
Python爬取各种主要文档类型的方法简介
![Python爬取各种主要文档类型的方法简介[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/2955211526_1.jpg)
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理。
以下文章来源于python教程,作者:小雨
刚接触Python的新手、小白,可以复制下面的链接去免费观看Python的基础入门教学视频
https://v.douyu.com/author/y6AZ4jn9jwKW前言
HTML文档是互联网上的主要文档类型,但还存在如TXT、WORD、Excel、PDF、csv等多种类型的文档。网络爬虫不仅需要能够抓取HTML中的敏感信息,也需要有抓取其他类型文档的能力。下面简要记录一些个人已知的基于python3的抓取方法,以备查阅。


抓取TXT文档
在python3下,常用方法是使用urllib.request.urlopen方法直接获取。之后利用正则表达式等方式进行敏感词检索。
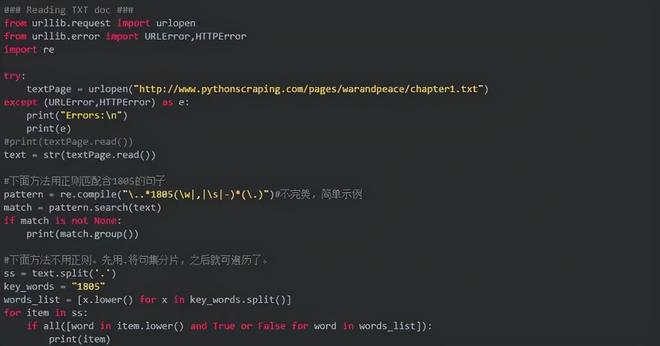
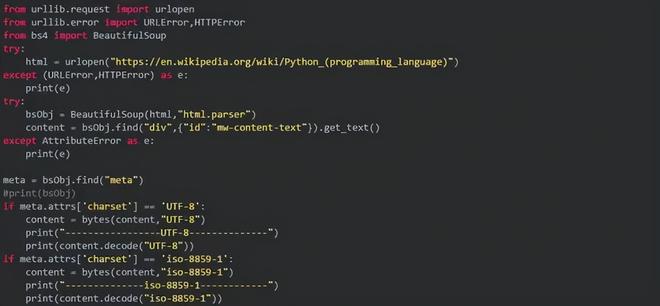
如果抓取的是某个HTML,最好先分析,例如:
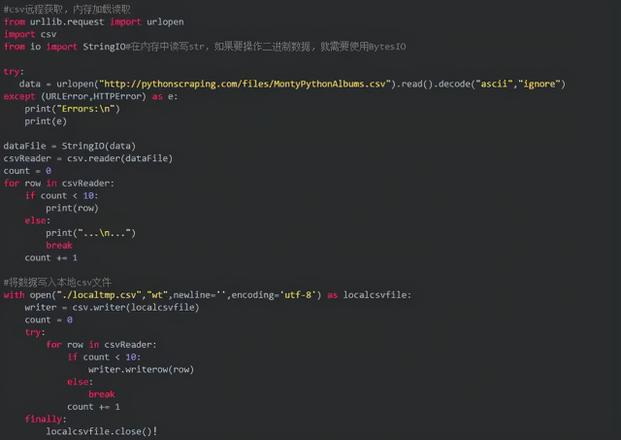
抓取CSV文档
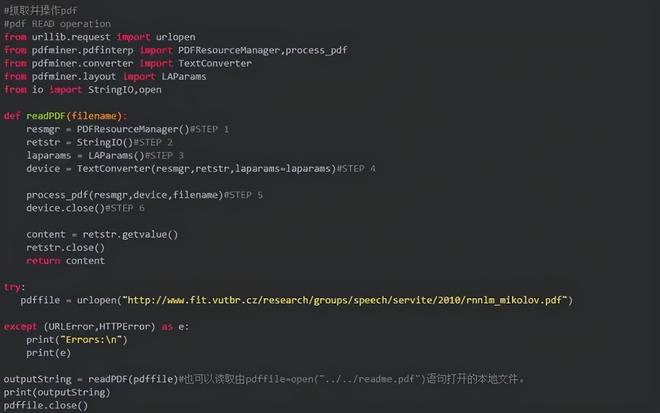
抓取PDF文档
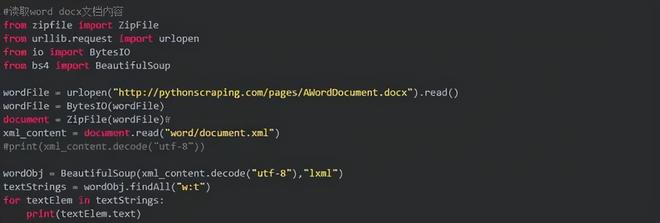
抓取word
方法:
(1)利用urlopen抓取远程word docx文件;
(2)将其转换为内存字节流;
(3)解压缩(docx是压缩后文件);
(4)将解压后的文件作为xml读取
(5)寻找xml中的标签(正文内容)并处理
以上是 Python爬取各种主要文档类型的方法简介 的全部内容, 来源链接: utcz.com/z/537677.html


