【软件测试】SpringCloud 日志在压测中的二三事

一、如何拆分响应时间?
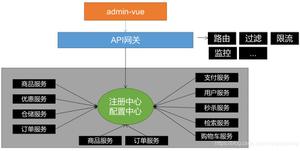
在性能分析中,响应时间的拆分通常是一个分析起点。因为在性能场景中,不管是什么原因,只要系统达到了瓶颈,再接着增加压力,肯定会导致响应时间的上升,直到超时为止。在判断了瓶颈之后,我们需要找到问题出现在什么地方。在压力工具上看到的响应时间,都是经过了后端的每一个系统的。那么,当响应时间变长,我们就要知道,它在哪个阶段时间变长了,我们看下这张图。
SpringCloud 一般是这样的架构,拆分时间应该是比较清楚:

首先我们需要查看 Nginx-Ingress 上的时间,日志里就可以通过配置 request-time、upstream_response_time 得到日志如下信息:

最后两列中,前面是请求时间的 8.659 s,后面是后端响应时间的 8.660 s。
同时我们可以去 gateway 查看 Reactor Netty 消耗的时间:

最后一列中,耗时 52 ms。
最后,我们再到各个 SpringBoot Service上去看时间:

请求时间消耗了 504 ms,响应时间消耗了 502 ms。
在这个例子中,主要说明了响应时间怎么一步步拆。当然,如果你是下面这种情况的话,再一个个拆就比较辛苦了,可以换另一种方式。

知道每个系统消耗了多长时间,那么我们可以借助链路监控工具来拆分时间了。比如像这样来拆分:

从 User 开始,每个服务之间的调用时间,都需要看看时间消耗的监控。这就是时间拆分的一种方式。其实不管我们用什么样的工具来监控,最终我们想得到的无非是每个环节消耗了多长时间。用日志也好,用链路监控工具也好,甚至抓包都可以。
二、如何启用 Access Logs?
1、Nginx Ingress Access Log
这里需要我们在 configmap 自定义 log-format 格式:

字段说明如下:
- $remote_addr - 发起请求的客户端 IP 地址。这里记录的 IP 地址并不一定是真实用户客户机的 IP 地址,它可能是私网客户端的公网映射地址或代理服务器地址。
- $remote_user - 远程客户端用户名称,用于记录浏览者进行身份验证时提供的名字,如登录百度的用户名 zuozewei,如果没有登录就是空白。
- [$time_local] - 收到请求的时间(访问的时间与时区,比如18/Jul/2018:17:00:01 +0800,时间信息最后的 "+0800" 表示服务器所处时区位于 UTC 之后的8小时)
- “$request” - 来自客户端的请求行(请求的 URI 和 HTTP 协议,这是整个 PV 日志记录中最有用的信息,记录服务器收到一个什么样的请求)
- $status - 服务器返回客户端的状态码,比如成功是 200。
- $body_bytes_sent - 发送给客户端的文件主体内容的大小,不包括响应头的大小(可以将日志每条记录中的这个值累加起来以粗略估计服务器吞吐量)
- “$http_referer” - 记录从哪个页面链接访问过来的(请求头 Referer 的内容 )
- “$http_user_agent” - 客户端浏览器信息(请求头User-Agent的内容 )
- "$ http_x_forwarded_for"- 客户端的真实ip,通常web服务器放在反向代理的后面,这样就不能获取到客户的IP地址了,通过 $remote_add拿到的IP地址是反向代理服务器的iP地址。反向代理服务器在转发请求的 http 头信息中,可以增加 x_forwarded_for** 信息,用以记录原有客户端的IP地址和原来客户端的请求的服务器地址。
- $request_time - 整个请求的总时间,以秒为单位(包括接收客户端请求数据的时间、后端程序响应的时间、发送响应数据给客户端的时间(不包含写日志的时间))
- $upstream_response_time - 请求过程中,upstream 的响应时间,以秒为单位(向后端建立连接开始到接受完数据然后关闭连接为止的时间)
得到的日志如下:

2、Reactor Netty Access Log
Spring-cloud-gateway 是基于 webflux 的应用,所以要启用 Reactor Netty 访问日志,需要设置 -Dreactor.netty.http.server.accessLogEnabled=true。
注意:它必须是 Java System 属性,而不是 SpringBoot 属性。
我们可以将日志记录系统配置为具有单独的访问日志文件。以下示例创建一个 Logback 配置:

得到的日志如下:

另外查看reactor-netty-0.8.5.RELEASE-sources.jar!/reactor/netty/http/server/AccessLog.java 源码我们可以理解其是怎么实现的:

accessLog 的 log 方法直接通过 logger 输出日志,其日志格式为 COMMON_LOG_FORMAT({} - {} [{}] "{} {} {}" {} {} {} {} ms),分别是address, user, zonedDateTime, method, uri, protocol, status, contentLength, port, duration.
3、SpringBoot Access Log
开启 Access Log 需要我们配置:

字段说明如下:
- %h - 发起请求的客户端 IP 地址。这里记录的 IP 地址并不一定是真实用户客户机的 IP 地址,它可能是私网客户端的公网映射地址或代理服务器地址。
- %l - 客户机的 RFC 1413 标识 ( 参考 ) ,只有实现了 RFC 1413 规范的客户端,才能提供此信息。
- %u - 远程客户端用户名称,用于记录浏览者进行身份验证时提供的名字,如登录百度的用户名 zuozewei,如果没有登录就是空白。
- %t - 收到请求的时间(访问的时间与时区,比如18/Jul/2018:17:00:01 +0800,时间信息最后的"+0800" 表示服务器所处时区位于 UTC 之后的8小时)
- %{X-Real_IP}i - 客户端的真实ip
- %r - 来自客户端的请求行(请求的 URI 和 HTTP 协议,这是整个 PV 日志记录中最有用的信息,记录服务器收到一个什么样的请求)
- %>s - 服务器返回客户端的状态码,比如成功是 200。
- %b - 发送给客户端的文件主体内容的大小,不包括响应头的大小(可以将日志每条记录中的这个值累加起来以粗略估计服务器吞吐量)
- %{Referer}i - 记录从哪个页面链接访问过来的(请求头Referer的内容 )
- %D - 处理请求的时间,以毫秒为单位
- %F - 客户端浏览器信息提交响应的时间,以毫秒为单位
得到的日志如下:

三、如何提高日志性能?
主要通过以下两个方面:
- 提高日志输出到文件 LEVEL 级别
压测的过程中可以把业务日志级别调整到
error
- 通过异步输出日志减少磁盘IO提高性能
1、怎么配置异步日志?
SpringBoot 应用自带 Logback 和 slf4j 的依赖,所以重点放在编写配置文件上,需要引入什么依赖,日志依赖冲突统统都不需要我们管了。logback 框架会默认加载 classpath 下命名为 logback-spring 或 logback 的配置文件。将所有日志都存储在一个文件中文件大小也随着应用的运行越来越大并且不好排查问题,正确的做法应该是将 error 日志和其他日志分开,并且不同级别的日志根据时间段进行记录存储。
举例说明:

部分标签说明:
- 标签,必填标签,用来指定最基础的日志输出级别
- 标签,通过使用该标签指定日志的收集策略
class 属性指定输出策略,通常有两种,控制台输出和文件输出,文件输出就是将日志进行一个持久化。ConsoleAppender 将日志输出到控制台
- 标签,通过使用该标签指定过滤策略
标签指定过滤的类型
- 标签,使用该标签下的标签指定日志输出格式
- 标签指定收集策略,比如基于时间进行收集
生成的日志如下所示:

之前的日志配置方式是基于同步的,每次日志输出到文件都会进行一次磁盘IO。采用异步写日志的方式而不让此次写日志发生磁盘IO,阻塞线程从而造成不必要的性能损耗。异步输出日志的方式很简单,添加一个基于异步写日志的 appender,并指向原先配置的 appender 即可。
如下:

相关资料:
- https://github.com/zuozewei/blog-example/tree/master/Performance-testing/03-performance-monitoring/springcloud-log
参考资料:
- [1]:nginx-configmap-resource
- [2]:Reactor Netty Access Logs
- [3]:聊聊reactor-netty的AccessLog
- [4]:性能测试实战30讲
以上是 【软件测试】SpringCloud 日志在压测中的二三事 的全部内容, 来源链接: utcz.com/a/131026.html