爬取比比网中标标书,并保存为PDF格式文件
![爬取比比网中标标书,并保存为PDF格式文件[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/1026205845_1.jpg)
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于CSDN,作者嗨学编程

python开发环境
- python 3.6
- pycharm
import requestsimport parsel
import pdfkit
import time
相关模块pip安装即可
目标网页分析
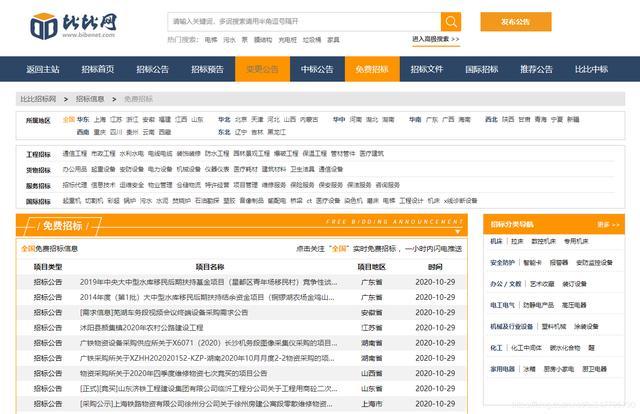
1、先从列表页中获取详情页的URL地址
是静态网站,可以直接请求网页获取数据
for page in range(1, 31): url = "https://www.bibenet.com/mfzbu{}.html".format(page)
headers = {
"Referer": "https://www.bibenet.com/mianfei/",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.138 Safari/537.36"
}
response = requests.get(url=url, headers=headers)
selector = parsel.Selector(response.text)
urls = selector.css("body > div.wrap > div.clearFiex > div.col9.fl > div.secondary_box > table tr .fl a::attr(href)").getall()
for page_url in urls:
print(page_url)
2、从详情页中获取标题以及内容
response_2 = requests.get(url=page_url, headers=headers)selector_2 = parsel.Selector(response_2.text)
article = selector_2.css(".container").get()
title = selector_2.css(".detailtitle::text").get()
3、保存html网页数据并转成PDF
html_str = """<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Document</title>
</head>
<body>
{article}
</body>
</html>
"""
def download(article, title):
html = html_str.format(article=article)
html_path = "D:pythondemo招标网文书" + title + ".html"
pdf_path = "D:pythondemo招标网文书" + title + ".pdf"
with open(html_path, mode="wb", encoding="utf-8") as f:
f.write(html)
print("{}已下载完成".format(title))
# exe 文件存放的路径
config = pdfkit.configuration(wkhtmltopdf="C:Program Fileswkhtmltopdfinwkhtmltopdf.exe")
# 把 html 通过 pdfkit 变成 pdf 文件
pdfkit.from_file(html_path, pdf_path, configuration=config)
运行实现效果
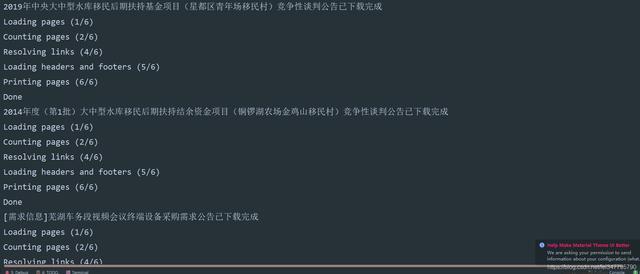
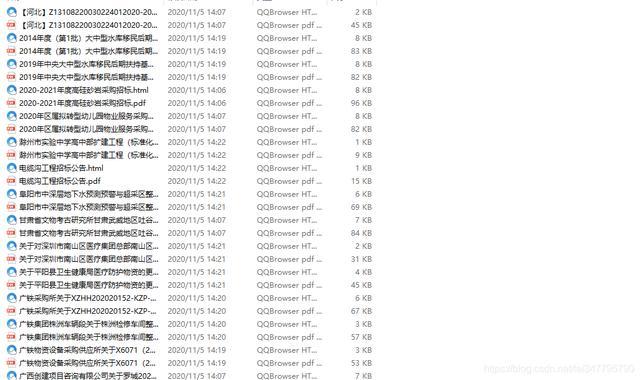
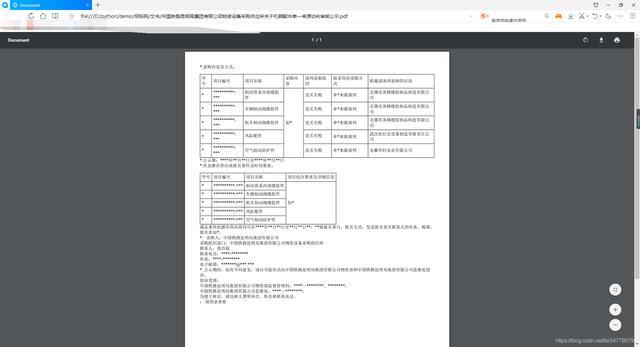
以上是 爬取比比网中标标书,并保存为PDF格式文件 的全部内容, 来源链接: utcz.com/z/538002.html