python增强型赋值与普通赋值的区别
前言
增强型赋值语句是经常被使用到的,因为从各种学习渠道中,我们能够得知i += 1的效率往往要比 i = i + 1 更高一些(这里以 += 为例,实际上增强型赋值语句不仅限于此)。所以我们会乐此不疲的在任何能够替换普通赋值语句的地方使用增量型赋值语句,以此来优化代码。那么我们是否有想过,在什么情况下 i += 1 其实并不等效于 i = i + 1 !!
增强型赋值语句:
>>> a = [1, 2, 3]>>> b = a
>>> b += [4, 5, 6]
>>> a
[1, 2, 3, 4, 5, 6]
>>> b
[1, 2, 3, 4, 5, 6]
>>> id(a)
140268862690880
>>> id(b)
140268862690880
>>>
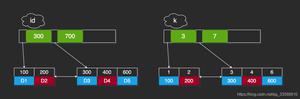
代码解析:先定义了个列表a,然后创建对象b,b的地址指向a,所以a和b共用一片内存地址,b += [4, 5, 6]因为list是可变对象,所以b仍然在原来的内存地址上,只是改变了b的value,又因为a和b是指向同一地址的,所以a和b的值相等
普通赋值语句:
>>> a = [1, 2, 3]>>> b = a
>>> b = b + [4, 5, 6]
>>> a
[1, 2, 3]
>>> b
[1, 2, 3, 4, 5, 6]
>>> id(a)
140268888586672
>>> id(b)
140268866910800
>>>
代码解析:先定义了个列表a,然后创建对象b,b的地址指向a,目前a和b共用一片内存地址,关键点:b = b + [4, 5, 6],是在原来b的基础上,添加了一个列表,并且将新的值赋值给了左边的b,原先b的内存地址是指向a的,但是现在又重新赋值了,所以b重新开辟了一片新的内存地址,此时a和b的id和value均不同
增强型赋值与使用普通赋值的区别")
这是一个值得注意的坑,警惕我们在使用增量赋值运算符来操作可变对象(如:列表)时可能会产生不可预测的结果。
增值运算符和普通运算符对于不可变对象作用一致
上面我们说的都是针对可变对象,但是针对不可变对象比如元组,他们都会产生新的内存地址
>>> a = (1, 2, 3)>>> id(a)
140393063791584
>>> a += (4, )
>>> a
(1, 2, 3, 4)
>>> id(a)
140393063931056
>>> b = (1, 2, 3)>>> id(b)
140393064025216
>>> b = b + (4, )
>>> b
(1, 2, 3, 4)
>>> id(b)
140393063930864
>>>
总结
要解释这个问题,首先需要了解「Python 共享引用」的概念:在 Python 中,允许若干个不同的变量引用指向同一个内存对象。同时在前文中也提到,增强赋值语句比普通赋值语句的效率更高,这是因为在 Python 源码中, 增强赋值比普通赋值多实现了“写回”的功能,也就是说增强赋值在条件符合的情况下(例如:操作数是一个可变类型对象)会以追加的方式来进行处理,而普通赋值则会以新建的方式进行处理。这一特点导致了增强赋值语句中的变量对象始终只有一个,Python 解析器解析该语句时不会额外创建出新的内存对象。所以例一中变量 a、b 的引用在最后依旧指向了同一个内存对象;相反,对于普通赋值运算语句,Python 解析器无法分辨语句中的两个同名变量(例如:b = b + 1)是否应该为同一内存对象,所以干脆再创建出一个新的内存对象用来存放最后的运算结果,所以例二中的 a、b 从原来指向同一内存对象,到最后分别指向了两个不同的内存对象。
提示:尽量不要使用增量赋值运算符来处理任何可变类型对象,除非你对上述问题有了足够的了解。
以上是 python增强型赋值与普通赋值的区别 的全部内容, 来源链接: utcz.com/a/121648.html