
Python爬取新笔趣阁小说
![Python爬取新笔趣阁小说[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/2777211349_1.jpg)
Python爬取小说,并保存到TXT文件中
我写的这篇文章,是利用Python爬取小说编写的程序,这是我学习Python爬虫当中自己独立写的第一个程序,中途也遇到了一些困难,但是最后迎刃而解了。这个程序非常的简单,程序的大概就是先获取网页的源代码,然后在网页的源代码中提取每个章节的url,获取之后,在通过每个url去获取文章的内容,在进行提取内容,然后就是保存到本地,一TXT的文件类型保存。
大概是这样
1:获取网页源代码
2:获取每章的url
3:获取每章的内容
4:下载保存文件中
1、首先就是先安装第三方库requests,这个库,打开cmd,输入pip install requests回车就可以了,等待安装。然后测试
import resquests
2、然后就可以编写程序了,首先获取网页源代码,也可以在浏览器查看和这个进行对比。
s = requests.Session()url = "https://www.xxbiquge.com/2_2634/"
html = s.get(url)
html.encoding = "utf-8"
运行后显示网页源代码

按F12查看
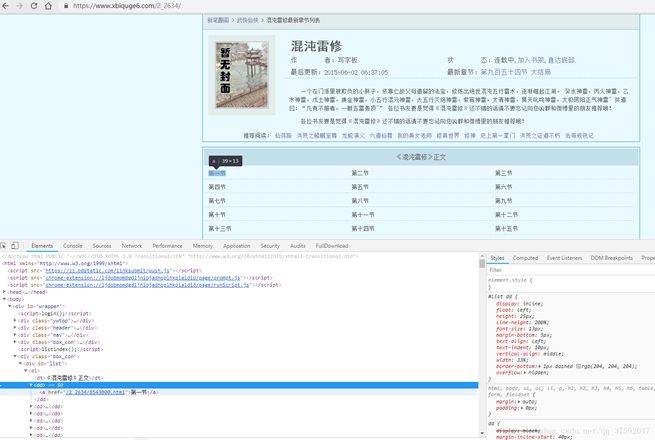
说明这是对的,
3、然后进行获取网页源代码中的每章url,进行提取
caption_title_1 = re.findall(r"<a href="(/2_2634/.*?.html)">.*?</a>",html.text)print(caption_title_1)

由于过多,就剪切了这些,看到这些URL,你可能想问为什么不是完整的,这是因为网页中的本来就不完整,需要进行拼凑得到完整的url

这样就完成了,就可以得到完整的了
4、下面就是获取章节名,和章节内容
#获取章节名name = re.findall(r"<meta name="keywords" content="(.*?)" />",r1.text)[0] # 提取章节名
print(name)
file_name.write(name)
file_name.write("
")
# 获取章节内容
chapters = re.findall(r"<div id="content">(.*?)</div>",r1.text,re.S)[0] #提取章节内容
chapters = chapters.replace(" ", "") # 后面的是进行数据清洗
chapters = chapters.replace("readx();", "")
chapters = chapters.replace("& lt;!--go - - & gt;", "")
chapters = chapters.replace("<!--go-->", "")
chapters = chapters.replace("()", "")
5、转换字符串和保存文件
# 转换字符串s = str(chapters)
s_replace = s.replace("<br/>","
")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r" ",re.I)
fiction = pattern.sub(" ",s_replace)
file_name.write(fiction)
file_name.write("
")
6、完整的代码
import requestsimport re
s = requests.Session()
url = "https://www.xxbiquge.com/2_2634/"
html = s.get(url)
html.encoding = "utf-8"
# 获取章节
caption_title_1 = re.findall(r"<a href="(/2_2634/.*?.html)">.*?</a>",html.text)
# 写文件
path = r"C:UsersAdministratorPycharmProjectsuntitled itle.txt" # 这是我存放的位置,你可以进行更改
file_name = open(path,"a",encoding="utf-8")
# 循环下载每一张
for i in caption_title_1:
caption_title_1 = "https://www.xxbiquge.com"+i
# 网页源代码
s1 = requests.Session()
r1 = s1.get(caption_title_1)
r1.encoding = "utf-8"
# 获取章节名
name = re.findall(r"<meta name="keywords" content="(.*?)" />",r1.text)[0]
print(name)
file_name.write(name)
file_name.write("
")
# 获取章节内容
chapters = re.findall(r"<div id="content">(.*?)</div>",r1.text,re.S)[0]
chapters = chapters.replace(" ", "")
chapters = chapters.replace("readx();", "")
chapters = chapters.replace("& lt;!--go - - & gt;", "")
chapters = chapters.replace("<!--go-->", "")
chapters = chapters.replace("()", "")
# 转换字符串
s = str(chapters)
s_replace = s.replace("<br/>","
")
while True:
index_begin = s_replace.find("<")
index_end = s_replace.find(">",index_begin+1)
if index_begin == -1:
break
s_replace = s_replace.replace(s_replace[index_begin:index_end+1],"")
pattern = re.compile(r" ",re.I)
fiction = pattern.sub(" ",s_replace)
file_name.write(fiction)
file_name.write("
")
file_name.close()
7、修改你想要爬取小说url后再进行运行,如果出现错误,可能是存放位置出错,可以再保存文件地址修改为你要存放的地址,然后就结束了
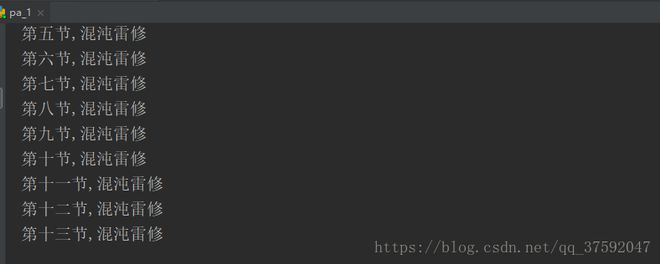

这就是爬取的完整的小说,是不是很简单,,希望能对你所帮助
以上是 Python爬取新笔趣阁小说 的全部内容, 来源链接: utcz.com/z/537697.html



