自然语言处理文本分类学习
一、前言
文本分类(Text Classification或Text Categorization,TC),或者称为自动文本分类(Automatic Text Categorization),是指计算机将载有信息的一篇文本映射到预先给定的某一类别或某几类别主题的过程。文本分类另外也属于自然语言处理领域。文本分类的应用场景有:
1. 新闻主题分类(文章分类):根据文章内容(或者结合标题)给新闻等其他文章一个类别,比如财经、体育、军事、明星等等。一般在新闻资讯方面使用比较多。
2. 情感分析:两类(正面、负面)或者多类(例如,生气、高兴、悲伤等等),其实还是有三类(正、负、中性),不过和两类的处理方法会有些许区别。一般在影评(比如豆瓣、淘票票)、商品评价(比如淘宝、京东的商品评价)等对商品和服务的评价方面应用比较多。
3. 舆情分析:和情感分类类似,更多的是两分类,政府或者金融机构用的比较多。
4. 邮件过滤:比如鉴定一封邮件是否是骚扰或者广告营销等垃圾邮件。
5. 作为其他自然语言处理系统的一部分,比如问答系统中对问句进行主题分类。
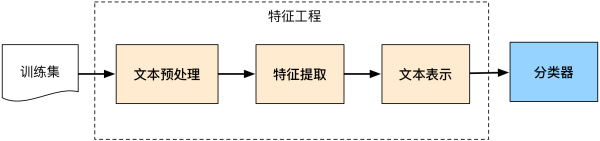
文本分类系统如下图所示:
二、数据采集
数据采集是文本挖掘的基础,主要包括爬虫技术和页面处理。
2.1 爬虫技术
Web信息检索的第一步就是要抓取网络文档,爬虫就承担了解决这一问题的主要责任。爬虫有很多种类型,但最典型的就是网络爬虫。网络爬虫通过跟踪网页上的超链接来搜寻并下载新的页面。似乎听起来该过程比较简单,但是如何能够高效处理Web上出现的大量新页面,如何处理已抓取页面的更新页面,如何保持页面的最新性,这些问题都成为网络爬虫设计富有挑战的难题。网络爬虫抓取任务可以限定在一个比较小的范围内,例如一个公司,一个网站,或者一所大学的站点。主题网络爬虫与话题网络爬虫要采用分类技术来限制所搜寻页面属于同一主题类别。
2.2 页面处理
通过网络爬虫抓取的页面是最原始的Web页面,它们的格式多种多样,如HTML、XML、Adobe PDF、Microsoft Word等等。这些web页面含有大量的噪声数据,包括导航栏、广告信息、Web标签、超链接或者其他非内容格式数据等,这些数据几乎都成是阻碍文本下一步处理的因素。因此需要经过预处理去除上述噪音数据,将Web页面转化成为纯净统一的文本格式和元数据格式。Web关注内容过滤也是Web信息处理领域的一项热门研究课题。
另外一个普遍存在的页面处理问题是编码不一致。由于计算机发展、民族语言、国家地域的不同造成现在计算机存储数据采用许多种编码格式,例如ASCII、UTF-8、GBK、BIG5等等。在实际应用过程中,在对不同编码格式的文档进行深入处理之前,必须要保证对它们编码格式进行统一转换。
三、文本预处理
文本要转化成计算机可以处理的数据结构,就需要将文本切分成构成文本的语义单元。这些语义单元可以使句子、短语、词语或单个的字。本文无论对于中文还是英文文本,统一将最小语义单元称为“词组”。对于不同的语言来说处理有所区别,下面简述最常见的中文和英文文本的处理方式。
3.1 英文处理
英文文本的处理相对简单,每一个单词之间有空格或标点符号隔开。如果不考虑短语,仅以单词作为唯一的语义单元的话,处理英文单词切分相对简单,只需要分割单词,去除标点符号。英文还需要考虑的一个问题是大小写转换,一般认为大小写不具有不同的意义,这就要求将所有单词的字幕都转换成小写或大写。另外,英文文本预处理更为重要的问题是词根的还原,或称词干提取。词根还原的任务就是将属于同一个词干(Stem)的派生词进行归类转化为统一形式。例如,把“computed”, “computer”, “computing”可以转化为“compute”。通过使用一个给定的词来代替一类中每一个元素,可以进一步增加类别与文档中的词之间匹配度。词根还原可以针对所有词进行,也可以针对少部分词进行或者不采用词根还原。针对所有词的词根还原可能导致分类结果的下降,这主要的原因或许是删除了不同形式单词所含有的形式意义。哪些词在哪些应用中应该词根还原尚不清楚。McCallum等人研究工作显示,词根还原可能有损于分类性能。
3.2 中文分词技术
为什么分词处理?因为研究表明特征粒度为词粒度远远好于字粒度,其大部分分类算法不考虑词序信息,基于字粒度的损失了过多的n-gram信息。
中文分词主要分为两类方法:基于词典的中文分词和基于统计的中文分词。
- 基于词典的中文分词
核心是首先建立统一的词典表,当需要对一个句子进行分词时,首先将句子拆分成多个部分,将每一个部分与字典一一对应,如果该词语在词典中,分词成功,否则继续拆分匹配直到成功。
所以:字典,切分规则和匹配顺序是核心。
- 基于统计的中文分词方法
统计学认为分词是一个概率最大化问题,即拆分句子,基于语料库,统计相邻的字组成的词语出现的概率,相邻的词出现的次数多,就出现的概率大,按照概率值进行分词,所以一个完整的语料库很重要。
- 基于理解的分词方法
基于理解的分词方法是通过让计算机模拟人对句子的理解,达到识别词的效果。其基本思想就是在分词的同时进行句法、语义分析,利用句法信息和语义信息来处理歧义现象。它通常包括三个部分:分词子系统、句法语义子系统、总控部分。在总控部分的协调下,分词子系统可以获得有关词、句子等的句法和语义信息来对分词歧义进行判断,即它模拟了人对句子的理解过程。这种分词方法需要使用大量的语言知识和信息。由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。
3.3 去停用词
停用词(Stop Word)是一类普遍纯在与文本中的常用词,并且脱离语境它们本身并不具有明显的意义。最常用的词是一些典型的功能词,这些词构成句子的结构,但对于描述文本所表述的意义几乎没有作用,并且容易造成统计偏差,影响机器学习效果。在英文中这词如:“the”、“of”、“for”、“with”、“to”等,在中文中如:“啊”、“了”、“并且”、“因此”等。由于这些词的用处太普遍,去除这些词,对于文本分类来说没有什么不利影响,相反可能改善机器学习效果。停用词去除组件的任务比较简单,只需从停用词表中剔除定义为停用词的常用词就可以了。尽管停用词去除简单,含有潜在优势,但是停用词去除与词根还原具有同样的问题,定义停用词表中应该包含哪些词确是比较困难,一般科研中停用词表的规模为几百。
四、文本特征提取
4.1 词袋模型
思想:
建立一个词典库,该词典库包含训练语料库的所有词语,每个词语对应一个唯一识别的编号,利用one-hot文本表示。
文档的词向量维度与单词向量的维度相同,每个位置的值是对应位置词语在文档中出现的次数,即词袋模型(BOW)
问题:
(1)容易引起维度灾难问题,语料库太大,字典的大小为每个词的维度,高维度导致计算困难,每个文档包含的词语数少于词典的总词语数,导致文档稀疏。(2)仅仅考虑词语出现的次数,没有考虑句子词语之间的顺序信息,即语义信息未考虑
4.2 TF-IDF文本特征提取
利用TF和IDF两个参数来表示词语在文本中的重要程度。
TF是词频:指的是一个词语在一个文档中出现的频率,一般情况下,每一个文档中出现的词语的次数越多词语的重要性更大,例如BOW模型一样用出现次数来表示特征值,即出现文档中的词语次数越多,其权重就越大,问题就是在长文档中 的词语次数普遍比短文档中的次数多,导致特征值偏向差异情况。
TF体现的是词语在文档内部的重要性。
IDF是体现词语在文档间的重要性:即如果某个词语出现在极少数的文档中,说明该词语对于文档的区别性强,对应的特征值高,IDF值高,IDFi=log(|D|/Ni),D指的是文档总数,Ni指的是出现词语i的文档个数,很明显Ni越小,IDF的值越大。
最终TF-IDF的特征值的表达式为:$TF-IDF(i,j)=TF_{ij}*IDF_{i}$
4.3 基于词向量的特征提取模型
想基于大量的文本语料库,通过类似神经网络模型训练,将每个词语映射成一个定维度的向量,维度在几十到化百维之间,每个向量就代表着这个词语,词语的语义和语法相似性和通过向量之间的相似度来判断。
常用的word2vec主要是CBOW和skip-gram两种模型,由于这两个模型实际上就是一个三层的深度神经网络,其实NNLM的升级,去掉了隐藏层,由输入层、投影层、输出层三层构成,简化了模型和提升了模型的训练速度,其在时间效率上、语法语义表达上效果明显都变好。word2vec通过训练大量的语料最终用定维度的向量来表示每个词语,词语之间语义和语法相似度都可以通过向量的相似度来表示。
五、分类模型
5.1 传统机器学习方法
大部分机器学习方法都在文本分类领域有所应用,比如朴素贝叶斯分类算法(Naïve Bayes)、KNN、SVM、最大熵和神经网络等等。
5.2 深度学习文本分类模型
5.2.1 FastText
5.2.1.1 FastText使用场景
FastText是Facebook AI Research在16年开源的一种文本分类器。 其特点就是fast。相对于其它文本分类模型,如SVM,Logistic Regression等模型,fastText能够在保持分类效果的同时,大大缩短了训练时间。
5.2.1.2 FastText的几个特点
- 适合大型数据+高效的训练速度:能够训练模型“在使用标准多核CPU的情况下10分钟内处理超过10亿个词汇。
- 支持多语言表达:利用其语言形态结构,FastText能够被设计用来支持包括英语、德语、西班牙语、法语以及捷克语等多种语言。FastText 的性能要比 Word2Vec 工具明显好上不少。
- FastText专注于文本分类。它适合类别特别多的分类问题,如果类别比较少,容易过拟合
5.2.1.3 FastText原理
FastText方法包含三部分,模型架构,层次SoftMax和N-gram特征。
5.2.1.4 模型架构
FastText模型架构和 Word2Vec 中的 CBOW 模型很类似,因为它们的作者都是Facebook的科学家Tomas Mikolov。不同之处在于,FastText预测标签,而CBOW 模型预测中间词。
- CBOW的架构:输入的是w(t)的上下文2d个词,经过隐藏层后,输出的是w(t)。CBOW模型架构
- FastText的架构:将整个文本作为特征去预测文本的类别。FastText模型架构
5.2.1.5 层次SoftMax
- 对于有大量类别的数据集,FastText使用了一种分层分类器(而非扁平式架构)。不同的类别被整合进树形结构中(想象下二叉树而非 list)。在某些文本分类任务中类别很多,计算线性分类器的复杂度高。为了改善运行时间,FastText模型使用了层次 Softmax技巧。层次Softmax技巧建立在哈弗曼编码的基础上,对标签进行编码,能够极大地缩小模型预测目标的数量。
- fastText 也利用了类别不均衡这个事实(一些类别出现次数比其他的更多),通过使用 Huffman 算法建立用于表征类别的树形结构(Huffman树)。因此,频繁出现类别的树形结构的深度要比不频繁出现类别的树形结构的深度要小,这也使得进一步的计算效率更高。Huffman树结构图
5.2.1.6 N-gram特征
- FastText 可以用于文本分类和句子分类。不管是文本分类还是句子分类,我们常用的特征是词袋模型。但词袋模型不能考虑词之间的顺序,因此 FastText还加入了 N-gram 特征。“我 爱 她” 这句话中的词袋模型特征是 “我”,“爱”, “她”。这些特征和句子 “她 爱 我” 的特征是一样的。如果加入 2-gram,第一句话的特征还有 “我-爱” 和 “爱-她”,这两句话 “我 爱 她” 和 “她 爱 我” 就能区别开来了。当然啦,为了提高效率,我们需要过滤掉低频的 N-gram。
- 在 FastText中,每个词被看做是 n-gram字母串包。为了区分前后缀情况,"<", ">"符号被加到了词的前后端。除了词的子串外,词本身也被包含进了 n-gram字母串包。以 where 为例,n=3 的情况下,其子串分别为<wh, whe, her, ere, re>,以及其本身 。
5.2.1.7 FastText 和 word2vec 对比
- 相似点:
1、模型结构很像,都是采用embedding向量的形式,得到word的隐向量表达。
2、采用很多相似的优化方法,比如使用Hierarchical softmax优化训练和预测中的打分速度。
- 不同点:
1、模型的输出层:word2vec的输出层,对应的是每一个term,计算某term的概率最大;而fasttext的输出层对应的是分类的label。不过不管输出层对应的是什么内容,起对应的vector都不会被保留和使用。
2、模型的输入层:word2vec的输出层,是 context window 内的term;而fasttext 对应的整个sentence的内容,包括term,也包括 n-gram的内容。
- 两者本质的不同,体现在 h-softmax的使用:
1、Word2vec的目的是得到词向量,该词向量最终是在输入层得到,输出层对应的h-softmax也会生成一系列的向量,但最终都被抛弃,不会使用。
2、fastText则充分利用了h-softmax的分类功能,遍历分类树的所有叶节点,找到概率最大的label(一个或者N个)。
5.2.2 Text-CNN文本分类
TextCNN 是利用卷积神经网络对文本进行分类的算法,它是由 Yoon Kim 在2014年在 “Convolutional Neural Networks for Sentence Classification” 一文中提出的。详细的原理图如下。

TextCNN详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。
5.2.3 TextRNN
模型: Bi-directional RNN(实际使用的是双向LSTM)从某种意义上可以理解为可以捕获变长且双向的的 “n-gram” 信息。
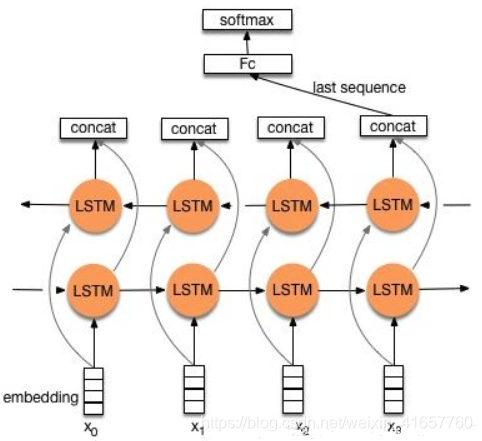
改进: CNN有个最大问题是固定 filter_size 的视野,一方面无法建模更长的序列信息,另一方面 filter_size 的超参调节也很繁琐。
5.2.4 TextRNN + Attention
模型结构:
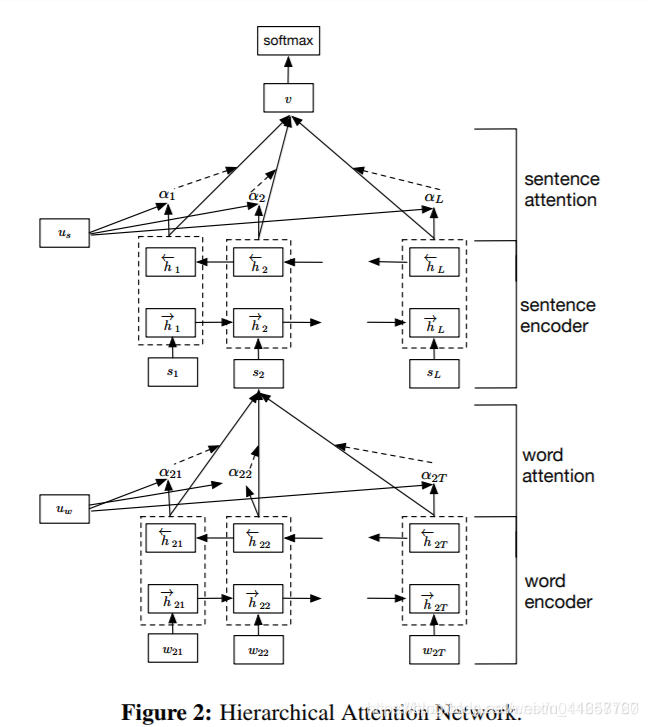
改进:注意力(Attention)机制是自然语言处理领域一个常用的建模长时间记忆机制,能够很直观的给出每个词对结果的贡献,基本成了Seq2Seq模型的标配了。实际上文本分类从某种意义上也可以理解为一种特殊的Seq2Seq,所以考虑把Attention机制引入近来。
5.2.5 TextRCNN(TextRNN + CNN)
模型结构:
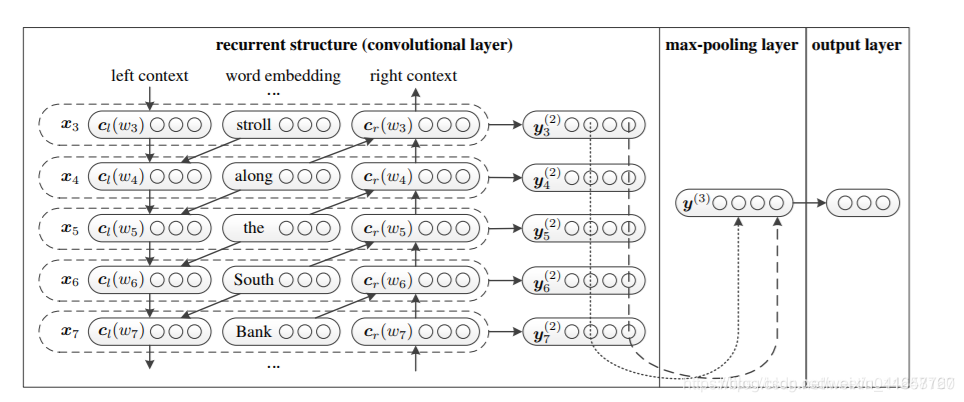
过程:
利用前向和后向RNN得到每个词的前向和后向上下文的表示:

词的表示变成词向量和前向后向上下文向量连接起来的形式:
![]()
再接跟TextCNN相同卷积层,pooling层即可,唯一不同的是卷积层 filter_size = 1就可以了,不再需要更大 filter_size 获得更大视野。
参考:
https://blog.csdn.net/xsdjj/article/details/83755511
https://www.jianshu.com/p/56061b8f463a
https://blog.csdn.net/weixin_41657760/article/details/93163519
以上是 自然语言处理文本分类学习 的全部内容, 来源链接: utcz.com/a/121810.html