Centos mini Hadoop集群搭建
1.事前了解
1.1 Hadoop
百度百科:https://baike.baidu.com/item/Hadoop/3526507?fr=aladdin
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),其中一个组件是HDFS。
- Hadoop的框架最核心的设计: HDFS和MapReduce。HDFS为海量的数据提供了存储,而MapReduce则为海量的数据提供了计算
- Hadoop核心架构:
- 元素:
- Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。
- HDFS:
- 对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的,这些节点包括:
- NameNode(仅一个):它在 HDFS 内部提供元数据服务,可以控制所有文件操作,也作为主服务器;
- DataNode(若干个):它为 HDFS 提供存储块。
- 对外部客户机而言,HDFS就像一个传统的分级文件系统。可以创建、删除、移动或重命名文件,等等。HDFS 的架构是基于一组特定的节点构建的,这是由它自身的特点决定的,这些节点包括:
- MapReduce:
- MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。概念"Map(映射)"和"Reduce(归约)"。
- 基本所需节点:
- master:至少需要一个,为了防止此节点发生故障也可以弄个备份节点。此节点作为主机(主节点),主要配置NameNode和JobTracker,是整个集群的唯一的全局管理者,功能包括:作业管理、状态监控和任务调度等。
- Salve:至少需要三个,此节点作为从机,主要配置DataNode 和TaskTracker,负责分布式数据存储以及任务的执行和任务状态的回报。
- 元素:
- 功能实现: 在Hadoop部署中,有三种服务器角色,他们分别是客户端、Masters节点以及Slave 节点。Master 节点,Masters 节点又称主节点,主节点负责监控两个核心功能:大数据存储(HDFS)以及数据并行计算(Map Reduce)。其中,Name Node 负责监控以及协调数据存储(HDFS)的工作,JobTracker 则负责监督以及协调 Map Reduce 的并行计算。 而Slave 节点则负责具体的工作以及数据存储。每个 Slave 运行一个 Data Node 和一个 Task Tracker 守护进程。这两个守护进程负责与 Master 节点通信。Task Tracker 守护进程与 Job Tracker 相互作用,而 Data Node 守护进程则与 Name Node 相互作用。
1.2.关于CentOS
Minimal ISO
Mini版本,只有必要的软件,自带的软件最少(没有图形化界面)
DVD ISO
标准版本安装(服务器安装推荐使用,包含一些基本的软件和图形化界面)
Everything ISO
对完整版安装盘的软件进行补充,集成所有软件(图形化界面版)
很大,没下过,好像有十几个G,似乎在官方的安装指南看到的。
2.准备
- 以下搭建所用到的软件和插件的版本不一定和我一样:
| 软件/插件 | 下载地址 | 作用 |
|---|---|---|
| VMware Workstation Pro16 | http://www.opdown.com/soft/262811.html | 创建虚拟机的工具 |
| CentOS-7-x86_64-Minimal-2009 | 1.https://www.centos.org/download/ 2.https://developer.aliyun.com/mirror/ | ISO镜像,创建虚拟机是要用到 |
| xshell7 | 1.http://www.j9p.com/down/531725.html 2.https://www.xshellcn.com/xiazai.html | 使虚拟机操作更简单化 |
| jdk-8u171-linux-x64.tar | 1.https://repo.huaweicloud.com/java/jdk/ 2.https://mirrors.tuna.tsinghua.edu.cn/AdoptOpenJDK/ | jdk,虚拟机连接Xshell后要用到 |
| hadoop-2.7.7.tar | 1.https://archive.apache.org/dist/hadoop/common/ 2.http://mirror.bit.edu.cn/apache/hadoop/common/ | Hadoop,后面要用到 |

- 准备1台master主机与3台Slave从机(由于某种原因本人就先安装一台master与一台Salve,但是如果想再安装Salve其步骤一样)。
- 虚拟机的安装我就不演示了,具体安装步骤可以看这篇博客:https://www.cnblogs.com/yfb918/p/10497328.html ,或者可以百度。
- Xshell安装可以看这位博主:https://blog.csdn.net/weixin_40928253/article/details/80621724 ,也可以百度。
我的机器环境: (注意: 由于一些原因下面类容中由于自己的一些问题导致IP发生了变化,刚开始为 192.168.30.~,后面才变成了 192.168.6.~,)
| 机器名 | IP |
|---|---|
| master.hadoop | 192.168.6.10 |
| slave1.hadoop | 192.168.6.11 |
3.相关命令
ping www.baidu.com //用于查看网络是否连接service network restaet //重启网络
su //切换root用户
vi /etc/sysconfig/network-scripts/ifcfg-ens33 //配置静态网络
systemctl stop firewalld.service //停止防火墙
systemctl disable firewalld.service //禁止防火墙开机启动
systemctl status firewalld.service //查看防火墙,下面显示(dead)为普通颜色则关闭,绿色则启动状态。
firewall-cmd --state //查看防火墙状态(关闭显示:not running,开启后显示:running)
service iptables status //查看当前系统是否安装防火墙
yum install -y iptables //安装防火墙
yum install iptables-services //安装防火墙服务
iptables -L -n //查看防火墙现有规则
systemctl enable iptables //设置防火墙开机自启
service iptables save //保存设置
service iptables start //启动防火墙,之后须重启虚拟机生效
service iptables restart //重启防火墙,之后须重启虚拟机生效
reboot //重启虚拟机
ip addr //查看当前机器IP
ifconfig //查看当前机器IP
hostnamectl set-hostname 本机名称 //修改本机名称
hostname //查看本机名称
ls //查看目录
cd //返回主master目录
cd .. //返回上级目录
yum install lrzsz -y //安装rz工具
yum install rsync //安装拷贝文件工具
scp /etc/opt/package/*.gz [email protected]:/etc/opt/package //文件拷贝复制
ssh-keygen –t rsa –P '' //生成⽆密码密钥对
ssh-keygen -b 1024 -t rsa //生成⽆密码密钥对
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys //追加公钥
ssh-copy-id //追加公钥
passwd root //改密码
rm -fr package //删除目录
tail- //查看日志
4.开始搭建
- 期间可能遇到的一些问题解决办法可以参考这篇博客:https://blog.csdn.net/weixin_46311020/article/details/113180767?spm=1001.2014.3001.5502 ,这里面类容中可能有你遇到的问题及解决办法。
- 以下是所用软件及虚拟机安装完成后Hadoop集群具体搭建步骤。
注意: 在进行相关配置时 按 A 键进入编辑模式才能向文件里面添加内容,配置完成后先按 Esc 键退出编辑模式后再次输入 :wq(保存并退出) 后回车退出,这个内容我下面不会再提及。
4.1网络配置(下面内容两台机子步骤一样)
(1)静态网络配置
配置需要root用户,如果不是就输入 su 会要你输入密码后进入root用户:
[[email protected] ~]#su //切换root用户 接下来按以下命令进行网络配置:
[[email protected] ~]# vi /etc/sysconfig/network-scripts/ifcfg-ens33 打开虚拟机上的虚拟网络编辑器,先点击更改设置,然后点击VMnet8,向文件配置里面按VMnet8里面的内容填写ip地址(注意:ip地址只设置最后位数,自己随便设置数,比如我设置的为10),子网掩码(不变)默认网关(不变),dns(注意:可设置一个,也可设置两个,你可以设置为自己本机电脑的dns,也可设置网上的dns),

配置内容如下:
IPADDR="" //IP地址NETMASK="" //子网掩码
GATEWAY="" //默认网关
DNS1="" //DNS
DNS2="" //DNS
结果:(注意: 配置完成后先别急着保存,要先虚拟网络编辑器中窗口都 确定 后再文件保存退出,下面图片中的网关中的31 应该是30)

之后重启网络,ping 百度,看能通吗,通了则成功,最好再ping下自己设置的IP
service network restaet //重启启网络ping www.baidu.com /看能否ping通

(2)关闭防火墙
systemctl stop firewalld.service //停止防火墙systemctl disable firewalld.service //禁止防火墙开机启动
firewall-cmd --state //查看防火墙状态(关闭显示:not running,开启后显示:running)

(3)修改当前机器名
在以下命令后面添加想要改的名称,我改的名为 :master.Hadoop
hostnamectl set-hostname master.hadoop //修改主机名reboot //重启虚拟机查看成功没
hostname //查看本机名称

(4)编辑hosts文件
hostname -i //查看你本机的IP,并记住vi /etc/hosts //进入hosts文件
需要添加的内容:(本机IP 本机名称),(从机IP 从机名称 )
192.168.6.10 master.hadoop192.168.6.11 slave1.hadoop

检验: 互相ping一下看是否成功
master机:ping slave1.hadoopslave1机:ping master.hadoop

4.2.必要安装(slave步骤一样)
- 以下的安装后面需要用到
SSH服务:用于免密登录及后面Xshell连接虚拟机可能需要用到,及其它用处
[[email protected] ~]# rpm -qa | grep ssh //查看有没有安装SSH服务,如果没有就执行下面命令[[email protected] ~]# yum install openssh-server -y //安装SSH服务
[[email protected] ~]# yum install openssh-clients -y //安装SSH客户
[[email protected] ~]# rpm –qa | grep openssh 查看是否安装成功
Service服务:用于启动SSH服务,及其它用处
[[email protected] ~]# service sshd restart //安装srevice[[email protected] ~]# service sshd restart //启动SSH
[[email protected] ~]# yum install net-tools //网络配置工具
vim编辑器:使编辑文件更方便
[[email protected] ~]# yum install vim -y 安装远程数据同步工具:可用于拷贝等
[[email protected] ~]# yum install rsync //安装[[email protected]master ~]# rpm –qa | grep rsync //查看
安装rz工具:用于后面的文件传输
[[email protected] ~]# yum install lrzsz -y 安装passwd工具,用于更该密码
yum install passwd4.3Xshell操作虚拟机
- Xshell连接虚拟机
步骤我这就不概述了,自己可以百度,也可以参考这篇博文:https://blog.csdn.net/weixin_40928253/article/details/80621724
- 连接时遇到问题可参考这篇博文,里面可能有和你一样的问题的解决方法可以参考:https://blog.csdn.net/weixin_46311020/article/details/113180767
- 特别注意:接下来的操作中使用的命令,记得注意看命令前的这部分 [[email protected] ~]# 通过它可以看见我在哪个目录下使用的该命令。
(1)文件传输(slave步骤一样)
这里需要将刚我们开始下载的jdk与Hadoop包 传入虚拟机,为了文件不混乱及今后方便查找,我们需要自己在系统中新建存放相应文件的目录,可以自己选则,一般选在opt 或home目录下,我选择opt目录下创建:
注意:我这次在opt目录下创建了个 package 目录用于存放 jdk 与 hadoop,由于后面以后需要解压安装两个包,所以我顺便在 opt 目录下再建了个 module 目录备用,用于作为以后两个包解压的目录。
传输文件需要输入 rz 命令: 输入命令后如果显示未找到命令,则是因为没有安装该工具,则需要安装;如果弹出本机文件夹,则说明有该工具,不需要安装
[[email protected] ~]# rpm -qa |grep lrzsz //检查是否安装rz
[[email protected] ~]# sudo mkdir /opt/package //opt目录下创建存放jdk与hadoop包的目录
[[email protected] ~]# sudo mkdir /opt/module //opt目录下创建解压jdk与hadoop包的目录
/*
查看创建的目录
[[email protected] ~]# cd /opt
[[email protected] opt]# ls
*/
/*
传输文件
[[email protected] ~]# cd /opt/package //进入package目录
[[email protected] package]# rz //开始传输本地文件,选中自己要传输的文件
[[email protected] package]# ls //完成后进入package目录查看,有以下两个文件
-- hadoop-2.7.7.tar.gz jdk-8u171-linux-x64.tar.gz --
*/

(2)SSH免密登录
- 这个主机从机一起做
用于节点之间的访问不需要每次输入密码,而且集群操作的时候需要访问许多节点,可每个节点访问需要输入密码,但当集群运行的时候不会每次都弹出输入密码,容易造成卡顿,导致集群运行不通畅,所以就设置所有节点之间的免密码访问权限。
- 设置master免密自己,步骤:
/*生成⽆密码密钥对:
[[email protected] ~]# ssh-keygen -b 1024 -t rsa //生成⽆密码密钥对,一路回车,直至出现图形
[[email protected] ~]# ls
-- anaconda-ks.cfg --
[[email protected] ~]# ls -all
[[email protected] ~]# cd .ssh
[[email protected] .ssh]# ls //查看有没有生成公钥(id_rsa.pub),私钥(id_rsa)
-- id_rsa id_rsa.pub known_hosts --
*/
/*
设置master.hadoop免密:
[[email protected] .ssh]# ssh-copy-id master.hadoop //设置master.hadoop免密,期间可能会要你输入一个 yes 和 master密码
[[email protected] .ssh]# ls //查看,会发现多了个authorized_keys 文件
-- authorized_keys id_rsa id_rsa.pub known_hosts --
*/
/*
修改master.hadoop的 authorized_keys权限:
[[email protected] .ssh]# chmod 600 ~/.ssh/authorized_keys
[[email protected] .ssh]# ll //查看
-- 总用量 16 --
--- rw-------. 1 root root 232 1月 29 13:08 authorized_keys --
*/
/*jie
设置SSH配置:
[[email protected] .ssh]# cd //回到master节点
[[email protected] ~]# vim /etc/ssh/sshd_config //进入文件修改配置
(修改类容:
PermitRootLogin prohibit-password禁用
port 22 启动
PermitRootLogin yes #启用
RSAAuthentication yes # 启⽤ RSA 认证
PubkeyAuthentication yes # 启⽤公钥私钥配对认证⽅式
AuthorizedKeysFile .ssh/authorized_keys # 公钥⽂件路径(和上⾯⽣成的⽂件同)
)
[[email protected] ~]# service sshd restart //重启SSH服务,使配置生效
*/
[[email protected] ~]# ssh master.hadoop //验证登录,如果登录不提示输入密码,则表示成功
- 设置master免密登录slave1,步骤:
这个大概步骤:还是先进入master的钥匙对里面,利用上面步骤中master为自己生成免密的方法,为slave1生成免密,然后进入slave的节点中对authorized_keys权限的设置与SSH配置和上面相同,具体步骤如下:
[[email protected] ~]# ssh-keygen -b 1024 -t rsa //生成⽆密码密钥对,一路回车,直至出现图形[[email protected] ~]# cd ~/.ssh //进入 .ssh文件
/*
设置master对slave1免密:
[[email protected] .ssh]# ssh-copy-id slave1.hadoop //期间可能会要你输入一个 yes 和slave的密码
*/
进入slave1.Hadoop节点中:
```shell
[[email protected] ~]# ssh-keygen -b 1024 -t rsa //生成⽆密码密钥对,一路回车,直至出现图形
[[email protected] ~]# cd ~/.ssh //进入 .ssh文件
[[email protected] .ssh]# ls //查看,会发现已有authorized_keys文件,因为这是我们在master上为它生成的
-- authorized_keys id_rsa id_rsa.pub --
/*
修改slave1.hadoop的 authorized_keys权限:与上面master中步骤一样
*/
/*
设置SSH配置:与上面master中步骤一样
*/
*/
通过master登录slave1,登录成功可以看见: [[email protected] ~]# 个标志
[[email protected] ~]# ssh slave1.hadoop //验证登录,如果登录不提示输入密码,则表示成功
*/
- 设置slave1免密登录master,步骤:
[[email protected] ~]# ssh-keygen -b 1024 -t rsa[[email protected] ~]# cd ~/.ssh
[[email protected] .ssh]# ssh-copy-id master.hadoop //免密
(3)解压安装jdk(slave一样)
注意:下面我们将把 /opt/package/ 中的jdk 解压到 /opt/module/ 中,其中module 目录是我再前面已经建的,具体可查看前面内容:文件传输。
- 解压:
/*查看将要解药的文件
[[email protected] ~]# cd /opt/package //进入package目录
[[email protected] package]# ls //查看
-- hadoop-2.7.7.tar.gz jdk-8u171-linux-x64.tar.gz --
*/
/*
解压:
[[email protected] package]# tar -zxvf jdk-8u171-linux-x64.tar.gz -C /opt/module/ //解压到 /opt/module/ 目录中
*/
[[email protected] package]# ls /opt/module //解压完成后查看module有没有
-- jdk1.8.0_171 --
- 改名:由于后面操作会大量用到这个文件。而由于这个文件名太长,所以我们把 文件名 jdk1.8.0_171 改为 jdk1.8
[[email protected] package]# cd //回到主目录[[email protected] ~]# cd /opt/module //进入module目录
[[email protected] module]# mv jdk1.8.0_171/ jdk1.8 //改名
[[email protected] module]# ls //查看
-- jdk1.8 --
- 配置JDK环境变量:
/*获取jdk路径:
[[email protected] module]# cd jdk1.8 //进入jdk1.8目录
[[email protected] jdk1.8]# pwd //查看目录结构,并记住
-- /opt/module/jdk1.8 --
*/
/*
进入profile文件,添加jdk环境变量:
[[email protected] jdk1.8]# cd //回到主目录
[[email protected] ~]# sudo vim /etc/profile //进入文件
*/
在 profile 文件末尾添加 JDK 路径,我的添加内容如下:
#JAVA_HOMEexport JAVA_HOME=/opt/module/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin

- 使文件立即生效:
[[email protected] ~]# source /etc/profile //使文件立即生效[[email protected] ~]# java -version //测试jdk是否安装成功,即下面出现版本号
-- java version "1.8.0_171" --
(4)Hadoop集群安装搭建(slave1一样)
1.解压和环境变量
- 解压安装Hadoop:
- 解压:
/*查看将要解药的文件
[[email protected] ~]# cd /opt/package //进入package目录
[[email protected] package]# ls //查看
-- hadoop-2.7.7.tar.gz jdk-8u171-linux-x64.tar.gz --
*/
/*
解压:
[[email protected] package]# tar -zxvf hadoop-2.7.7.tar.gz -C /opt/module/ //解压到 /opt/module/ 目录中
*/
[[email protected] package]# ls /opt/module //解压完成后查看module有没有,可以看见多了个文件
-- hadoop-2.7.7 jdk1.8 --
- 改名:为了后面操作简单点
[[email protected] package]# cd //回到主目录[[email protected] ~]# cd /opt/module //进入module目录
[[email protected] module]# mv hadoop-2.7.7/ hadoop2.7 //改名
[[email protected] module]# ls //查看
-- hadoop2.7 jdk1.8 --
- 配置Hadoop环境变量:
/*获取Hadoop路径:
[[email protected] module]# cd hadoop2.7 //进入Hadoop2.7目录
[[email protected] jdk1.8]# pwd //查看目录结构,并记住
-- /opt/module/hadoop2.7 --
*/
/*
进入profile文件,添加jdk环境变量:
[[email protected] jdk1.8]# cd //回到主目录
[[email protected] ~]# sudo vim /etc/profile //进入文件
*/
在 profile 文件末尾添加 Hadoop 路径,我的添加内容如下:
##HADOOP_HOMEexport HADOOP_HOME=/opt/module/hadoop2.7
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin

- 使文件立即生效:
[[email protected] ~]# source /etc/profile //使配置文件立即生效[[email protected] ~]# hadoop version //测试Hadoop是否安装成功,即下面出现版本号
-- Hadoop 2.7.7 --
- 解压:
2.Hadoop目录结构
- 首先查看一下我没在Hadoop中需要了解的目录结构:
[[email protected] ~]# ll /opt/module/hadoop2.7 //查看解压的 Hadoop包生成的目录下的结构
其中重要目录:
| 目录 | 作用 |
|---|---|
| bin | 存放对 Hadoop 相关服务(HDFS,YARN)进行操作的脚本 |
| etc | Hadoop 的配置文件目录,存放 Hadoop 的配置文件 |
| lib | 存放 Hadoop 的本地库(对数据进行压缩解压缩功能) |
| sbin | 存放启动或停止 Hadoop 相关服务的脚本 |
| share | 存放 Hadoop 的依赖 jar 包、文档、和官方案例 |
3.配置
注意:下面 slaves 配置是master主机特有
3.1配置hadoop-env.sh:
[[email protected] ~]# vim /opt/module/hadoop2.7/etc/hadoop/hadoop-env.sh //进入 编辑内容:向文件中 export JAVA_HOME= 后面添加 jdk 的安装路径
export JAVA_HOME=/opt/module/jdk1.8

3.2配置 core-site.xml (核心组件):
- 需要先在 opt/module/hadoop2.7 目录下创建一个tmp目录
/*创建目录:
[[email protected] ~]# sudo mkdir /opt/module/hadoop2.7/tmp //创建tmp目录
[[email protected] ~]# ls /opt/module/hadoop2.7 //查看目录
-- bin include libexec NOTICE.txt sbin tmp
etc lib LICENSE.txt README.txt share --
*/
[[email protected] ~]# vim /opt/module/hadoop2.7/etc/hadoop/core-site.xml //进入文件
需要在 【 】中添加以下内容:
<!-- 指定 HDFS 中 NameNode 的地址 --><!-- 默认节点(写自己主机的ip)端口,端口默认为9000 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://192.168.6.10:9000</value>
</property>
<!-- 指定 Hadoop 运行时产生文件的存储目录 -->
<!-- hdfs的临时文件的目录***这个要记好,后面初始化错误可能会用到*** -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/module/hadoop2.7/tmp</value>
<description>Abase for other temporary directories.</description>
</property>

3.3配置 hdfs-site.xml(文件系统):
- 需要先在tmp目录下再创建个 name 和 data m目录
/*创建目录:
[[email protected] ~]# sudo mkdir /opt/module/hadoop2.7/tmp/name //创建name目录
[[email protected] ~]# sudo mkdir /opt/module/hadoop2.7/tmp/data //创建data目录
[[email protected] ~]# ls /opt/module/hadoop2.7/tmp //查看目录
-- data name --
*/
[[email protected] ~]# vim /opt/module/hadoop2.7/etc/hadoop/hdfs-site.xml //进入文件
需要在 【 】中添加以下内容:
<!-- 设置数据块应该被复制的份数(和集群机器数量相等,目前只有2个,以后有几台就填几台) --><property>
<name>dfs.replication</name>
<value>2</value>
</property>
<!-- namenode备用节点,目前只有一个填主机的IP地址 -->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>192.168.6.10:50090</value>
</property>
<!--指定NameNode运行产生的文件存储目录-->
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/module/hadoop2.7/tmp/name</value>
</property>
<!--指定DataNode运行产生的文件存储目录-->
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/module/hadoop2.7/tmp/data</value>
</property>

3.4配置 mapred-site.xml.template 文件(计算框架文件):
- 首先将 mapred-site.xml.template 文件改名为 mapred-site.xml
/*文件改名:
[[email protected] ~]# cd /opt/module/hadoop2.7/etc/hadoop //进入目标所在目录
[[email protected] hadoop]# mv mapred-site.xml.template mapred-site.xml //改名
[[email protected] hadoop]# ls //查看有没有 mapred-site.xml 文件
[[email protected] hadoop]# cd //返回主目录
*/
[[email protected] ~]# vim /opt/module/hadoop2.7/etc/hadoop/mapred-site.xml //进入
需要在 【 】中添加以下内容:
<!--配置JobTracker的地址和端口--><property>
<name>mapred.job.tracker</name>
<value>http://master.hadoop:9001</value>
</property>
<!-- mapreduce的工作模式:yarn -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<!-- mapreduce的工作地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>master.hadoop:10020</value>
</property>
<!-- web页面访问历史服务端口的配置 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master.hadoop:19888</value>
</property>

3.5配置 yarn-site.xml 文件:
[[email protected] ~]# vim /opt/module/hadoop2.7/etc/hadoop/yarn-site.xml 需要在 【 】中添加以下内容:一般情况下只添加前两个就行
<!-- reducer获取数据方式 --><property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!--客户端通过该地址向RM提交应用程序,杀死应用程序等。-->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master.hadoop</value>
</property>
<!--ApplicationMaster通过该地址向RM申请资源、释放资源等。-->
<property>
<name>yarn.resourcemanager.scheduler.hostname</name>
<value>master.hadoop</value>
</property>
<!--NodeManager通过该地址向RM汇报心跳,领取任务等。-->
<property>
<name>yarn.resourcemanager.resource-tracker.hostname</name>
<value>master.hadoop</value>
</property>
!--管理员通过该地址向RM发送管理命令等。-->
<property>
<name>yarn.resourcemanager.admin.hostname</name>
<value>master.hadoop</value>
</property>
<!--用户可通过该地址在浏览器中查看集群各类信息-->
<property>
<name>yarn.resourcemanager.webapp.hostname</name>
<value>master.hadoop</value>
</property>
<!-- 日志聚集功能使用 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 日志保留时间设置7天 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>

3.6配置 slaves 文件:(Master主机特有)
[[email protected] ~]# vim /opt/module/hadoop2.7/etc/hadoop/slaves 配置类容:
了解:伪分布式时:slaves文件中master主机即作为 NameNode ,也作为DataNode;而完全分布式时:master主机作为 NameNode ,slave1 从机作为DataNode。所以下面我们需要写入从机名
slave1.hadoop
3.7配置masters文件:
[[email protected] ~]# vim /opt/module/hadoop2.7/etc/hadoop/masters 配置内容:masters这是一个新文件,我们只再里面添加自己的主机IP
192.168.6.10
(5)远程复制(推荐)
- 原因:
- 我们已经完成了master主机的Hadoop文件配置,所以现在需要去为slave1从机配置Hadoop文件
- 方法一:根据当前slave1实际情况,且按照上面master的方法为slave1配置
- 方法二:将配置好的master主机下的 /opt/module/hadoop2.7/ 下的所有文件克隆到slave1下的 /opt/module/hadoop2.7 文件下
- 而方法二是相对方便的,所以我选则的时采用方法二的方
- 我们已经完成了master主机的Hadoop文件配置,所以现在需要去为slave1从机配置Hadoop文件
- 克隆:方法二(注意:按自己的目录结构进行远程复制)
[[email protected] ~]# scp -r /opt/module/hadoop2.7/* [email protected]:/opt/module/hadoop2.7- master 文件复制到slave1后,slave1中由于主机名和IP等与master不同,所以需要对slave1中的配置进行稍微改动

改动如上图下文:
| 文件 | 改动 |
|---|---|
| hadoop-evn.sh | 查看jdk路径是否是本机的路径 |
| core-site.xml | 将里面的master的 IP 改为本机的 IP |
| hdfs-site.xml | 将里面的master的 IP 改为本机的 IP |
| mapred-site.xml | 将里面master的主机名改为当前主机名 |
| yarn-site.xml | 将里面master的主机名改为当前主机名 |
| slaves(master特有) | 去掉里面的slave1从机的主机名 |
| masters | 去掉里面master 的IP |
| slave1 | 向里面添加本机的IP |
5.启动集群
5.1格式化HDFS文件系统(slave1一样)
- 第一次启动时格式化,以后就不要总格式化
- 这里如果安装的时候多次初始化,会导致错误,解决方法是删除
/opt/hadoop目录下的tmp文件
[[email protected] ~]# hdfs namenode -format5.2.启动(slave1一样)
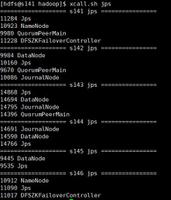
[[email protected] ~]# start-all.sh //启动[[email protected] ~]# jps //查看
master:jps
**slave1: **jps
查看web网页:
http://192.168.6.10:50070

5.3关闭集群
stop-all.sh以上是 Centos mini Hadoop集群搭建 的全部内容, 来源链接: utcz.com/a/121000.html