Github上目标检测项目:mmdetection项目初接触,安装学习过程记录。
![Github上目标检测项目: mmdetection项目初接触,安装学习过程记录。[Python基础]](/wp-content/uploads/new2022/20220602jjjkkk2/3083211628_1.jpg)
项目地址:https://github.com/open-mmlab/mmdetection
本人硬件:显卡 GTX3090+CUDA11.1,目前应该是最新的版本吧。
本篇文章分两部分,第一部分按root用户安装的,然后普通用户使用pycharm,进入root文件夹权限不够,然后就有了第二部分
第二部分是新建普通用户,在第一部分的基础上重新安装了一遍。。。
注意:请先确定电脑显卡是nvidia的,如果不是,就不能跑这个项目!
一、(一开始用的其他显卡的,采坑了)
1、安装Python
一般情况下ubuntu默认已经安装了python,如果没有安装,需要自己安装一下,具体百度下。
直接输入指令 python ,可以查看当前版本,可以看到已经有了3.5.2

已经进入到了python交互界面,
输入
print("Hello World!")
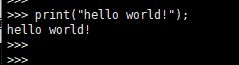
按 Ctrl +D 退出。
如果需要3.0以上的版本,也可以输入python3 ,查看是否安装了3.0的版本。

我需要的版本是3.6+,需要升级版本。
添加PPA第三方软件仓库,
执行
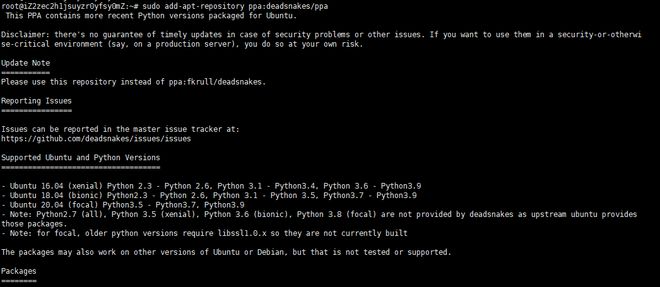
sudo add-apt-repository ppa:deadsnakes/ppa
可以看到ubuntu版本和匹配对应的python版本
然后更新资源库
sudo apt-get update安装
sudo apt-get install python3.7
为了方便,设置优先级,可以执行python,启动的就是3.0的版本,不用执行python3了。
sudo update-alternatives --install /usr/bin/python python /usr/bin/python3 150sudo update
-alternatives --install /usr/bin/python python /usr/bin/python2 100
因为我的电脑默认本来是3.5.2的,我想要3.7的,所以再执行下面的,设置3.7优先。
sudo update-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.51sudo update
-alternatives --install /usr/bin/python3 python3 /usr/bin/python3.72
设置完后,
再执行python,默认使用3.7版本的python,完成安装。

2、安装CUDA
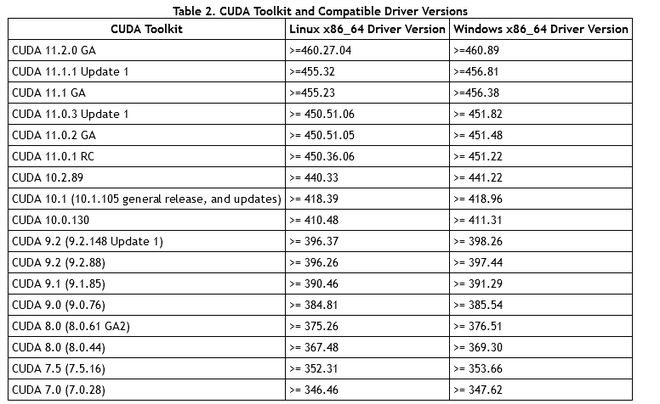
前提需要安装nvidia驱动、cuda和cudann,三者版本要一一匹配。主要是cuda版本要和驱动版本一致。
地址:https://docs.nvidia.com/cuda/cuda-toolkit-release-notes/index.html
2.1安装显卡驱动
测试电脑有没有nvida驱动,输入命令 nvidia-smi 如果识别不了,说明没有装。那么就要去下载驱动并安装。
首先要知道自己系统显卡的型号,才能去下载对应版本的驱动。
https://blog.csdn.net/maizousidemao/article/details/88821949
查看当前系统的显卡:lspci | grep -i nvidia
没反应,说明没有nvidia显卡
执行
lspci | grep -i vga
出现如下图,
00:02.0 VGA compatible controller: Cirrus Logic GD 5446

说明系统不是nvidia显卡。
没法继续了。。。。
终结!!
------------------------------------------------------------------
换nvidia显卡的系统安装!
1、安装python

2、安装pytorch
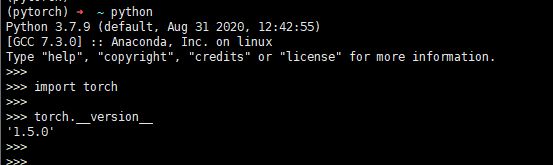
执行以下命令验证是否已经安装pytorch:
pythonimport torch
torch.__version__
3、安装CUDA,下载+安装
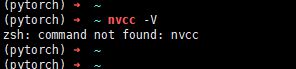
查看是否已经安装:
nvcc -V
没有安装的话,需要根据显卡安装对应版本,
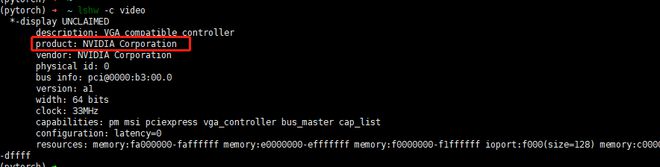
查看显卡型号:
lshw -c video
或者按上面说的:
lspci | grep -i nvidia
或者
lspci | grep -i vga

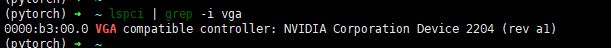
有的说可以用
nvidia-smi
命令,但我的不行0.0(后面就可以了。。往后面看)
根据2204,和上面的网址 https://blog.csdn.net/maizousidemao/article/details/88821949,查找对应的型号:
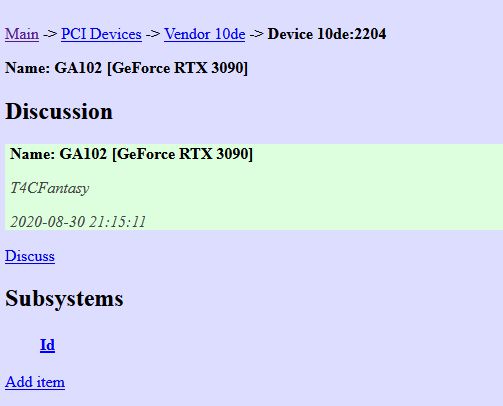
显卡型号知道了,接下来是驱动。
先验证是否已经安装了驱动:
首先得安装 mesa-utils,在终端输入命令:
sudo apt-get install mesa-utils然后再运行命令:
glxinfo | grep rendering
如果结果是“yes”,证明显卡 驱动已经成功安装
如果没有安装就要自己下载安装了:
1.可以去网站找对应的驱动并下载 https://www.nvidia.cn/Download/index.aspx?lang=cn#
填入自己电脑的型号

点击搜索,查到需要下载的驱动版本。
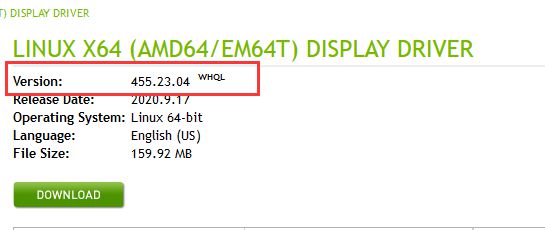
对应的版本是455,
还可以通过
ubuntu-drivers devices
可以看到可以使用的驱动版本号,

也是455
所以就安装455的驱动。
首先禁用ubuntu默认安装好的一个驱动:nouveau
先验证是否已经禁用:
lsmod | grep nouveau

无输出,表示禁用成功。。。(有点懵??啥时候禁用的?)
没有禁用的一定要禁用,貌似坑很多!!
接下来安装驱动:
网上有三种方法: 地址 https://zhuanlan.zhihu.com/p/59618999
1、
sudo ubuntu-drivers autoinstall 会直接安装上面查到的455的驱动
如果想安装其他版本,如 340 版本,sudo apt install nvidia-340 就自动安装了。
安装完成后重启系统即可
2、使用PPA第三方软件仓库安装最新版本
添加 PPA 软件仓库:
sudo add-apt-repository ppa:graphics-drivers/ppa
,需要输入用户密码,按照提示还需要按下 Enter 键。
更新软件索引:
sudo apt update
接下来的步骤同方法一,只是这样我们就可以选择安装最新版本的驱动程序了。
3、手动下载
按照上面说的方法下载,
接着需要先安装一些 NVIDIA 显卡依赖的软件,在终端依次执行如下命令:
sudo dpkg --add-architecture i386sudo apt update
sudo apt install build
-essential libc6:i386我选择的第一种,,跑一段时间后,停止如下图
重启检查是否安装完成:
reboot
执行下图
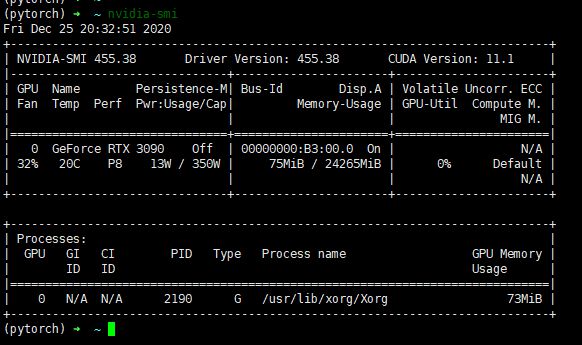
表示自动安装成功。
现在显卡驱动安装成功后,安装对应版本的CUDA
安装CUDA:
准备工作:
1、先检查gcc是否安装: gcc -v
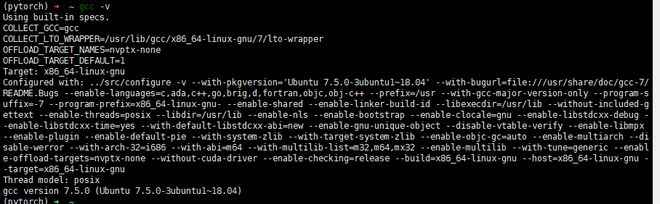
2、安装kernel header和 package development:
sudo apt-get install linux-headers-$(uname -r) 
3、因为我的显卡驱动是455,对应上面的表,需要安装11版本以上的CUDA
去官网选择自己的环境之后,记住选择 runfile(local) 版本。
https://developer.nvidia.com/zh-cn/cuda-downloads?
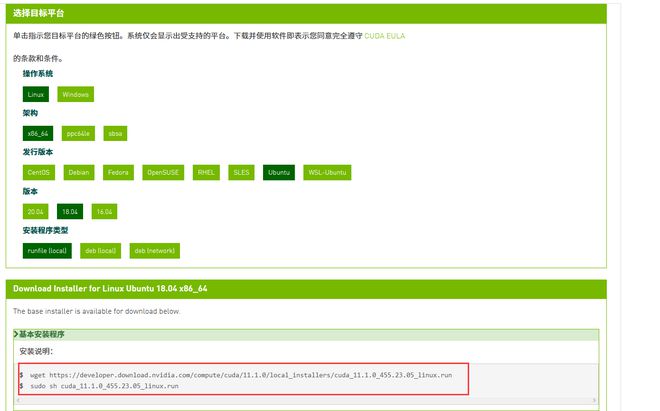
根据下方的安装说明,执行。
第一个是下载,网上说下的很慢,然后我去找到了一个交大云盘下载的,但是版本是10+,跟硬件不匹配,所以,我还是按照了安装说明下载,发现速度很快,五分钟就下载完了3G 大小的文件。。
执行 wget 命令时,出现了一个小问题,

解决办法:查看环境变量
export -p
最后三行是

因为地址是https 的,所以只需要重置最后一个代理地址:
执行
unset https_proxy
再查看环境变量,三行变两行了。
然后就能下载了。
下载完毕,执行安装说明的第二个命令,中间需要选择几个选项,
依次选择 continue----- accept --------取消Driver【X】前面的X (因为已经安装了驱动了,不取消会报错),然后选择install。
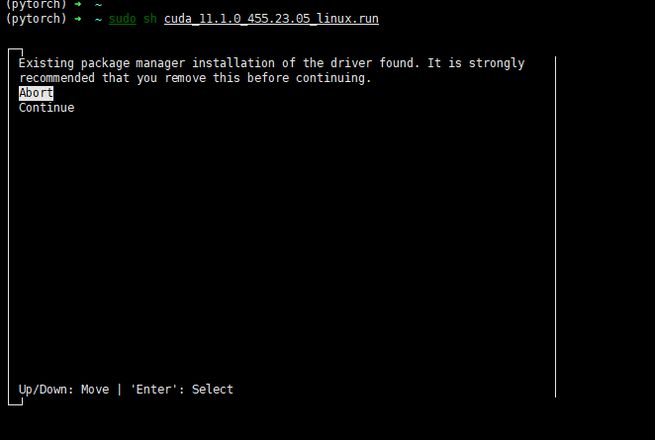
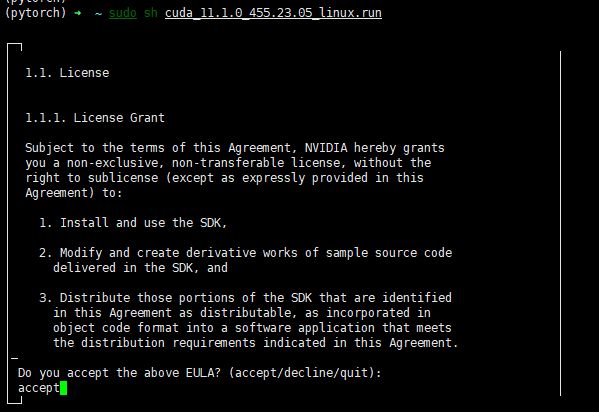
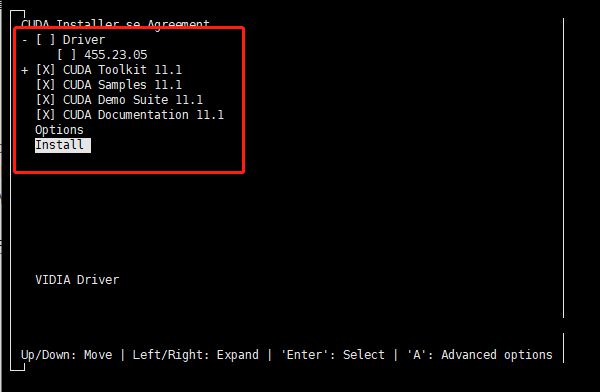
执行成功界面如下:
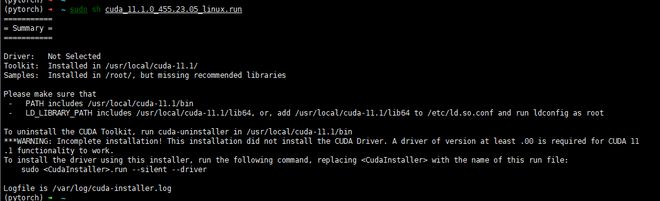
验证CUDA是否安装成功:
cd /usr/local/cuda-11.1/samples/1_Utilities/deviceQuerysudo make
.
/deviceQuery
最后结果是

表示安装成功!
五、添加环境变量:
#添加路径到PATH变量export PATH
=/usr/local/cuda-11.1/bin:/usr/local/cuda-11.1/nsight-compute-2020.2.0${PATH:+:${PATH}}#使用runfile安装时,64位系统上的LD_LIBRARY_PATH变量需要包含:
export LD_LIBRARY_PATH
=/usr/local/cuda-11.1/lib64${LD_LIBRARY_PATH:+:${LD_LIBRARY_PATH}}#保存环境变量
source
/etc/profile
此时执行 env ,可以看到PATH里出现CUDA的路径。
还需要reboot,否则环境变量不能永久生效。
有的系统不是bash,参考这个: http://www.linuxboy.net/linuxjc/126570.html按下面的来
echo "export PATH=/usr/local/cuda-11.1/bin/:$PATH">>~/.zshrcecho
"export LD_LIBRARY_PATH=/usr/local/cuda-11.1/lib64:$LD_LIBRARY_PATH">>~/.zshrcsource
~/.zshrc
验证CUDA能正确并支持与CUDA硬件通信:
1、 确认驱动程序的版本。
cat /proc/driver/nvidia/version

2、进入 /usr/local/cuda-11.1/samples目录
进行汇编测试:make -k
3、编译完毕,进入samples目录,出现了bin目录,运行二进制文件
cd /usr/local/cuda-11.1/samples/bin/x86_64/linux/release.
/deviceQuery
最后一行出现pass,说明CUDA软件安装和配置正确。
(如图,第一行显示检测到设备,第二行显示设备型号,最后一行显示测试通过。)
六、测试GPU加速效果
利用YOLOv3实现第一个视频物体检测
1、编译时,Makefile中GPU=0,OPENCV=1,则不采用GPU加速;
2、编译时,Makefile中GPU=1,OPENCV=1,则有加速。
参考:https://www.it610.com/article/1294417307388420096.htm
七、检测软件是否安装齐全
根据项目的规定,检测软件是否安装:
- Python 3.6+ 3.7.9 (python3)
- PyTorch 1.3+ 1.5.0 (在python下执行 import torch 和 torch.__version__ ) print(torch.version.cuda) 打印当前torch对应的cuda版本
- CUDA 9.2+ (If you build PyTorch from source, CUDA 9.0 is also compatible) 11.1 (环境变量配好,nvcc -V)
- GCC 5+ 7.5.0 (gcc -v)
- MMCV
import mmcv 报错,网上查了查 ,
是cuda和torch 版本冲突
于是 pip list 看一下
现在,cuda是11.1 torch是1.5.0 mmcv-full是1.2.3 pip是20.3.3
卸载原mmcv-full
pip uninstall mmcv-full
再安装新的
pip install mmcv-full -f https://download.openmmlab.com/mmcv/dist/cu111/torch2.7.0/index.html
mmcv -full 从1.2.3 变成了 1.2.2版本了
torch还是1.5.0没有变成1.7.0??
先卸载原来的:
pip uninstall torch
根据自己的CUDA版本自动安装对应的torch版本:
pip install torch torchvision

下载完毕,
现在,cuda是11.1 torch是1.7.1 mmcv-full是1.2.2 pip是20.3.3 gcc是7.5.0
然后在python交互界面运行,
执行以下代码验证是否安装成功,可以参考 https://github.com/open-mmlab/mmdetection/blob/master/docs/get_started.md 最下面的 Verification 部分:
from mmdet.apis import init_detector, inference_detectorconfig_file
= "configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py"device
= "cuda:0"# init a detector
model
= init_detector(config_file, device=device)# inference the demo image
inference_detector(model,
"demo/demo.jpg")
如果报错ModuleNotFoundError, 可以在mmdetection目录下,运行下面代码升级库:
python setup.py install
执行完毕,会在mmdetection目录下生产build目录。
如果还不行,就再执行下
python setup.py develop
然后就可以运行成功了!

我这个不是图形化界面,需要图形化显示需要pycharm 或者 tensorboard 。
----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
第二部分,第一部分用root安装的,普通用户没法用root文件夹里的东西。。。。。。。由于某些原因,切换了用户,重新安装。。。。。。。。。。。又累个半死!
1、重新换用户
新增用户
2、检查软件
上面第一部分,cuda是11.1 torch是1.7.1 mmcv-full是1.2.2 pip是20.3.3 gcc是7.5.0
现在,cuda是11.1 torch是1.7.1 torchvision是0.8.2 mmcv-full未安装 pip是20.3.3 gcc是8.3.0
切换到pytorch环境: (此处请自行百度conda 环境管理)
conda activate pytorch
用pytorch环境,
cuda=11.1 torch=1.7.1 mmcv-full =1.2.2 pip=20.3.3 gcc=7.3.0
执行程序还是报错,
猜想权限的问题? 或者重新安装mmde项目?
执行
pip install -v -e .
报错,忘记换环境了!! 解决办法,在正确的环境下,执行
python setup.py develop
然后执行就成功了,也能看到成功安装了mmdet
重装mmcv-full :
pip uninstall mmcv-fullpip install mmcv
-full==1.2.4 -f https://download.openmmlab.com/mmcv/dist/cu111/torch2.7.0/index.html
版本换成1.2.4,解决问题了
3、安装完毕后,还用 https://github.com/open-mmlab/mmdetection/blob/master/docs/get_started.md 最下面的检测代码:
from mmdet.apis import init_detector, inference_detectorconfig_file
= "configs/faster_rcnn/faster_rcnn_r50_fpn_1x_coco.py"device
= "cuda:0"# init a detector
model
= init_detector(config_file, device=device)# inference the demo image
inference_detector(model,
"demo/demo.jpg")
验证是否成功。
报错: RuntimeError: CUDA error: no kernel image is available for execution on the device
原因: cuda和torch版本不匹配。
办法:
pip uninstall torchpip install torch
==1.7.1+cu110 torchvision==0.8.2+cu110 torchaudio===0.7.2 -f https://download.pytorch.org/whl/torch_stable.html

再执行代码:如图

就不报错了。
结束。
有问题可以留言噢~~~
------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
记录一些语句
1、查看python安装目录:
pythonimport sys
sys.path
2、查看conda的信息
conda info --env
3、检测CUDA是否安装正确并能被Pytorch检测到 && 看Pytorch能不能调用cuda加速
https://www.cnblogs.com/liuke-note/p/10149530.html
以上是 Github上目标检测项目:mmdetection项目初接触,安装学习过程记录。 的全部内容, 来源链接: utcz.com/z/537649.html