解释器实现显然最多只需要直接遍历已经Parse过后的Tree就行了,绝不会再去读取函数的FunctionBody的字符串解析执行的。如果还想更深入地理解,还不如直接去读编译原理。
回答:
Javascript 中变量可以存放两种类型的值,一种为原始值(primitive value),如 Undefined, Null, Boolean, Number, String。这类值存放在栈内部,每赋值一次就创建一个新的拷贝。另一种为引用值(reference value),这类值存在堆内存中,只能通过引用赋值。
举例说明:
var a = 'test';//原始值var b = function() {}; //引用值
我们来测试下:
var a = 'test';//原始值var b = function() {}; //引用值
b.a = 'test';
function change(m, n) {
m = 'change';
n.a = 'change';
}
change(a, b);
现在变量 a 仍然是 test,但是 变量 b 的属性 a 的值则已经为 change,这也就是说前者相当于是拷贝了一份值,而后者则是引用赋值。
而闭包问题我是这样理解的,因为 Javascript 只有两种作用域,一是全局作用域,二是函数作用域,它是没有块级作用域的。所以闭包的出现就相当于利用一个匿名函数的壳模拟出一个块级作用域。举个更明显的闭包例子:
for(var i = 0; i < 10; i++) { (function(e) {
setTimeout(function() {
console.log(e);
}, 1000);
})(i);
}
联系上面的知识,这里往匿名函数内部传的参数将会被拷贝一份,也就是说循环没执行一次就拷贝变量 i 的值到匿名函数内部。
这里如果没有闭包的话:
for(var i = 0; i < 10; i++) { setTimeout(function() {
console.log(i);
}, 1000);
}
由于变量 i 直接暴露在全局作用域内,当调用 console.log 函数开始输出时,这是循环已经结束,所以会输出10个10。
这是我对题主问题的理解,希望能对题主有帮助,可能还有不完善的地方,我打算写篇博文好好总结下。:)
回答:
JS里有两个常见的难点,其一是原型继承,其二是闭包,前者涉及原型链而后者涉及作用域链(Scope Chain)
function对象保存了闭包中的信息,这个说法是不确切的,应该说,function形成的scope chain阻止了闭包中变量被释放,从而使它再次被执行时仍能保留上下文
我们打开一个干净无插件的Chrome,访问about:blank,打开F12开Profile当中的Record Heap Allocation功能(记录内存分配?),然后把题主的代码稍微改得更消耗内存一些,改成定时爆炸方便我们抓情况
var fn;setTimeout(function(){
var a = new Array(1000).join('long text');
fn = function () {
console.log(a);
};
}, 3000);
回车执行代码,3秒内点record,等函数执行会看到分配了若干内存,停止录制(大圆点),在窗口中可以看到被分配的各种对象,我们看看那个很长的字符串,在string类型里面一下子就能找到
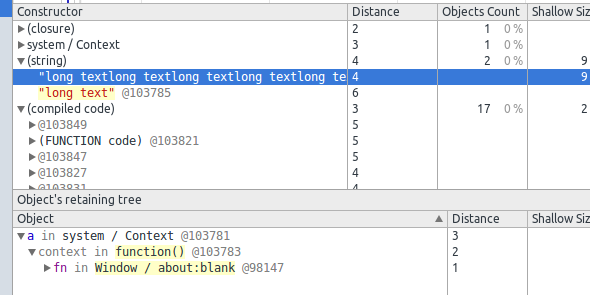
正好我们也看见了另一个没有名字的字符串,看看两者的区别
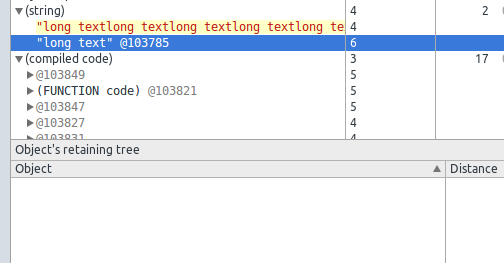
区别很明显,retaining tree 相当于对象和window object联系的路径,在GC时,浏览器会试图寻找内存中retaining tree为空,或者说引用计数为零的对象予以回收。JS的特殊之处就在于,除了显示的对象属性(fn in Window)之外,函数对象对其闭包所有的变量也都算作引用计数(context in function)
换句话说,不是函数对象在保存了上下文的数据,而是函数对象保持了对上下文的引用,阻止GC回收上下文中的数据。
至于函数体在内存中的形式,就是一个更复杂的话题了,之前看得那篇文章找不到了我简单说说我记得的东西吧,现代JS引擎都是JIT实时优化的,首先函数刚被创建的时候,经过词法分析等步骤形成了最开始能跑的第一份函数体,由于JS的特性,其二进制代码中会有非常多的类型探测、判断等逻辑,执行效率非常低,然后函数被执行时,除了拿函数体出来执行之外,JS引擎会首先会记录下这个函数被执行了,其次还会跟踪其输入参数的类型,函数每被执行一定次数,JS引擎就会尝试优化一次函数体,根据之前记录的各种信息来进行优化,也就是说执行次数越多,参数类型越一致,那么函数体在内存中的优化程度就越高,甚至最后可以逼近C的性能。
打比方的话JS代码
function my(obj) { return obj.toString(); }最开始可能内存里长这样
name: mysource: ...(源代码)
body:
return get(obj, toString).call obj
get:
if hasOwn(obj, toString)
return obj{toString}
else
proto = obj{__proto__}
while proto is not null && !hasOwn(proto, toString)
proto = proto{__proto__}
if !hasOwn(proto, toString)
throw object has no toString
return proto{toString}
然后my(3) 1000次以后可能就变成了
name: mysource: ...(源代码)
body:
if(obj is simple number)
return body_number()
else
return body_slow()
numberToString: Number.prototype.toString
body_number:
return numberToString.call obj
body_slow:
return get(obj, toString).call obj
get:
if hasOwn(obj, toString)
return obj{toString}
else
proto = obj{__proto__}
while proto is not null && !hasOwn(proto, toString)
proto = proto{__proto__}
if !hasOwn(proto, toString)
throw object has no toString
return proto{toString}
总之就是运行次数越多,函数体在内存中被优化得越激进
把之前看的那片文章翻了出来 http://djt.qq.com/article/view/489 QQ浏览器的开发写的
关于字节码的部分随便看看就好,V8已经不产生字节码了,随着V8的开源,别家引擎迟早会跟进。
我主要想说的就是JIT热点跟踪那部分,也就是『运行次数越多,函数体就会被越激进地优化』,至于例子里的类型推断优化,只是判断为热点后优化的一种而已,实际上优化的手段会有很多,展开循环/循环不变量/内联等等……类型推断是弱类型语言特有的一种优化方式
回答:
我不懂 C++(Google V8 的实现语言),不过我看过为 Node.js 编写 C++ extensions 的文章,其中有提到过:V8 把 Javascript 代码编译成机器语言来执行,并且可以使用 C++ 来模拟编译的过程。于是我找了找类似的源代码,比如像下面这一段:
#include <v8.h>#include <iostream>
#include <string>
using namespace v8;
int main(int argc, char* argv[]) {
// Create a stack-allocated handle scope.
HandleScope handle_scope;
// Create a new context.
Persistent<Context> context = Context::New();
//context->AllowCodeGenerationFromStrings(true);
// Enter the created context for compiling and
// running the hello world script.
Context::Scope context_scope(context);
Handle<String> source;
Handle<Script> script;
Handle<Value> result;
// Create a string containing the JavaScript source code.
source = String::New("function test_function() { var match = 0;if(arguments[0] == arguments[1]) { match = 1; } return match; }");
// Compile the source code.
script = Script::Compile(source);
// Run the script to get the result.
result = script->Run();
// Dispose the persistent context.
context.Dispose();
// Convert the result to an ASCII string and print it.
//String::AsciiValue ascii(result);
//printf("%s\n", *ascii);
Handle<v8::Object> global = context->Global();
Handle<v8::Value> value = global->Get(String::New("test_function"));
Handle<v8::Function> func = v8::Handle<v8::Function>::Cast(value);
Handle<Value> args[2];
Handle<Value> js_result;
int final_result;
args[0] = v8::String::New("1");
args[1] = v8::String::New("1");
js_result = func->Call(global, 2, args);
String::AsciiValue ascii(js_result);
final_result = atoi(*ascii);
if(final_result == 1) {
std::cout << "Matched\n";
} else {
std::cout << "NOT Matched\n";
}
return 0;
}
所以你想的没有错,看起来的确是保存为字符串再编译执行的。水平有限,只能帮到这里了,建议你找找为 Node.js 编写 C++ 扩展的文章,那些会对底层的编译/调用/执行等有更多深入的讲解。
另外我推荐你阅读一个博客系列:A Tour of V8,并且还有翻译质量不错的中文版,或许能回答你更多的疑问。
以上是 【Web前端问题】在javascript中,Function对象的本质是什么? 的全部内容, 来源链接: utcz.com/a/144137.html