用Python爬取最炫国漫《雾山五行》,看看十万网友在说些啥,【词云】
![用 Python 爬取最炫国漫《雾山五行》,看看十万网友在说些啥,【词云】[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/2674211256_1.jpg)
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理
本文来自腾讯云,作者:Python小二
看动漫的小伙伴应该知道最近出了一部神漫《雾山五行》,其以极具特色的水墨画风和超燃的打斗场面广受好评,首集播出不到 24 小时登顶 B 站热搜第一,豆瓣开分 9.5,火爆程度可见一斑,就打斗场面而言,说是最炫动漫也不为过,当然唯一有一点不足之处就是集数有点少,只有 3 集。

看过动图之后,是不是觉得我所说的最炫动漫,并非虚言,接下来我们爬取一些评论,了解一下大家对这部动漫的看法,这里我们选取 B 站、微博和豆瓣这 3 个平台来爬取数据。
爬取 B 站
我们先来爬取 B 站弹幕数据,动漫链接为:https://www.bilibili.com/bangumi/play/ep331423,弹幕链接为:http://comment.bilibili.com/186803402.xml,爬取代码如下:
url = "http://comment.bilibili.com/218796492.xml"req
= requests.get(url)html
= req.contenthtml_doc
= str(html, "utf-8") # 修改成utf-8#
解析soup = BeautifulSoup(html_doc, "lxml")
results = soup.find_all("d")
contents = [x.text for x in results]
# 保存结果
dic = {"contents": contents}
df = pd.DataFrame(dic)
df["contents"].to_csv("bili.csv", encoding="utf-8", index=False)
如果对爬取 B 站弹幕数据不了解的小伙伴可以看一下:爬取 B 站弹幕。
我们接着将爬取的弹幕数据生成词云,代码实现如下:
def jieba_():# 打开评论数据文件content = open("bili.csv", "rb").read()
# jieba 分词
word_list = jieba.cut(content)
words = []
# 过滤掉的词
stopwords = open("stopwords.txt", "r", encoding="utf-8").read().split("
")[:-1]
for word in word_list:
if word notin stopwords:
words.append(word)
global word_cloud
# 用逗号隔开词语
word_cloud = ",".join(words)
def cloud():
# 打开词云背景图
cloud_mask = np.array(Image.open("bg.jpg"))
# 定义词云的一些属性
wc = WordCloud(
# 背景图分割颜色为白色
background_color="white",
# 背景图样
mask=cloud_mask,
# 显示最大词数
max_words=500,
# 显示中文
font_path="./fonts/simhei.ttf",
# 最大尺寸
max_font_size=60,
repeat=True
)
global word_cloud
# 词云函数
x = wc.generate(word_cloud)
# 生成词云图片
image = x.to_image()
# 展示词云图片
image.show()
# 保存词云图片
wc.to_file("cloud.jpg")
jieba_()
cloud()
看一下效果: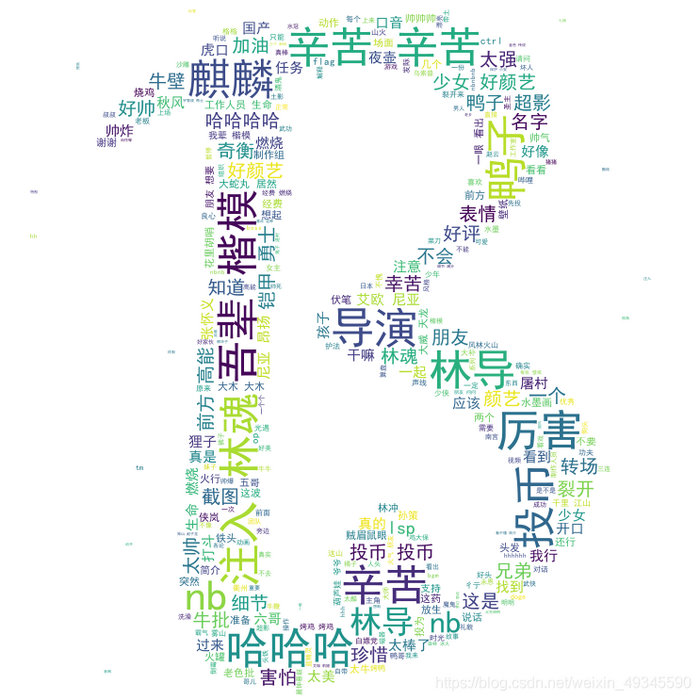
爬取微博
我们再接着爬取动漫的微博评论,我们选择的爬取目标是雾山五行官博顶置的这条微博的评论数据,如图所示: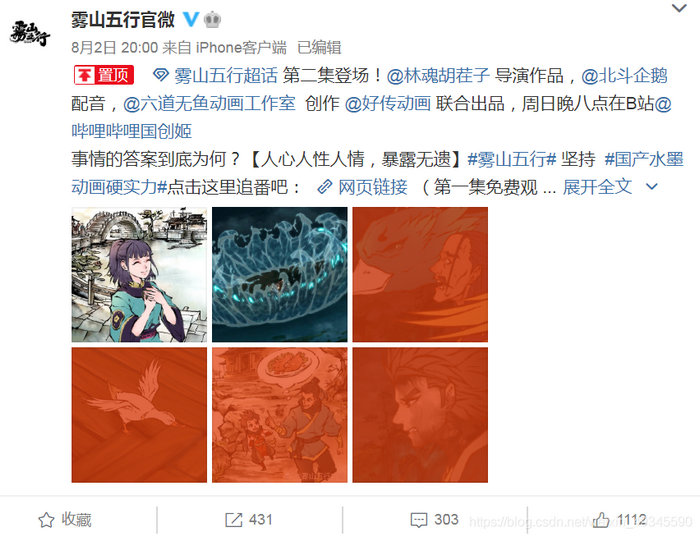
爬取代码实现如下所示:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)# 爬取一页评论内容def get_one_page(url):
headers = {
"User-agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3880.4 Safari/537.36",
"Host" : "weibo.cn",
"Accept" : "application/json, text/plain, */*",
"Accept-Language" : "zh-CN,zh;q=0.9",
"Accept-Encoding" : "gzip, deflate, br",
"Cookie" : "自己的cookie",
"DNT" : "1",
"Connection" : "keep-alive"
}
# 获取网页 html
response = requests.get(url, headers = headers, verify=False)
# 爬取成功
if response.status_code == 200:
# 返回值为 html 文档,传入到解析函数当中
return response.text
return None
# 解析保存评论信息
def save_one_page(html):
comments = re.findall("<span class="ctt">(.*?)</span>", html)
for comment in comments[1:]:
result = re.sub("<.*?>", "", comment)
if"回复@"notin result:
with open("wx_comment.txt", "a+", encoding="utf-8") as fp:
fp.write(result)
for i in range(50):
url = "https://weibo.cn/comment/Je5bqpmCn?uid=6569999648&rl=0&page="+str(i)
html = get_one_page(url)
print("正在爬取第 %d 页评论" % (i+1))
save_one_page(html)
time.sleep(3)
对于爬取微博评论不熟悉的小伙伴可以参考:爬取微博评论。
同样的,我们还是将评论生成词云,看一下效果:
爬取豆瓣
最后,我们爬取动漫的豆瓣评论数据,动漫的豆瓣地址为:https://movie.douban.com/subject/30395914/,爬取的实现代码如下:
def spider():url
= "https://accounts.douban.com/j/mobile/login/basic"headers
= {"User-Agent": "Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 6.0; Trident/4.0)"}# 评论网址,为了动态翻页,start 后加了格式化数字,短评页面有 20 条数据,每页增加 20 条url_comment = "https://movie.douban.com/subject/30395914/comments?start=%d&limit=20&sort=new_score&status=P"
data = {
"ck": "",
"name": "用户名",
"password": "密码",
"remember": "false",
"ticket": ""
}
session = requests.session()
session.post(url=url, headers=headers, data=data)
# 初始化 4 个 list 分别存用户名、评星、时间、评论文字
users = []
stars = []
times = []
content = []
# 抓取 500 条,每页 20 条,这也是豆瓣给的上限
for i in range(0, 500, 20):
# 获取 HTML
data = session.get(url_comment % i, headers=headers)
# 状态码 200 表是成功
print("第", i, "页", "状态码:",data.status_code)
# 暂停 0-1 秒时间,防止IP被封
time.sleep(random.random())
# 解析 HTML
selector = etree.HTML(data.text)
# 用 xpath 获取单页所有评论
comments = selector.xpath("//div[@class="comment"]")
# 遍历所有评论,获取详细信息
for comment in comments:
# 获取用户名
user = comment.xpath(".//h3/span[2]/a/text()")[0]
# 获取评星
star = comment.xpath(".//h3/span[2]/span[2]/@class")[0][7:8]
# 获取时间
date_time = comment.xpath(".//h3/span[2]/span[3]/@title")
# 有的时间为空,需要判断下
if len(date_time) != 0:
date_time = date_time[0]
date_time = date_time[:10]
else:
date_time = None
# 获取评论文字
comment_text = comment.xpath(".//p/span/text()")[0].strip()
# 添加所有信息到列表
users.append(user)
stars.append(star)
times.append(date_time)
content.append(comment_text)
# 用字典包装
comment_dic = {"user": users, "star": stars, "time": times, "comments": content}
# 转换成 DataFrame 格式
comment_df = pd.DataFrame(comment_dic)
# 保存数据
comment_df.to_csv("db.csv")
# 将评论单独再保存下来
comment_df["comments"].to_csv("comment.csv", index=False)
spider()
对于爬取豆瓣评论不熟悉的小伙伴,可以参考:爬取豆瓣评论。
看一下生成的词云效果:
以上是 用Python爬取最炫国漫《雾山五行》,看看十万网友在说些啥,【词云】 的全部内容, 来源链接: utcz.com/z/537720.html