FileReader:前端读取本地文件
故事背景
昨天下午被问到一个问题:oss 对象存储里边由于有些图片被共享,导致上传了很多的重复的图片或者文件,有没有办法在上传之前判断一下这个文件是否被上传过,如果上传过直接去后端拿存储的地址行不行。
当时被问到的时候,第一反应是根据file的文件类型名称和大小生成一个MD5,后来被否决了,加入文件改了名字的话,这个文件还是会被上传上去
然后通过一天的调研,学习了这个之前没有用过的FileReader对象,顺便被他的其他方法给吸引住了,今天这里分享一下
是什么FileReader
FileReader 对象允许Web应用程序异步读取存储在用户计算机上的文件(或原始数据缓冲区)的内容,使用File或Blob
Blob 对象表示一个不可变、原始数据的类文件对象。Blob 表示的不一定是JavaScript原生格式的数据。
File 接口基于Blob,继承了 blob 的功能并将其扩展使其支持用户系统上的文件。") 对象指定要读取的文件或数据。
其中File对象可以是来自用户在一个 input 元素用于为基于Web的表单创建交互式控件,以便接受来自用户的数据; 可以使用各种类型的输入数据和控件小部件,具体取决于设备和user agent元素上选择文件后返回的FileList对象,也可以来自拖放操作生成的DataTransfer对象,还可以是来自在一个HTMLCanvasElement上执行mozGetAsFile()方法后返回结果。(MDN)
说白了就是FileReader对象可以对内存中的数据进行操作
然后需要知道一个重点就是
FileReader仅用于以安全的方式从用户(远程)系统读取文件内容 它不能用于从文件系统中按路径名简单地读取文件。
也就是说他是不可以直接用本地的路径去读取文件的,可以请求后端的资源,来读取对应的文件,或者前端以一个比较安全的方式读取文件,常见的比如说input的文件上传
FileReader 的属性
打印一下 如图

EMPTY: 0LOADING: 1
DONE: 2
这三个是对象实例的状态,分别是未读取文件,正在读取和读取完毕
readyState: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)] result: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)]
error: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)]
然后这三个属性
- readyState,这个是获取当前对象实例的状态
- result,这个是读取文件成功之后的返回值,具体的返回值是根据,你调用的对象实例的方法而返回的,下边我会讲一下FileReader的方法的具体使用
- error,显而易见,报错的时候的信息
onloadstart: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)] onprogress: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)]
onload: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)]
onabort: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)]
onerror: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)]
onloadend: [Exception: TypeError: Illegal invocation at FileReader.invokeGetter (:1:142)]
- onloadstart 读取开始时触发,这里可以做一些常用的处理 比如加载loading什么的
- onprogress 这个事件就比较让人喜欢了,这个方法会在文件被读取的过程中被触发,每大概
11927552字节左右会被触发一次,这个里边会反给一个ProgressEvent 对象,这个对象里边有本次读取文件的最大字节数和已经读取完毕的字节数,可以用来做进度条什么的 - onload 这个事件是文件读取成功的时候触发 ,在这里里边可以使用上边说道的实例上边的result属性,查看你操作的函数的对应的内容
- onabort 读取文件被终端的时候触发,与之对应的有一个中断读取的方法
- onerror 读取文件失败的时候触发
- onloadend 读取文件 不管失败还是成功都会触发这个方法,这个方法的执行时机在onload方法之后
FileReader 的方法
readAsDataURL, 这个方法会返回一个你得到的这个对象的一个base64的地址,但是这个地址,你会发现你的文件越大,这个地址就越长,其实这个地址是一个Base64编码的文件数据字符串
然后之前说了FileReader所有的操作都是异步的,所以你并不能像下边这样获取返回值
let fileReader = new FileReader() let url = fileReader.readAsDataURL(file.file)
console.log(url)
这样是打印不出来的,你需要在他自身的处理事件上边回调获取
let fileReader = new FileReader() fileReader.readAsDataURL(file.file)
fileReader.onload=()=>{
console.log(fileReader.result)
}
回调结果在对象实例的result属性上边,上边有说过
readAsBinaryString开始读取指定的Blob中的内容。一旦完成,result属性中将包含所读取文件的原始二进制数据。
这个方法获取的结果是原始二进制数据,不能直接使用,还需要做一些转换或者使用标签什么得才能用,打印出来大概是这样的

abort这个是中断文件的读取,比如你觉得这个读取的事件有点长,再或者在某个特定情况下你希望他停下来,那么这个时候可以使用这个方法中断他,并且使用这个方法之后fileReader对象的状态是DONE 也就是说可以在onload里边去获取已经读取的数据
readAsArrayBuffer
- 最后这两个是我今天用到的方法
readAsArrayBuffer开始读取指定的Blob中的内容, 一旦完成, result 属性中保存的将是被读取文件的ArrayBuffer数据对象.- 这个ArrayBuffer上边有mdn的传送门可以看下,或者看一下阮一峰老师的es6最下边的讲解,他是一个字节数组,用来表示通用的、固定长度的原始二进制数据缓冲区
- 他不能直接被操作,你可以用对应的
TypedArray接口或者DataView的接口来操作他,这是一个对二进制字节数据操作的底层接口,我这里使用了TypeArray
- TypeArray的常用构造函数
Int8Array:8 位有符号整数,长度 1 个字节。Uint8Array:8 位无符号整数,长度 1 个字节。Uint8ClampedArray:8 位无符号整数,长度 1 个字节,溢出处理不同。Int16Array:16 位有符号整数,长度 2 个字节。Uint16Array:16 位无符号整数,长度 2 个字节。Int32Array:32 位有符号整数,长度 4 个字节。Uint32Array:32 位无符号整数,长度 4 个字节。Float32Array:32 位浮点数,长度 4 个字节。Float64Array:64 位浮点数,长度 8 个字节。
好,看到这里,之前没有接触过的同学是不是脑瓜子嗡嗡的。。没关系 我昨天我也嗡嗡的。。。
简单扼要的说一下就是说,上边列出来的这九个构造函数,都会根据你传进去的参数,生成一个对应的数组,然后这些数组统称为TypeArray视图,这个数组包含了所有的数组的方法和属性,你可以像数组一样去操作他们,一会我会在下边打印一下他们的结果,看一下就知道了
- 然后上边说的
DataView,简单说一下这个DataView是和TypedArray配套使用的,因为DataView的参数是接受一个TypedArray对象,具体方法如下 - 读取
getInt8:读取 1 个字节,返回一个 8 位整数。getUint8:读取 1 个字节,返回一个无符号的 8 位整数。getInt16:读取 2 个字节,返回一个 16 位整数。getUint16:读取 2 个字节,返回一个无符号的 16 位整数。getInt32:读取 4 个字节,返回一个 32 位整数。getUint32:读取 4 个字节,返回一个无符号的 32 位整数。getFloat32:读取 4 个字节,返回一个 32 位浮点数。getFloat64:读取 8 个字节,返回一个 64 位浮点数。
- 写入
setInt8:写入 1 个字节的 8 位整数。setUint8:写入 1 个字节的 8 位无符号整数。setInt16:写入 2 个字节的 16 位整数。setUint16:写入 2 个字节的 16 位无符号整数。setInt32:写入 4 个字节的 32 位整数。setUint32:写入 4 个字节的 32 位无符号整数。setFloat32:写入 4 个字节的 32 位浮点数。setFloat64:写入 8 个字节的 64 位浮点数。
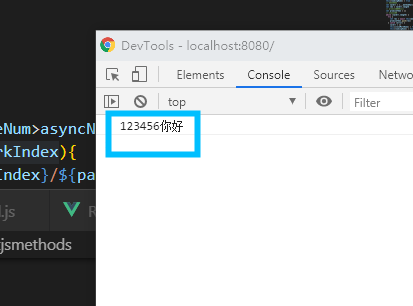
readAsText
这个是之前的时候搞得一个读取文件的方法,里边用到了FileReader的readAsText方法,不多说废话了,直接附上代码和效果图
export default function readFile(model) { return new Promise((resolve) => {
// 谷歌
if (window.FileReader) {
// 获取文件流
let file = model.currentTarget ? model.currentTarget.files[0] : model;
// 创建FileReader实例
let reader = new FileReader();
// 读文件
reader.readAsText(file);
reader.onload = () => {
resolve(reader.result)
}
}
//支持IE 7 8 9 10
else if (typeof window.ActiveXObject != \'undefined\') {
let xmlDoc;
xmlDoc = new ActiveXObject("Microsoft.XMLDOM");
xmlDoc.async = false;
resolve(xmlDoc.load(model))
}
//支持FF
else if (document.implementation && document.implementation.createDocument) {
let xmlDoc;
xmlDoc = document.implementation.createDocument("", "", null);
xmlDoc.async = false;
resolve(xmlDoc.load(model))
}
})
}
//安装依赖
npm i zjsmethods -S
~~~~
// 页面引入并使用
import { _readFile } from "zjsmethods"
_readFile(file).then(res=>{
console.log(res)
})
readAsArrayBuffer校验文件唯一
上边说了那么一大堆,终于要进入正题了哈,直接看第一版代码
const reader = new FileReader(); reader.readAsArrayBuffer(file.file);
reader.onload = () => {
let u8Arr = new Uint8Array(reader.result)
console.log(u8Arr)
console.log(md5(u8Arr))
}
ok 没得问题,结果如下

正在我觉得如此简单的时候,意外发生了,在我用比较小的文件的时候,只有1M 左右,但是当我上传了一个视频做测试的时候大概有两个G,浏览器崩溃了。。崩溃了。。了
然后我展开了 之前比较小文件的字节数组,大概有这么大

原因是readAsArrayBuffer在读取文件的时候会先把整个文件加载到内存中,那么如果文件太大,内存就不够用了,浏览器进程就会崩溃。
既然整个加载不行,那么我们选择把一个文件分段加载,后来我觉得10M一段比较稳妥,于是改成了当文件小于10M的时候平均分成10段,如果大于10M ,那么每10M 分成一段 直到分完为止,同样为了避免加密的时候数据太多造成卡顿,在生成标识的时候放弃用整个数组生成标识,采取固定规则的最大10M 数据生成标识
async vaildArrayBuffer(){ const reader = new FileReader();
while(this.whileNumber--){
this.start = this.end
this.end = this.end this.whileMax
let { start,end,sliceEnd,file}=this
reader.readAsArrayBuffer(file.slice(start,end));
reader.onload = () => {
new Uint8Array(reader.result)
.slice(0, sliceEnd)
.join(\'\')
}
}
}
这个时候又出了一个小插曲,在调用的时候reader被提示,正在进行文件读取,也是就一个reader在做读取文件操作的时候不能同事读取两个,于是乎刚开始的时候我高估了读取的速度放在了回调里边读取文件,代价就是我在电脑前面眼巴巴的看了控制台大概5分钟,后来改成了promise包裹,最后整理出的代码如下
/* * @Date: 2020-03-22 16:36:37
* @information: 最后更新时间
*/
import md5 from \'md5\'
export default class vaileFile{
constructor(file){
this.file = file
// 每次截取多少二进制
this.whileMax = Math.floor(file.size / 10 > 10240 * 1024 ? 10240 * 1024 : file.size / 10);
// 循环截取多少次
this.whileNumber = file.size <= 10240 * 1024 ? 10 : Math.ceil(file.size/this.whileMax)
// 二进制的截取长度,超出10M后 每10M 截取一部分,最多10M
this.sliceEnd = Math.floor(1024 * 10240 / file.size * 100 / this.whileNumber * this.whileMax)
this.sliceEnd = this.whileNumber>10?this.sliceEnd:10240 * 1024
// 转换二进制的长度
this.start = 0
this.end = 0;
}
/**
* @Author: 周靖松
* @Date: 2020-03-22 15:53:07
* @information: 校验文件唯一
*/
async vaildArrayBuffer(){
let promiseArr = []
while(this.whileNumber--){
this.start = this.end
this.end = this.end this.whileMax
let { start,end,sliceEnd,file}=this
let promiseArrayBuffer = new Promise((resolve,reject)=>{
const reader = new FileReader();
reader.readAsArrayBuffer(file.slice(start,end));
reader.onload = () => {
resolve(
new Uint8Array(reader.result)
.slice(0, sliceEnd)
.join(\'\')
)
}
})
promiseArr.push(promiseArrayBuffer)
}
return md5((await Promise.all(promiseArr)).join(\'\'))
}
}
大功告成,上传的文件后会生成一个md5 ,复制文件,文件改名字,都可以识别是之前的文件
然后写一个README.md 说明一下使用方法
### _vaileFile ,//使用文件二进制校验文件唯一性 当有业务需要上传oss 对象存储的时候,为了避免同一个文件(视频,音频,图片,压缩包等),有可能其他人复制或者改名字等等,造成文件重复上传,大量占用空间,写了一个校验文件的方法
//安装依赖
npm i zjsmethods -S
//引入这个类
import { _vaileFile } from \'zjsmethods\'
// 然后在你需要判断oss 是否有该文件的时候
new _vaileFile(\'file对象\').vaildArrayBuffer().then(res=>{
console.log(res)
// 继续上传 或者 向后端请求已经存在的文件url
})
// new 这个类之后 有一个vaildArrayBuffer 方法 他返回一个promise ,里边返回值是一个md5的字符串,这个是这个文件的唯一标识
最后发布npm包传git 结束学习 ★,°:.☆( ̄▽ ̄)/$:.°★ 。
喜欢的点个赞吧,有不足之处欢迎斧正
以上是 FileReader:前端读取本地文件 的全部内容, 来源链接: utcz.com/a/13961.html