列举几个简单的例子来更好的理解scrapy工作的原理
![列举几个简单的例子来更好的理解scrapy工作的原理[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/2916211505_1.jpg)

说明:了解爬虫的可能都会知道,在爬虫里,requests入门简单,即使是没有基础的小白,学个几天也能简单的去请求网站,但是scrapy就相对来说就比较难,本片文章能是列举几个简单的例子去理解的scrapy工作的原理,理解了scrapy工作的原理之后,学起来就会简单很多
适用:本篇文章适合有一点的爬虫基础但又是刚刚接触或者想要学习scrapy的同学
scrapy框架:">scrapy框架:
scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。
scrapy框架的结构:
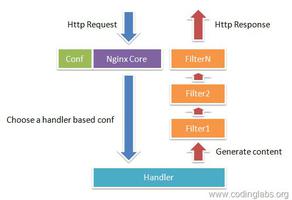
scrapy是一个5+2结构,见下图
5表示: 1. spiders(蜘蛛)
2. engine(引擎)
3. downloader(下载器)
4. scheduler(调度器)
5. item pipeline(项目管道)
2表示:
1. downloder middlewares(下载中间件)
2. spider middlewares(蜘蛛中间件)
[图片上传失败...(image-946ae8-1545285941079)]
接下来我们就列举几个列子来方便的理解scrapy原理:
先说一下爬虫,对于一个爬虫,整体来看,分为三个部分:
请求
就是请求网站,分为get和post
解析
就是解析网站返回的response,即对response进行进一步处理
存储
就是把处理过的信息存储到文件,或者数据库的操作

而scrapy框架也无外乎也是这分三个部分,下面是4个情景设定,都是学习scrapy刚开始会遇到的,在每个设定后面对其工作的原理给出了简单解释,之所以不写太过详细,是为了方便大家理解,让大家在大脑里面对scrapy框架有大致的轮廓:
设定一: 初始url:1个
是否解析:否
是否存储数据:否
(1)spider将初始url经过engine传递给scheduler,形成调度队列(1个requests)
(2)scheduler将requests经过engine调度给downloader进行数据下载,形成原始数据
设定二:
初始url:1个
是否解析:是
是否存储数据:否
(1)spider将初始url经过engine传递给scheduler,形成调度队列(1个requests)
(2)scheduler将requests经过engine调度给downloader进行数据下载,形成原始数据
(3)将原始数据经过engine传递给spider进行解析
设定三:
初始url:1个
是否解析:是
是否存储数据:是
(1)spider将初始url经过engine传递给scheduler,形成调度队列(多个requests)
(2)scheduler将第一个requests经过engine调度给downloader进行数据下载,形成原始数据
(3)将原始数据经过engine传递给spider进行解析
(4)将解析后的数据经过engine传给item pipeline进行数据存储
设定四:
初始url:多个
是否解析:是
是否存储数据:是
(1)spider将初始url经过engine传递给scheduler,形成调度队列(多个requests)
(2)scheduler将第一个requests经过engine调度给downloader进行数据下载,形成原始数据
(3)将原始数据经过engine传递给spider进行解析
(4)将解析后的数据经过engine传给item pipeline进行数据存储
(5)scheduler将下一个requests经过engine调度给downloader进行数据下载,形成原始数据......#重复(2)到(4)步,直到scheduler中没有更多的requests
本篇文章只是对scrapy框架的的原理进行的简单的讲解,想要精通scrapy框架,还需要进一步的学习......
关注我获取更多内容
注:转载还请注明出处,谢谢_
以上是 列举几个简单的例子来更好的理解scrapy工作的原理 的全部内容, 来源链接: utcz.com/z/537681.html