用75W条捐赠数据,来分析谁当总统的概率更大
![用75W条捐赠数据,来分析谁当总统的概率更大[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/1798210525_1.jpg)
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
以下文章来源于天池大数据科研平台,作者简说Python
前言
本文通过Pandas分析了美国选民2020.7.22-2020.8.20期间的75w+条捐赠数据,分析揭秘美国选民对总统候选人的喜好,主要带领读者利用Python进行数据分析以及数据可视化,包含数据集的处理、数据探索与清晰、数据分析、数据可视化四部分,利用pandas、matplotlib、wordcloud等第三方库带大家玩转数据分析~
项目地址:
https://tianchi.aliyun.com/competition/entrance/531837/introduction数据集来源介绍
「所有候选人信息(weball20.txt)」
该文件为每个候选人提供一份记录,并显示候选人的信息、总收入、从授权委员会收到的转账、付款总额、给授权委员会的转账、库存现金总额、贷款和债务以及其他财务汇总信息。
数据字段描述详细:https://www.fec.gov/campaign-finance-data/all-candidates-file-description/
关键字段说明
- CAND_ID 候选人ID
- CAND_NAME 候选人姓名
- CAND_PTY_AFFILIATION 候选人党派
数据来源:https://www.fec.gov/files/bulk-downloads/2020/weball20.zip
「候选人委员会链接信息(ccl.txt)」
该文件显示候选人的身份证号码、候选人的选举年份、联邦选举委员会选举年份、委员会识别号、委员会类型、委员会名称和链接标识号。
信息描述详细:https://www.fec.gov/campaign-finance-data/candidate-committee-linkage-file-description/
关键字段说明
- CAND_ID 候选人ID
- CAND_ELECTION_YR 候选人选举年份
- CMTE_ID 委员会ID
数据来源:https://www.fec.gov/files/bulk-downloads/2020/ccl20.zip
「个人捐款档案信息(itcont_2020_20200722_20200820.txt)」
【注意】由于文件较大,本数据集只包含2020.7.22-2020.8.20的相关数据,如果需要更全数据可以通过数据来源中的地址下载。
该文件包含有关收到捐款的委员会、披露捐款的报告、提供捐款的个人、捐款日期、金额和有关捐款的其他信息。
信息描述详细:https://www.fec.gov/campaign-finance-data/contributions-individuals-file-description/
关键字段说明
- CMTE_ID 委员会ID
- NAME 捐款人姓名
- CITY 捐款人所在市
- State 捐款人所在州
- EMPLOYER 捐款人雇主/公司
- OCCUPATION 捐款人职业
数据来源:https://www.fec.gov/files/bulk-downloads/2020/indiv20.zip
需要提前安装的包
# 安装词云处理包wordcloudpip install wordcloud
# 数据可视化包matplotlib
pip install matplotlib
# 数据处理包pandas
pip install pandas
需要提前下载好数据集
「方法一:」 本文相关数据集国内下载地址如下,访问后即可直接下载到本地:
https://tianchi.aliyun.com/dataset/dataDetail?dataId=79412
然后在本地复现本文案例代码;
「方法二:」 你也可以直接 访问下方链接 报名参与相关学习赛:
https://tianchi.aliyun.com/competition/entrance/531837/introduction然后Fork赛事论坛的baseline到你的天池实验室,并点击编辑按钮就可以成功跳转到DSW在线编程环境了,你可以直接在哪里进行编程和数据集下载,更加方便。本案例数据集2020_US_President_political_contributions
数据处理
进行数据处理前,我们需要知道我们最终想要的数据是什么样的,因为我们是想分析候选人与捐赠人之间的关系,所以我们想要一张数据表中有捐赠人与候选人一一对应的关系,所以需要将目前的三张数据表进行一一关联,汇总到需要的数据。
将委员会和候选人一一对应,通过CAND_ID关联两个表
由于候选人和委员会的联系表中无候选人姓名,只有候选人ID(CAND_ID),所以需要通过CAND_ID从候选人表中获取到候选人姓名,最终得到候选人与委员会联系表ccl。
# 导入相关处理包import pandas as pd
# 读取候选人信息,由于原始数据没有表头,需要添加表头
candidates = pd.read_csv("weball20.txt", sep = "|",names=["CAND_ID","CAND_NAME","CAND_ICI","PTY_CD","CAND_PTY_AFFILIATION","TTL_RECEIPTS",
"TRANS_FROM_AUTH","TTL_DISB","TRANS_TO_AUTH","COH_BOP","COH_COP","CAND_CONTRIB",
"CAND_LOANS","OTHER_LOANS","CAND_LOAN_REPAY","OTHER_LOAN_REPAY","DEBTS_OWED_BY",
"TTL_INDIV_CONTRIB","CAND_OFFICE_ST","CAND_OFFICE_DISTRICT","SPEC_ELECTION","PRIM_ELECTION","RUN_ELECTION"
,"GEN_ELECTION","GEN_ELECTION_PRECENT","OTHER_POL_CMTE_CONTRIB","POL_PTY_CONTRIB",
"CVG_END_DT","INDIV_REFUNDS","CMTE_REFUNDS"])
# 读取候选人和委员会的联系信息
ccl = pd.read_csv("ccl.txt", sep = "|",names=["CAND_ID","CAND_ELECTION_YR","FEC_ELECTION_YR","CMTE_ID","CMTE_TP","CMTE_DSGN","LINKAGE_ID"])
# 关联两个表数据
ccl = pd.merge(ccl,candidates)
# 提取出所需要的列
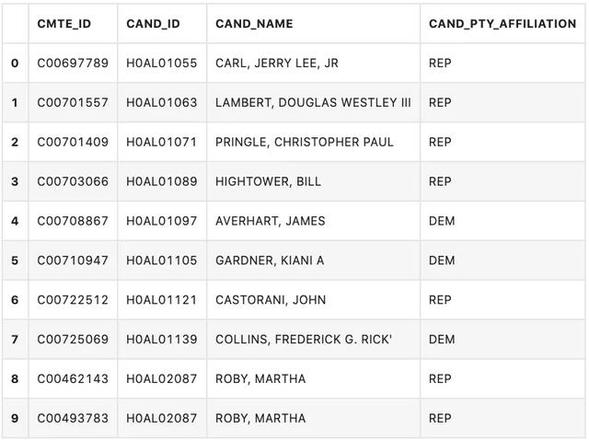
ccl = pd.DataFrame(ccl, columns=[ "CMTE_ID","CAND_ID", "CAND_NAME","CAND_PTY_AFFILIATION"])
数据字段说明:
- CMTE_ID:委员会ID
- CAND_ID:候选人ID
- CAND_NAME:候选人姓名
- CAND_PTY_AFFILIATION:候选人党派
# 查看目前ccl数据前10行ccl.head(10)
2.2 将候选人和捐赠人一一对应,通过CMTE_ID关联两个表
通过CMTE_ID将目前处理好的候选人和委员会关系表与人捐款档案表进行关联,得到候选人与捐赠人一一对应联系表cil。
python基础 爬虫、数据分析
# 读取个人捐赠数据,由于原始数据没有表头,需要添加表头# 提示:读取本文件大概需要5-10s
itcont = pd.read_csv("itcont_2020_20200722_20200820.txt", sep="|",names=["CMTE_ID","AMNDT_IND","RPT_TP","TRANSACTION_PGI",
"IMAGE_NUM","TRANSACTION_TP","ENTITY_TP","NAME","CITY",
"STATE","ZIP_CODE","EMPLOYER","OCCUPATION","TRANSACTION_DT",
"TRANSACTION_AMT","OTHER_ID","TRAN_ID","FILE_NUM","MEMO_CD",
"MEMO_TEXT","SUB_ID"])
/opt/conda/lib/python3.6/site-packages/IPython/core/interactiveshell.py:3058: DtypeWarning: Columns (10,15,16,18) have mixed types. Specify dtype option on import or set low_memory=False. interactivity=interactivity, compiler=compiler, result=result)
# 将候选人与委员会关系表ccl和个人捐赠数据表itcont合并,通过 CMTE_IDc_itcont = pd.merge(ccl,itcont)
# 提取需要的数据列
c_itcont = pd.DataFrame(c_itcont, columns=[ "CAND_NAME","NAME", "STATE","EMPLOYER","OCCUPATION",
"TRANSACTION_AMT", "TRANSACTION_DT","CAND_PTY_AFFILIATION"])
「数据说明」
- CAND_NAME – 接受捐赠的候选人姓名
- NAME – 捐赠人姓名
- STATE – 捐赠人所在州
- EMPLOYER – 捐赠人所在公司
- OCCUPATION – 捐赠人职业
- TRANSACTION_AMT – 捐赠数额(美元)
- TRANSACTION_DT – 收到捐款的日期
- CAND_PTY_AFFILIATION – 候选人党派
# 查看目前数据前10行c_itcont.head(10)
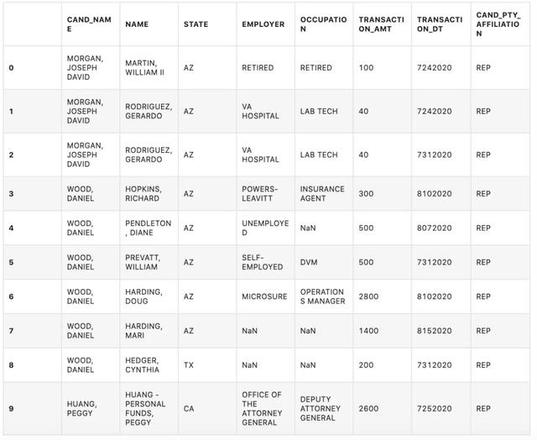
数据探索与清洗
经过数据处理部分,我们获得了可用的数据集,现在我们可以利用调用shape属性查看数据的规模,调用info函数查看数据信息,调用describe函数查看数据分布。
# 查看数据规模 多少行 多少列c_itcont.shape
(756205, 8)
# 查看整体数据信息,包括每个字段的名称、非空数量、字段的数据类型c_itcont.info()
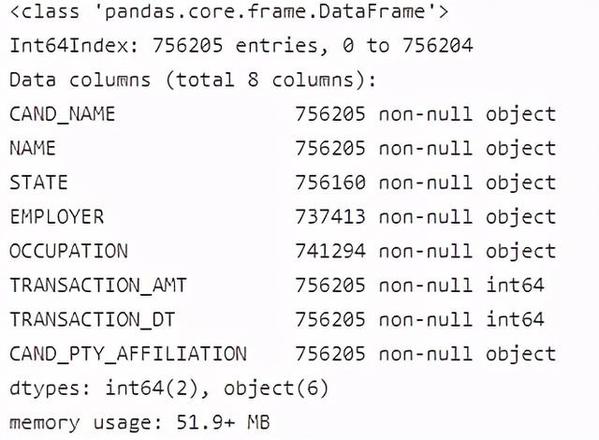
通过上面的探索我们知道目前数据集的一些基本情况,目前数据总共有756205行,8列,总占用内存51.9+MB,STATE、EMPLOYER、OCCUPATION有缺失值,另外日期列目前为int64类型,需要进行转换为str类型。
#空值处理,统一填充 NOT PROVIDEDc_itcont["STATE"].fillna("NOT PROVIDED",inplace=True)
c_itcont["EMPLOYER"].fillna("NOT PROVIDED",inplace=True)
c_itcont["OCCUPATION"].fillna("NOT PROVIDED",inplace=True)
# 对日期TRANSACTION_DT列进行处理c_itcont["TRANSACTION_DT"] = c_itcont["TRANSACTION_DT"] .astype(str)
# 将日期格式改为年月日 7242020
c_itcont["TRANSACTION_DT"] = [i[3:7]+i[0]+i[1:3] for i in c_itcont["TRANSACTION_DT"] ]
# 再次查看数据信息c_itcont.info()
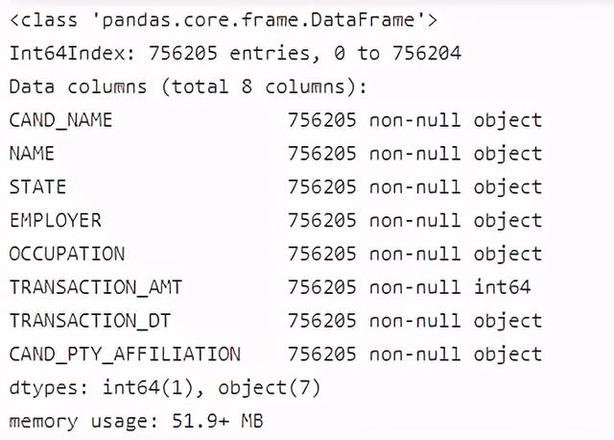
# 查看数据前3行c_itcont.head(3)
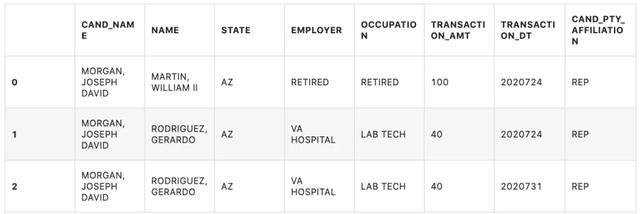
# 查看数据表中数据类型的列的数据分布情况c_itcont.describe()
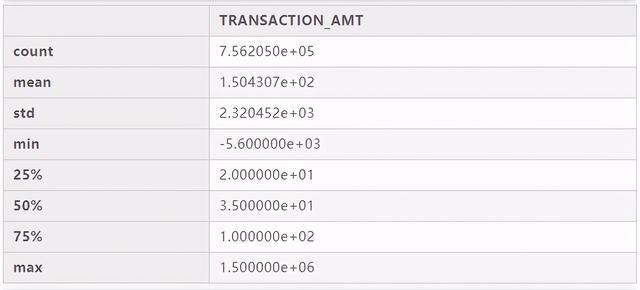
# 查看单列的数据发布情况c_itcont["CAND_NAME"].describe()
4、数据分析
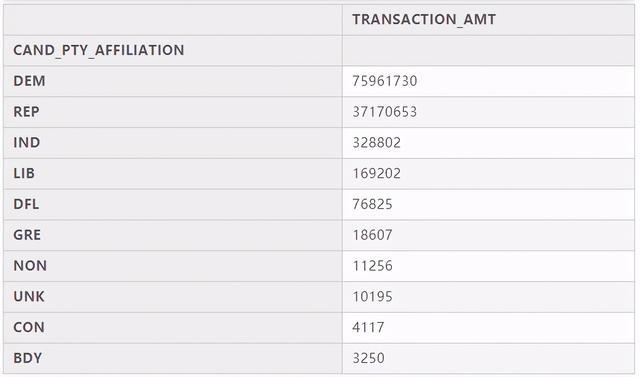
# 计算每个党派的所获得的捐款总额,然后排序,取前十位c_itcont.groupby("CAND_PTY_AFFILIATION").sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)
# 计算每个总统候选人所获得的捐款总额,然后排序,取前十位c_itcont.groupby("CAND_NAME").sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)
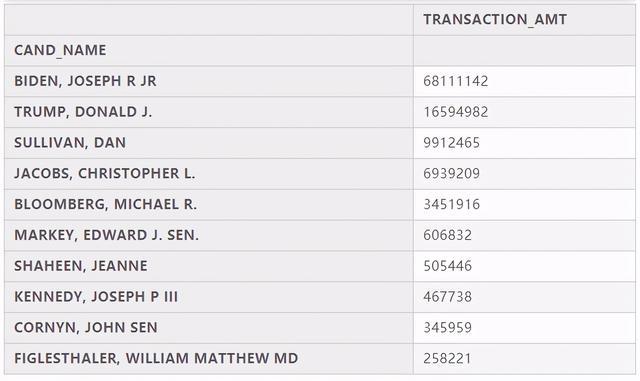
获得捐赠最多的党派有DEM(民主党)、REP(共和党),分别对应BIDEN, JOSEPH R JR(拜登)和TRUMP, DONALD J.(特朗普),从我们目前分析的2020.7.22-2020.8.20这一个月的数据来看,在选民的捐赠数据中拜登代表的民主党完胜特朗普代表的共和党,由于完整数据量过大,所以没有对所有数据进行汇总分析,因此也不能确定11月大选公布结果就一定是拜登当选
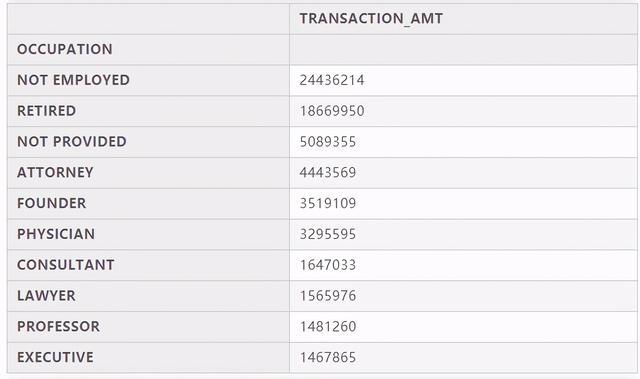
# 查看不同职业的人捐款的总额,然后排序,取前十位c_itcont.groupby("OCCUPATION").sum().sort_values("TRANSACTION_AMT",ascending=False).head(10)
# 查看每个职业捐款人的数量c_itcont["OCCUPATION"].value_counts().head(10)
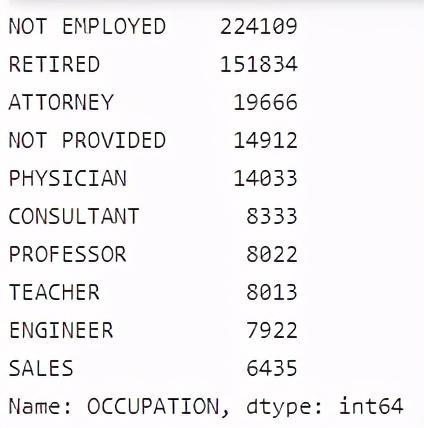
从捐款人的职业这个角度分析,我们会发现NOT EMPLOYED(自由职业)的总捐赠额是最多,通过查看每个职业捐赠的人数来看,我们就会发现是因为NOT EMPLOYED(自由职业)人数多的原因,另外退休人员捐款人数也特别多,所以捐款总数对应的也多,其他比如像:律师、创始人、医生、顾问、教授、主管这些高薪人才虽然捐款总人数少,但是捐款总金额也占据了很大比例。
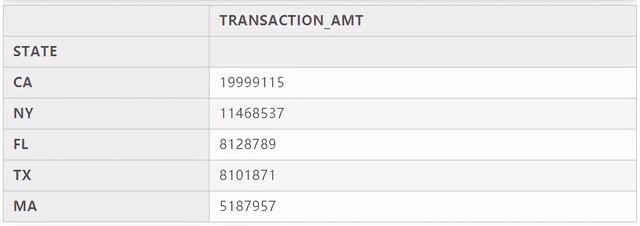
# 每个州获捐款的总额,然后排序,取前五位c_itcont.groupby("STATE").sum().sort_values("TRANSACTION_AMT",ascending=False).head(5)
# 查看每个州捐款人的数量c_itcont["STATE"].value_counts().head(5)
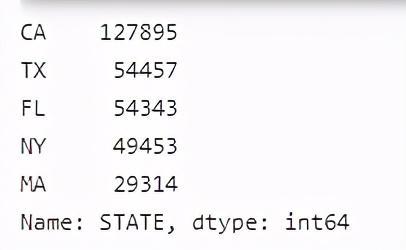
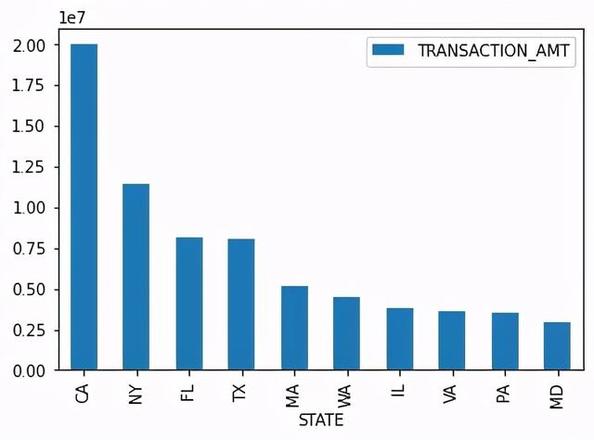
最后查看每个州的捐款总金额,我们会发现CA(加利福利亚)、NY(纽约)、FL(弗罗里达)这几个州的捐款是最多的,在捐款人数上也是在Top端,另一方面也凸显出这些州的经济水平发达。大家也可以通过数据查看下上面列举的高端职业在各州的分布情况,进行进一步的分析探索。
数据可视化
首先导入相关Python库
# 导入matplotlib中的pyplotimport matplotlib.pyplot as plt
# 为了使matplotlib图形能够内联显示
%matplotlib inline
# 导入词云库
from wordcloud import WordCloud,ImageColorGenerator
按州总捐款数和总捐款人数柱状图
# 各州总捐款数可视化st_amt = c_itcont.groupby("STATE").sum().sort_values("TRANSACTION_AMT",ascending=False)[:10]
st_amt=pd.DataFrame(st_amt, columns=["TRANSACTION_AMT"])
st_amt.plot(kind="bar")
<AxesSubplot:xlabel="STATE">
各州捐款总人数可视化
# 各州捐款总人数可视化,取前10个州的数据st_amt = c_itcont.groupby("STATE").size().sort_values(ascending=False).head(10)
st_amt.plot(kind="bar")
<AxesSubplot:xlabel="STATE">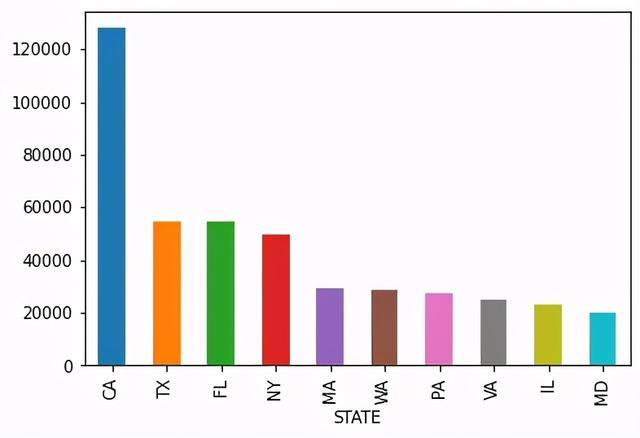
热门候选人拜登在各州的获得的捐赠占比
# 从所有数据中取出支持拜登的数据biden = c_itcont[c_itcont["CAND_NAME"]=="BIDEN, JOSEPH R JR"]
# 统计各州对拜登的捐款总数
biden_state = biden.groupby("STATE").sum().sort_values("TRANSACTION_AMT", ascending=False).head(10)
# 饼图可视化各州捐款数据占比
biden_state.plot.pie(figsize=(10, 10),autopct="%0.2f%%",subplots=True)
array([<AxesSubplot:ylabel="TRANSACTION_AMT">], dtype=object)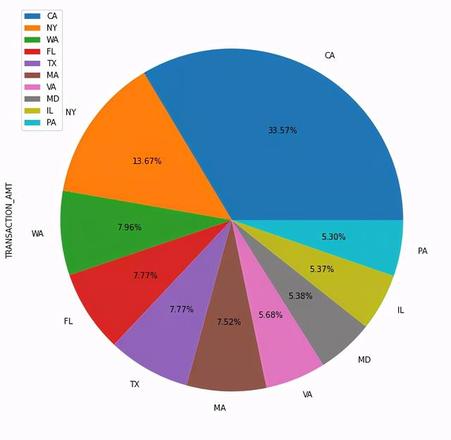
以上是 用75W条捐赠数据,来分析谁当总统的概率更大 的全部内容, 来源链接: utcz.com/z/537884.html