
【安卓】百度信息流和搜索业务中的弹性近线计算探索与应用 | 文末送福利
百度信息流和搜索业务中的弹性近线计算探索与应用 | 文末送福利
百度架构师发布于 今天 07:47
导读:在生产环境的PaaS平台中,为了应对流量增长、负载尖峰、软硬件升级、大规模局部故障等,通常需要留有一定的资源冗余。百度信息流和搜索服务在全网提供超过5个9的可用性,为了应对极端情况,各个地域的PaaS集群在设计上都有一定资源冗余。此外,为了控制成本,业务迭代需要取得合理的投入产出比之后,才能正式上线推全。因此,我们结合推荐系统和搜索系统的业务特点,设计并实现了一套介于在线和离线之间的弹性近线计算架构。相比于在线计算,突破计算速度限制,为业务计算复杂度提供了更大空间;相比于离线批量计算,提供了时效性更强,稳定性更高的策略计算方式。
一、背景
推荐系统、搜索系统的在线服务这种计算场景,整个负载随流量波动,而流量存在明显的波峰波谷。大部分用户会在什么时候看新闻,刷信息流,搜索等存在一定的规律,例如上班通勤的路上刷信息流、睡前刷信息流等。
但在线服务的资源备货必须要按照流量最高峰期的负载来准备,另外为了容灾,设计上需要有一定的部署冗余,实际部署的资源会比高峰期所需要的资源更多,因此在线集群中存在可以挖掘的冗余资源,在实际的生产环境中,集群的利用率一般不会超过60%。

△在线系统CPU利用率波动及其资源冗余示意图
此外,在线计算系统一般有严格的速度指标限制。以推荐系统为例,用户一次下拉刷新,需要在指定的时间内返推荐回结果给用户。受限于速度指标的限制,一次在线计算的计算规模也受到了限制,包括一次推荐计算覆盖的候选集受限以及召回和排序等计算的模型复杂程度也受限。
在这样的背景之下,我们开始尝试在百度的信息流推荐系统和搜索系统中引入近线计算。一方面,通过架构和业务联合设计,将复杂计算迁移到近线系统,从而突破在线计算的速度限制,进行更大规模的策略计算,提升业务效果;另一方面,通过弹性的设计,它能够充分利用在线集群的闲散资源进行策略计算,降低整个近线计算机制的成本。
二、整体思路

△弹性近线计算整体的思路
简要来说,弹性近线计算的整体思路是采用异步计算的方式,把复杂策略计算与在线计算解耦。
首先在线计算系统缓存中间结果或者独立建设复杂的业务近线计算流程,再通过一定的触发信号,触发近线计算,提前计算中间结果。在线服务响应请求时,直接使用提前算好的计算结果做低复杂度的在线处理之后响应请求,这样就绕开了在线计算的速度限制,可以进行复杂度高、计算量大的业务计算。另外就是在系统存在冗余资源的时候,可以结合历史的触发信号进行到访预估,主动发起近线计算,优化资源利用提升业务效果。
整个系统最重要的部分在于为了适配闲散资源,节约整个近线计算机制的成本。我们设计了一整套动态算力和动态参数的机制。
首先根据PaaS集群自身的负载情况,进行动态的超发,获取超额算力。
第二是设计跟负载相关的业务参数,根据动态算力的情况,决定整个近线计算的业务参数,释放出和算力相匹配的负载,从而平稳&充分的可利用资源。平稳,指的是缺资源的时候,系统能自动降级,避免系统雪崩无法自愈,充分指的是没有自然负载的时候,我们结合业务需要,主动计算,充分利用算力,最终提升业务效果。
第三是为了优化资源的利用,对资源使用情况进行预估和规划。一方面错峰调度资源,提高扩展资源调度的成功率;另一方面结合资源情况,分配计算负载,提升资源的利用效率。最后,针对非高峰期,资源冗余的情况下,需要估算整个系统的容量,再根据剩余的算力,发起主动近线计算,充分利用资源,提升业务效果。
另外,为了争取更多的算力,系统中同时支持CPU/GPU和昆仑芯片等类型的资源,因此需要考虑在异构算力模块上调度计算负载。另外,计算集群分布在全国各地,所以系统设计上,也需要考虑如何利用跨地域的算力。
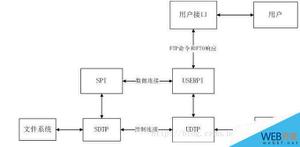
三、系统架构

_△_弹性近线计算系统_整体_架构简图
弹性近线计算系统主要包括几个子系统。
· 触发控制系统
主要负责根据业务参数,控制近线计算的触发,达到削峰填谷的目的。
· 动态算力和动态调参系统
它相当于弹性近线计算系统的大脑,根据集群的资源情况,分配近线计算算力;再根据算力情况,计算控制参数,从而控制跟算力匹配的负载。
· 历史数据中心
保存近线计算历史的计算记录。可以根据资源的情况,复用历史计算结果,来调节对算力的使用。
· 业务近线计算&控制系统
这个主要是和业务接入近线计算相关的一些架构机制设计,比如说输入输出缓存的读写,计算的拆包/并包等等,业务计算与失败信号的反馈等等。
· 业务在线接入
部分主要是业务接入近线计算系统上的一些设计。这块主要考虑的是如何高效的接入业务,避免业务接入过高的架构人力成本。
四、算力来源
1)扩展资源池
弹性近线计算使用的冗余资源(下文称扩展资源)来源主要包括两个方面。

△可超发资源示意图
首先,集群分配了但是没使用的资源,为什么呢?
第一,流量存在峰谷,但资源一般按照高峰期的负载准备,因此非高峰期存在资源空闲。
第二,由于Feed和搜索在线服务对外提供超过5个9的稳定性保证,要应对的机房故障除了硬件层面的故障之外,更多的也包括频繁的业务迭代,复杂的部署环境等造成的故障。因此即使在高峰期,机房的负载也是存在设计上的冗余。
举个例子,任何时刻当一个机房出现故障的时候,其它机房能够承接的这个故障机房的流量进行止损。
其次是碎片资源,PaaS集群的分配率是不可能到100%的,总是存在一些无法满足业务quota需求的资源碎片资源,这些也是近线计算可以利用的资源。
因此,通过监控PaaS集群资源的使用情况,基于历史资源使用数据情况进行预估,形成一个扩展资源池,这个过程可以用如下公示表示:
![]()
![]()

综上所述,在线大规模混布背景下的扩展资源特性:1)不稳定;2)供给量大。
不稳定主要来自于混布环境下,资源热点可能随时随机出现,再加上常态的机房间切流,因此扩展资源实例不稳定。
另外,由于是混布的集群,因此所有PaaS上的模块的闲置资源都可以统一利用,整体扩展资源的供给量很大。
2)XPU扩展资源挖掘和利用

△XPU资源调度系统架构简图
由于XPU(这里是对GPU和昆仑芯片的统称)资源与CPU资源的差异,虽然XPU本身已经支持共享,但XPU共享本质上还是分时复用的共享方式,所以如何保证共享XPU不影响在线业务的速度就是一个问题。为了利用冗余的XPU资源,在PaaS之上设计了一套XPU上的模型调度系统,核心子系统包括:
首先,在节点层面,设计一个模型容器,在实例内部进行模型调度,它根据远程拓扑管理系统中的元数据,决定实例具体执行什么模型。
第二,通过扩展PaaS的K8S Operator,在一个APP中,按照资源需求将实例划分给不同的业务,比如说在线和近线,使得每个APP可以承载多个模型的计算。
第三,资源预估系统会根据实际各个模型的资源需求情况,调整不同模型的资源。另外资源调整之后,涉及异构算力的负载分配和和削峰填谷的参数调整等。
第四,所有对业务模型的访问都通过名字服务寻址,获取具体的模型到计算实例的映射。通过独立的调度,隔离了近线计算的XPU共享对在线业务的干扰。
五、在线近线混合计算架构

△近线在线混合计算架构
考虑到业务同学已经对原有在线业务的研发架构比较熟悉,为了降低业务接入的学习成本,我们设计了一种通用的在线服务和近线服务混合计算架构,通过微服务进程间的上下文数据交换机制,对业务同学屏蔽近线计算开发细节,让业务可以用开发线逻辑的形式来开发近线逻辑,从而通过一套代码,两套部署,实现任意中间数据的在线和近线混合计算。
另外,业务计算模块为了适配扩展资源,需要做一些特殊的设计。
· 服务分片
如果一个模块需要加载太大量的数据,那么需要将该模块进行分片化处理,不同的分片计算不同的数据,限制模块的quota粒度在100个逻辑核,15G内存以下。
· 计算拆包
如果模型计算复杂,单次计算的粒度大影响成功率。通过计算拆包,即使部分计算结果失败,不会导致全部的计算结果不可用。
六、计算触发控制

△计算触发控制示意图
触发控制系统根据资源情况,以及不同触发源的优先级,来触发近线计算。
系统在收到触发信号之后,需要处理削峰和填谷两个方面的工作。
一方面,在资源不足时,通过控制业务计算参数来对流量进行削峰。如果通过预先设计的计算参数的削峰不一定能控制负载以匹配更低的算力,尤其是搜索这种检索词分布特别散的业务场景,在资源不足时,对触发信号按需进行保存,延迟触发。
另一方面,在资源一旦出现冗余,就可以把主动触发的信号提取出来触发近线计算,包括:1)削峰机制保存的信号。2)系统预估的会到访的流量;3)以及历史全量的触发信号索引,按照优先级进行主动触发。

△实际计算qps

_△_填谷信号qps
因此这里还涉及到对整个近线计算系统的容量进行预估,预估完成之后,根据系统自然负载控制主动触发的负载的水位,保持系统整体计算的负载不要超过系统的预估容量,达到平稳和均衡使用资源的目的。
七、负载&算力智能调度
由于近线计算大量使用扩展资源,算力上难免存在波动。
原因主要有几个方面,从大的层面说,由于局部系统故障,或者流量冗余度压测,业务经常在机房之间做流量迁移,就是说把A机房的流量,打到B机房,来验证机房的冗余度或者容灾。
从小的层面来说,混布环境下,调度不均衡或者有意或者无意的资源超用,导致局部资源热点,造成扩展资源退场。因此需要根据实时的资源情况,在机房之间调度负载,另外就是XPU与CPU资源由于计算能力不同,需要进行资源系数的学习和调度。

△算力调度与计算量调度系统示意图
从资源层面来说,一个近线计算任务往往涉及上下游多个模块的交互。由于上下游各模块都使用的动态扩展资源,就涉及到因为局部资源热点造成上下游模块利用率不均衡的情况,因此需要不断动态的在全链路的模块之间做资源均衡。第二个是随着负载波动,以及算力的波动,计算任务之间需要做资源均衡。第三个是由于资源调度的高峰往往和流量的高峰重叠,因此需要在流量高峰到来之前,预估近线计算所需要的资源,提前分配,错峰调度。
实践下来,通过错峰调度,预估资源需求并提前分配计算资源是比较有效的提升算力的办法,可以理解是如果在资源已经紧张的时候,再进行近线计算模块的调度,新的近线计算模块的算力消耗有概率本身就造成局部热点,导致扩展资源被回收,造成调度失败。

△负载调度效果示意图
八、基于历史计算结果优化资源利用
在系统中我们会把历史计算结果存下来,结合近线计算算力不稳定的特点,来优化资源利用。在系统计算资源充足时,用历史上当前用户偏好较高的文章取出来重复计算,扩大计算候选集,提升业务效果。在资源不足时,将历史上认为跟当前用户不太相关的资源进行过滤,提高资源使用效率。

△近线计算历史结果复用
第二个是到访预估。系统会跟进历史上用户的到访记录,预估用户的到访时间。主要是提高用户计算结果的时效性。因为不断的会有新内容会出现,策略模型也在不断的更新,我们希望新的内容与新的模型尽快的出现在近线计算的结果中。另外,像Feed这种场景第一刷的质量非常重要,从我们的实验结果也能看出来,通过主动计算,提升了DAU。
第三个是对历史触发信号进行保存和索引。按照不同的优先级记录历史触发信号,从而可以按照业务自定义的优先级进行刷库,针对推送这种业务场景,就非常的有用,通过全库刷新,及时的把新模型和新资源能够推送到用户。
九、典型应用案例
以下介绍典型的应用场景。
典型应用一:Feed在线&近线混合计算架构

△Feed混合计算-近线召回队列示意图
图上是我们最早在Feed中的近线和在线混合召回计算落地的一种场景。
在推荐算法服务这一层,每个推荐算法对应召回的是数千或者数万条的计算结果,由于资源和速度的限制,我们不能对这数千或者数万条结果都进行粗排,并且粗排的模型也需要控制复杂程度。因此我们考虑将多个推荐算法服务的召回结果进行缓存,再放到近线系统来进行综合打分之后生成一个用户对应的近线计算候选集,作为一路新的召回。之后在线请求来了之后,使用这路新的召回结果,进行轻量的在线计算之后就可以返回给用户。
这样就把召回层初步排序打分的计算规模提升了1个数量级。
这里主要涉及到的调参场景包括:
1)根据算力情况,决定一个用户的计算频率,举例来说,就是资源充足时,每个用户在一定时间内只算一次,资源不足时,逐渐提高计算间隔,降低计算频率。
2)预估用户的到访时间,根据系统容量的冗余程度,提前更新用户的近线计算结果。
典型应用二:搜索结果排序

△搜索结果相关性近线计算示意图
另外一个典型的应用是弹性近线计算在搜索产品的落地。
这个系统中由于涉及基于Transformer的复杂模型,用到了XPU资源和CPU资源的混合计算。业务上跟推荐的排序类似,我们把搜索的相关性计算放在近线计算系统进行排序,计算检索词跟对应的搜索结果的相关性排序。
跟推荐场景不同的是,搜索的场景下,检索词的全集更大,因此我们针对这种场景,用上了更激进的削峰填谷机制,如果没有足够的算力,直接将触发信号缓存到消息队列,在低谷期再把计算完成。
总结
2018年落地以来,弹性近线计算已经支持了CPU、GPU、昆仑芯片等异构算力,在百度Feed推荐业务和搜索相关性业务落地。在Feed推荐业务落地超过10个业务场景,已经累计带来大盘时长和分发带来超过2位数的增长。在搜索业务落地3个业务场景,并支持复杂语义模型,在搜索业务落地,显著提升搜索视频搜索、问答搜索的相关性和用户体验。随着更复杂的模型的落地以及更多目标的模型叠加,弹性近线计算系统将发挥更大的作用,低成本地助力业务增长。

△搜索产品用户体验评估
本期作者 | 卢嘉龙,百度资深研发工程师
吕辉明,百度高级研发工程师
聂勇,百度高级研发工程师
本期福利
本期百度架构师送出
“城市剪影·变色马克杯”20份!

注入90-100℃热水
杯体自动呈现城市剪影图
科技感与设计感结合
为这个冬日留守在城市的你提供一份温暖
参与方式
公众号后台回复【抽奖】即可参与抽奖
还可邀请好友助力,大幅提升中奖机会
快来参与吧!
原文链接:https://mp.weixin.qq.com/s/0xkeTfXFWWclet5qp3JjvQ
百度架构师
百度官方技术公众号上线啦!
技术干货 · 行业资讯 · 线上沙龙 · 行业大会
招聘信息 · 内推信息 · 技术书籍 · 百度周边
欢迎各位同学关注!

cssjavascriptjavaandroid前端
阅读 11发布于 今天 07:47
本作品系原创,采用《署名-非商业性使用-禁止演绎 4.0 国际》许可协议
百度架构师
公众号【百度架构师】
9 声望
2 粉丝
百度架构师
公众号【百度架构师】
9 声望
2 粉丝
宣传栏
目录
导读:在生产环境的PaaS平台中,为了应对流量增长、负载尖峰、软硬件升级、大规模局部故障等,通常需要留有一定的资源冗余。百度信息流和搜索服务在全网提供超过5个9的可用性,为了应对极端情况,各个地域的PaaS集群在设计上都有一定资源冗余。此外,为了控制成本,业务迭代需要取得合理的投入产出比之后,才能正式上线推全。因此,我们结合推荐系统和搜索系统的业务特点,设计并实现了一套介于在线和离线之间的弹性近线计算架构。相比于在线计算,突破计算速度限制,为业务计算复杂度提供了更大空间;相比于离线批量计算,提供了时效性更强,稳定性更高的策略计算方式。
一、背景
推荐系统、搜索系统的在线服务这种计算场景,整个负载随流量波动,而流量存在明显的波峰波谷。大部分用户会在什么时候看新闻,刷信息流,搜索等存在一定的规律,例如上班通勤的路上刷信息流、睡前刷信息流等。
但在线服务的资源备货必须要按照流量最高峰期的负载来准备,另外为了容灾,设计上需要有一定的部署冗余,实际部署的资源会比高峰期所需要的资源更多,因此在线集群中存在可以挖掘的冗余资源,在实际的生产环境中,集群的利用率一般不会超过60%。
△在线系统CPU利用率波动及其资源冗余示意图
此外,在线计算系统一般有严格的速度指标限制。以推荐系统为例,用户一次下拉刷新,需要在指定的时间内返推荐回结果给用户。受限于速度指标的限制,一次在线计算的计算规模也受到了限制,包括一次推荐计算覆盖的候选集受限以及召回和排序等计算的模型复杂程度也受限。
在这样的背景之下,我们开始尝试在百度的信息流推荐系统和搜索系统中引入近线计算。一方面,通过架构和业务联合设计,将复杂计算迁移到近线系统,从而突破在线计算的速度限制,进行更大规模的策略计算,提升业务效果;另一方面,通过弹性的设计,它能够充分利用在线集群的闲散资源进行策略计算,降低整个近线计算机制的成本。
二、整体思路
△弹性近线计算整体的思路
简要来说,弹性近线计算的整体思路是采用异步计算的方式,把复杂策略计算与在线计算解耦。
首先在线计算系统缓存中间结果或者独立建设复杂的业务近线计算流程,再通过一定的触发信号,触发近线计算,提前计算中间结果。在线服务响应请求时,直接使用提前算好的计算结果做低复杂度的在线处理之后响应请求,这样就绕开了在线计算的速度限制,可以进行复杂度高、计算量大的业务计算。另外就是在系统存在冗余资源的时候,可以结合历史的触发信号进行到访预估,主动发起近线计算,优化资源利用提升业务效果。
整个系统最重要的部分在于为了适配闲散资源,节约整个近线计算机制的成本。我们设计了一整套动态算力和动态参数的机制。
首先根据PaaS集群自身的负载情况,进行动态的超发,获取超额算力。
第二是设计跟负载相关的业务参数,根据动态算力的情况,决定整个近线计算的业务参数,释放出和算力相匹配的负载,从而平稳&充分的可利用资源。平稳,指的是缺资源的时候,系统能自动降级,避免系统雪崩无法自愈,充分指的是没有自然负载的时候,我们结合业务需要,主动计算,充分利用算力,最终提升业务效果。
第三是为了优化资源的利用,对资源使用情况进行预估和规划。一方面错峰调度资源,提高扩展资源调度的成功率;另一方面结合资源情况,分配计算负载,提升资源的利用效率。最后,针对非高峰期,资源冗余的情况下,需要估算整个系统的容量,再根据剩余的算力,发起主动近线计算,充分利用资源,提升业务效果。
另外,为了争取更多的算力,系统中同时支持CPU/GPU和昆仑芯片等类型的资源,因此需要考虑在异构算力模块上调度计算负载。另外,计算集群分布在全国各地,所以系统设计上,也需要考虑如何利用跨地域的算力。
三、系统架构
_△_弹性近线计算系统_整体_架构简图
弹性近线计算系统主要包括几个子系统。
· 触发控制系统
主要负责根据业务参数,控制近线计算的触发,达到削峰填谷的目的。
· 动态算力和动态调参系统
它相当于弹性近线计算系统的大脑,根据集群的资源情况,分配近线计算算力;再根据算力情况,计算控制参数,从而控制跟算力匹配的负载。
· 历史数据中心
保存近线计算历史的计算记录。可以根据资源的情况,复用历史计算结果,来调节对算力的使用。
· 业务近线计算&控制系统
这个主要是和业务接入近线计算相关的一些架构机制设计,比如说输入输出缓存的读写,计算的拆包/并包等等,业务计算与失败信号的反馈等等。
· 业务在线接入
部分主要是业务接入近线计算系统上的一些设计。这块主要考虑的是如何高效的接入业务,避免业务接入过高的架构人力成本。
四、算力来源
1)扩展资源池
弹性近线计算使用的冗余资源(下文称扩展资源)来源主要包括两个方面。
△可超发资源示意图
首先,集群分配了但是没使用的资源,为什么呢?
第一,流量存在峰谷,但资源一般按照高峰期的负载准备,因此非高峰期存在资源空闲。
第二,由于Feed和搜索在线服务对外提供超过5个9的稳定性保证,要应对的机房故障除了硬件层面的故障之外,更多的也包括频繁的业务迭代,复杂的部署环境等造成的故障。因此即使在高峰期,机房的负载也是存在设计上的冗余。
举个例子,任何时刻当一个机房出现故障的时候,其它机房能够承接的这个故障机房的流量进行止损。
其次是碎片资源,PaaS集群的分配率是不可能到100%的,总是存在一些无法满足业务quota需求的资源碎片资源,这些也是近线计算可以利用的资源。
因此,通过监控PaaS集群资源的使用情况,基于历史资源使用数据情况进行预估,形成一个扩展资源池,这个过程可以用如下公示表示:
![]()
![]()
综上所述,在线大规模混布背景下的扩展资源特性:1)不稳定;2)供给量大。
不稳定主要来自于混布环境下,资源热点可能随时随机出现,再加上常态的机房间切流,因此扩展资源实例不稳定。
另外,由于是混布的集群,因此所有PaaS上的模块的闲置资源都可以统一利用,整体扩展资源的供给量很大。
2)XPU扩展资源挖掘和利用
△XPU资源调度系统架构简图
由于XPU(这里是对GPU和昆仑芯片的统称)资源与CPU资源的差异,虽然XPU本身已经支持共享,但XPU共享本质上还是分时复用的共享方式,所以如何保证共享XPU不影响在线业务的速度就是一个问题。为了利用冗余的XPU资源,在PaaS之上设计了一套XPU上的模型调度系统,核心子系统包括:
首先,在节点层面,设计一个模型容器,在实例内部进行模型调度,它根据远程拓扑管理系统中的元数据,决定实例具体执行什么模型。
第二,通过扩展PaaS的K8S Operator,在一个APP中,按照资源需求将实例划分给不同的业务,比如说在线和近线,使得每个APP可以承载多个模型的计算。
第三,资源预估系统会根据实际各个模型的资源需求情况,调整不同模型的资源。另外资源调整之后,涉及异构算力的负载分配和和削峰填谷的参数调整等。
第四,所有对业务模型的访问都通过名字服务寻址,获取具体的模型到计算实例的映射。通过独立的调度,隔离了近线计算的XPU共享对在线业务的干扰。
五、在线近线混合计算架构
△近线在线混合计算架构
考虑到业务同学已经对原有在线业务的研发架构比较熟悉,为了降低业务接入的学习成本,我们设计了一种通用的在线服务和近线服务混合计算架构,通过微服务进程间的上下文数据交换机制,对业务同学屏蔽近线计算开发细节,让业务可以用开发线逻辑的形式来开发近线逻辑,从而通过一套代码,两套部署,实现任意中间数据的在线和近线混合计算。
另外,业务计算模块为了适配扩展资源,需要做一些特殊的设计。
· 服务分片
如果一个模块需要加载太大量的数据,那么需要将该模块进行分片化处理,不同的分片计算不同的数据,限制模块的quota粒度在100个逻辑核,15G内存以下。
· 计算拆包
如果模型计算复杂,单次计算的粒度大影响成功率。通过计算拆包,即使部分计算结果失败,不会导致全部的计算结果不可用。
六、计算触发控制
△计算触发控制示意图
触发控制系统根据资源情况,以及不同触发源的优先级,来触发近线计算。
系统在收到触发信号之后,需要处理削峰和填谷两个方面的工作。
一方面,在资源不足时,通过控制业务计算参数来对流量进行削峰。如果通过预先设计的计算参数的削峰不一定能控制负载以匹配更低的算力,尤其是搜索这种检索词分布特别散的业务场景,在资源不足时,对触发信号按需进行保存,延迟触发。
另一方面,在资源一旦出现冗余,就可以把主动触发的信号提取出来触发近线计算,包括:1)削峰机制保存的信号。2)系统预估的会到访的流量;3)以及历史全量的触发信号索引,按照优先级进行主动触发。
△实际计算qps
_△_填谷信号qps
因此这里还涉及到对整个近线计算系统的容量进行预估,预估完成之后,根据系统自然负载控制主动触发的负载的水位,保持系统整体计算的负载不要超过系统的预估容量,达到平稳和均衡使用资源的目的。
七、负载&算力智能调度
由于近线计算大量使用扩展资源,算力上难免存在波动。
原因主要有几个方面,从大的层面说,由于局部系统故障,或者流量冗余度压测,业务经常在机房之间做流量迁移,就是说把A机房的流量,打到B机房,来验证机房的冗余度或者容灾。
从小的层面来说,混布环境下,调度不均衡或者有意或者无意的资源超用,导致局部资源热点,造成扩展资源退场。因此需要根据实时的资源情况,在机房之间调度负载,另外就是XPU与CPU资源由于计算能力不同,需要进行资源系数的学习和调度。
△算力调度与计算量调度系统示意图
从资源层面来说,一个近线计算任务往往涉及上下游多个模块的交互。由于上下游各模块都使用的动态扩展资源,就涉及到因为局部资源热点造成上下游模块利用率不均衡的情况,因此需要不断动态的在全链路的模块之间做资源均衡。第二个是随着负载波动,以及算力的波动,计算任务之间需要做资源均衡。第三个是由于资源调度的高峰往往和流量的高峰重叠,因此需要在流量高峰到来之前,预估近线计算所需要的资源,提前分配,错峰调度。
实践下来,通过错峰调度,预估资源需求并提前分配计算资源是比较有效的提升算力的办法,可以理解是如果在资源已经紧张的时候,再进行近线计算模块的调度,新的近线计算模块的算力消耗有概率本身就造成局部热点,导致扩展资源被回收,造成调度失败。
△负载调度效果示意图
八、基于历史计算结果优化资源利用
在系统中我们会把历史计算结果存下来,结合近线计算算力不稳定的特点,来优化资源利用。在系统计算资源充足时,用历史上当前用户偏好较高的文章取出来重复计算,扩大计算候选集,提升业务效果。在资源不足时,将历史上认为跟当前用户不太相关的资源进行过滤,提高资源使用效率。
△近线计算历史结果复用
第二个是到访预估。系统会跟进历史上用户的到访记录,预估用户的到访时间。主要是提高用户计算结果的时效性。因为不断的会有新内容会出现,策略模型也在不断的更新,我们希望新的内容与新的模型尽快的出现在近线计算的结果中。另外,像Feed这种场景第一刷的质量非常重要,从我们的实验结果也能看出来,通过主动计算,提升了DAU。
第三个是对历史触发信号进行保存和索引。按照不同的优先级记录历史触发信号,从而可以按照业务自定义的优先级进行刷库,针对推送这种业务场景,就非常的有用,通过全库刷新,及时的把新模型和新资源能够推送到用户。
九、典型应用案例
以下介绍典型的应用场景。
典型应用一:Feed在线&近线混合计算架构
△Feed混合计算-近线召回队列示意图
图上是我们最早在Feed中的近线和在线混合召回计算落地的一种场景。
在推荐算法服务这一层,每个推荐算法对应召回的是数千或者数万条的计算结果,由于资源和速度的限制,我们不能对这数千或者数万条结果都进行粗排,并且粗排的模型也需要控制复杂程度。因此我们考虑将多个推荐算法服务的召回结果进行缓存,再放到近线系统来进行综合打分之后生成一个用户对应的近线计算候选集,作为一路新的召回。之后在线请求来了之后,使用这路新的召回结果,进行轻量的在线计算之后就可以返回给用户。
这样就把召回层初步排序打分的计算规模提升了1个数量级。
这里主要涉及到的调参场景包括:
1)根据算力情况,决定一个用户的计算频率,举例来说,就是资源充足时,每个用户在一定时间内只算一次,资源不足时,逐渐提高计算间隔,降低计算频率。
2)预估用户的到访时间,根据系统容量的冗余程度,提前更新用户的近线计算结果。
典型应用二:搜索结果排序
△搜索结果相关性近线计算示意图
另外一个典型的应用是弹性近线计算在搜索产品的落地。
这个系统中由于涉及基于Transformer的复杂模型,用到了XPU资源和CPU资源的混合计算。业务上跟推荐的排序类似,我们把搜索的相关性计算放在近线计算系统进行排序,计算检索词跟对应的搜索结果的相关性排序。
跟推荐场景不同的是,搜索的场景下,检索词的全集更大,因此我们针对这种场景,用上了更激进的削峰填谷机制,如果没有足够的算力,直接将触发信号缓存到消息队列,在低谷期再把计算完成。
总结
2018年落地以来,弹性近线计算已经支持了CPU、GPU、昆仑芯片等异构算力,在百度Feed推荐业务和搜索相关性业务落地。在Feed推荐业务落地超过10个业务场景,已经累计带来大盘时长和分发带来超过2位数的增长。在搜索业务落地3个业务场景,并支持复杂语义模型,在搜索业务落地,显著提升搜索视频搜索、问答搜索的相关性和用户体验。随着更复杂的模型的落地以及更多目标的模型叠加,弹性近线计算系统将发挥更大的作用,低成本地助力业务增长。
△搜索产品用户体验评估
本期作者 | 卢嘉龙,百度资深研发工程师
吕辉明,百度高级研发工程师
聂勇,百度高级研发工程师
本期福利
本期百度架构师送出
“城市剪影·变色马克杯”20份!
注入90-100℃热水
杯体自动呈现城市剪影图
科技感与设计感结合
为这个冬日留守在城市的你提供一份温暖
参与方式
公众号后台回复【抽奖】即可参与抽奖
还可邀请好友助力,大幅提升中奖机会
快来参与吧!
原文链接:https://mp.weixin.qq.com/s/0xkeTfXFWWclet5qp3JjvQ
百度架构师
百度官方技术公众号上线啦!
技术干货 · 行业资讯 · 线上沙龙 · 行业大会
招聘信息 · 内推信息 · 技术书籍 · 百度周边
欢迎各位同学关注!
以上是 【安卓】百度信息流和搜索业务中的弹性近线计算探索与应用 | 文末送福利 的全部内容, 来源链接: utcz.com/a/109665.html



得票时间