分布式开源协调服务——Zookeeper

目录
- 一、ZooKeeper概述
- 二、ZooKeeper数据模型
- 1)ZooKeeper数据模型Znode
- 1、引用方式
- 2、Znode结构
- 3、节点类型
- 4、观察
- 2)ZooKeeper中的时间
- 1、Zxid
- 2、版本号
- 3)ZooKeeper节点属性
- 1)ZooKeeper数据模型Znode
- 三、ZooKeeper架构
- 四、ZooKeeper中Observer【ZooKeeper伸缩性】
- 五、ZooKeeper原理
- 1)恢复模式
- 2)广播模式
- 六、Zookeeper安装
- 1)独立集群安装
- 1、下载
- 2、配置环境变量
- 3、配置
- 4、配置myid
- 5、将配置推送到其它节点
- 6、启动服务
- 2)与Kafka集成安装
- 1、下载kafka
- 2、配置环境变量
- 3、修改zookeeper配置
- 4、启动服务
- 1)独立集群安装
- 七、常用操作命令
- 1)创建节点
- 2)查看节点
- 3)更新节点
- 4)删除节点
一、ZooKeeper概述
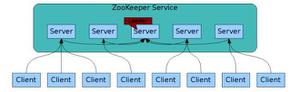
Apache ZooKeeper 是一个集中式服务,用于维护配置信息、命名、提供分布式同步和提供组服务,ZooKeeper 致力于开发和维护一个开源服务器,以实现高度可靠的分布式协调,其实也可以认为就是一个分布式数据库,只是结构比较特殊,是树状结构。官网文档:https://zookeeper.apache.org/doc/r3.8.0/
特点:
- 顺序一致性 :来自客户端的更新将按照它们发送的顺序应用。
- 原子性 :更新成功或失败。没有部分结果。
- 单一系统映像 :客户端将看到相同的服务视图,而不管它连接到的服务器如何。即,即使客户端故障转移到具有相同会话的不同服务器,客户端也永远不会看到系统的旧视图。
- 可靠性:应用更新后,它将从那时起持续存在,直到客户端覆盖更新。
- 及时性:系统的客户视图保证在一定的时间范围内是最新的。
二、ZooKeeper数据模型
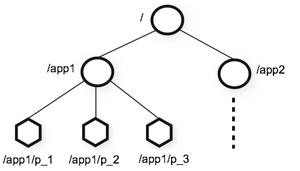
从上图中我们可以看出ZooKeeper的数据模型,在结构上和标准文件系统的非常相似,都是采用这种树形层次结构,ZooKeeper树中的每个节点被称为—Znode。和文件系统的目录树一样,ZooKeeper树中的每个节点可以拥有子节点。但也有不同之处:
1)ZooKeeper数据模型Znode
ZooKeeper拥有一个层次的命名空间,这个和标准的文件系统非常相似。
1、引用方式
Zonde通过路径引用,如同Unix中的文件路径。路径必须是绝对的,因此他们必须由斜杠字符来开头。除此以外,他们必须是唯一的,也就是说每一个路径只有一个表示,因此这些路径不能改变。在ZooKeeper中,路径由Unicode字符串组成,并且有一些限制。字符串"/zookeeper"用以保存管理信息,比如关键配额信息。
2、Znode结构
ZooKeeper命名空间中的Znode,兼具文件和目录两种特点。既像文件一样维护着数据、元信息、ACL、时间戳等数据结构,又像目录一样可以作为路径标识的一部分。图中的每个节点称为一个Znode。 每个Znode由3部分组成:
- stat:此为状态信息, 描述该Znode的版本, 权限等信息
- data:与该Znode关联的数据
- children:该Znode下的子节点
【温馨提示】ZooKeeper虽然可以关联一些数据,但并没有被设计为常规的数据库或者大数据存储,相反的是,它用来管理调度数据,比如分布式应用中的配置文件信息、状态信息、汇集位置等等。这些数据的共同特性就是它们都是很小的数据,通常以KB为大小单位。ZooKeeper的服务器和客户端都被设计为严格检查并限制每个Znode的数据大小至多
1M,但常规使用中应该远小于此值。
3、节点类型
ZooKeeper中的节点有两种,分别为临时节点和永久节点。节点的类型在创建时即被确定,并且不能改变。
- 临时节点:该节点的生命周期依赖于创建它们的会话。一旦会话(Session)结束,临时节点将被自动删除,当然可以也可以手动删除。虽然每个临时的Znode都会绑定到一个客户端会话,但他们对所有的客户端还是可见的。另外,ZooKeeper的临时节点不允许拥有子节点。
- 永久节点:该节点的生命周期不依赖于会话,并且只有在客户端显示执行删除操作的时候,他们才能被删除。
4、观察
客户端可以在节点上设置
watch,我们称之为监视器。当节点状态发生改变时(Znode的增、删、改)将会触发watch所对应的操作。当watch被触发时,ZooKeeper将会向客户端发送且仅发送一条通知,因为watch只能被触发一次,这样可以减少网络流量。
2)ZooKeeper中的时间
ZooKeeper有多种记录时间的形式,其中包含以下几个主要属性:
1、Zxid
致使ZooKeeper节点状态改变的每一个操作都将使节点接收到一个Zxid格式的时间戳,并且这个时间戳全局有序。也就是说,也就是说,每个对节点的改变都将产生一个唯一的Zxid。如果Zxid1的值小于Zxid2的值,那么Zxid1所对应的事件发生在Zxid2所对应的事件之前。实际上,ZooKeeper的每个节点维护者三个Zxid值,为别为:cZxid、mZxid、pZxid。
cZxid: 是节点的创建时间所对应的Zxid格式时间戳。mZxid:是节点的修改时间所对应的Zxid格式时间戳。
实现中Zxid是一个64为的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个 新的epoch。低32位是个递增计数。
2、版本号
对节点的每一个操作都将致使这个节点的版本号增加。每个节点维护着三个版本号,他们分别为:
version:节点数据版本号cversion:子节点版本号aversion:节点所拥有的ACL版本号
3)ZooKeeper节点属性
通过前面的介绍,我们可以了解到,一个节点自身拥有表示其状态的许多重要属性,如下图所示:
三、ZooKeeper架构
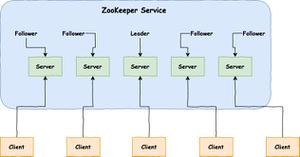
- Leader:负责进行投票的发起和决议,更新系统状态,Leader 是由选举产生;
- Follower: 用于接受客户端请求并向客户端返回结果,在选主过程中参与投票;
- Observer:可以接受客户端连接,接受读写请求,写请求转发给 Leader,但 Observer 不参加投票过程,只同步 Leader 的状态,Observer 的目的是为了扩展系统,提高读取速度。
四、ZooKeeper中Observer【ZooKeeper伸缩性】
- 在Observer出现以前,ZooKeeper的伸缩性由Follower来实现,我们可以通过添加Follower节点的数量来保证ZooKeeper服务的读性能。
- 但是随着Follower节点数量的增加,ZooKeeper服务的写性能受到了影响;Zab协议对写请求的处理过程中我们可以发现,增加服务器的数量,则增加了对协议中投票过程的压力,随着 ZooKeeper 集群变大,写操作的吞吐量会下降;
- 所以,我们不得不,在增加Client数量的期望和我们希望保持较好吞吐性能的期望间进行权衡,要打破这一耦合关系,我们引入了不参与投票的服务器,称为 Observer。
- Observer可以接受客户端的连接,并将写请求转发给Leader节点。但是,Leader节点不会要求 Observer参加投票。
- 相反,Observer不参与投票过程,但是和其他服务节点一样得到投票结果。
从上图显示了一个简单评测的结果。纵轴是,单一客户端能够发出的每秒钟同步写操作的数量。横轴是 ZooKeeper 集群的尺寸。蓝色的是每个服务器都是投票Server的情况,而绿色的则只有三个是投票Server,其它都是 Observer。从图中我们可以看出,我们在扩充 Observer时写性能几乎可以保持不便。但是,如果扩展投票Server的数量,写性能会明显下降,显然 Observers 是有效的。
五、ZooKeeper原理
Zookeeper的核心是原子广播机制,这个机制保证了各个server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式和广播模式。
1)恢复模式
当服务启动或者在领导者崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和server具有相同的系统状态。
2)广播模式
一旦Leader已经和多数的Follower进行了状态同步后,他就可以开始广播消息了,即进入广播状态。这时候当一个Server加入ZooKeeper服务中,它会在恢复模式下启动,发现Leader,并和Leader进行状态同步。待到同步结束,它也参与消息广播。ZooKeeper服务一直维持在Broadcast状态,直到Leader崩溃了或者Leader失去了大部分的Followers支持。
Broadcast模式极其类似于分布式事务中的2pc(two-phrase commit 两阶段提交):即Leader提起一个决议,由Followers进行投票,Leader对投票结果进行计算决定是否通过该决议,如果通过执行该决议(事务),否则什么也不做。
在广播模式ZooKeeper Server会接受Client请求,所有的写请求都被转发给leader,再由领导者将更新广播给跟随者,而查询和维护管理命令不用跟leader打交道。当半数以上的跟随者已经将修改持久化之后,领导者才会提交这个更新,然后客户端才会收到一个更新成功的响应。这个用来达成共识的协议被设计成具有原子性,因此每个修改要么成功要么失败。
zookeeper安装">六、Zookeeper安装
1)独立集群安装
1、下载
$ cd /opt/bigdata/hadoop/software$ wget https://dlcdn.apache.org/zookeeper/zookeeper-3.8.0/apache-zookeeper-3.8.0-bin.tar.gz
$ tar -xf apache-zookeeper-3.8.0-bin.tar.gz -C /opt/bigdata/hadoop/server/
2、配置环境变量
$ vi /etc/profileexport ZOOKEEPER_HOME=/opt/bigdata/hadoop/server/apache-zookeeper-3.8.0-bin/
export PATH=$ZOOKEEPER_HOME/bin:$PATH
$ source /etc/profile
3、配置
$ cd $ZOOKEEPER_HOME$ cp conf/zoo_sample.cfg conf/zoo.cfg
$ mkdir $ZOOKEEPER_HOME/data
$ cat >conf/zoo.cfg<<EOF
# tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。session最小有效时间为tickTime*2
tickTime=2000
# Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。不要使用/tmp目录
dataDir=/opt/bigdata/hadoop/server/apache-zookeeper-3.8.0-bin/data
# 端口,默认就是2181
clientPort=2181
# 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量),超过此数量没有回复会断开链接
initLimit=10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
# 最大客户端链接数量,0不限制,默认是0
maxClientCnxns=60
# zookeeper集群配置项,server.1,server.2,server.3是zk集群节点;hadoop-node1,hadoop-node2,hadoop-node3是主机名称;2888是主从通信端口;3888用来选举leader
server.1=hadoop-node1:2888:3888
server.2=hadoop-node2:2888:3888
server.3=hadoop-node3:2888:3888
EOF
4、配置myid
$ echo 1 > $ZOOKEEPER_HOME/data/myid5、将配置推送到其它节点
$ scp -r $ZOOKEEPER_HOME hadoop-node2:/opt/bigdata/hadoop/server/$ scp -r $ZOOKEEPER_HOME hadoop-node3:/opt/bigdata/hadoop/server/
# 也需要添加环境变量和修改myid,hadoop-node2的myid设置2,hadoop-node3的myid设置3
6、启动服务
$ cd $ZOOKEEPER_HOME# 启动
$ ./bin/zkServer.sh start
# 查看状态
$ ./bin/zkServer.sh status
从上图很容易就看出那个是leader和follower,到这里部署就ok了。
2)与Kafka集成安装
kafka官网文档:https://kafka.apache.org/documentation/
1、下载kafka
$ cd /opt/bigdata/hadoop/software$ wget https://dlcdn.apache.org/kafka/3.1.1/kafka_2.13-3.1.1.tgz
$ tar -xf kafka_2.13-3.1.1.tgz -C /opt/bigdata/hadoop/server/
2、配置环境变量
这里配置kafka的环境变量,毕竟是kafka里自带的zookeeper
$ vi /etc/profileexport KAFKA_HOME=/opt/bigdata/hadoop/server/kafka_2.13-3.1.1
export PATH=$PATH:$KAFKA_HOME/bin
$ source /etc/profile
3、修改zookeeper配置
配置跟上面一样,这里我换个端口12181
$ cd $KAFKA_HOME$ cat >./config/zookeeper.properties<<EOF
# tickTime:Zookeeper 服务器之间或客户端与服务器之间维持心跳的时间间隔,也就是每个 tickTime 时间就会发送一个心跳。tickTime以毫秒为单位。session最小有效时间为tickTime*2
tickTime=2000
# Zookeeper保存数据的目录,默认情况下,Zookeeper将写数据的日志文件也保存在这个目录里。不要使用/tmp目录
dataDir=/opt/bigdata/hadoop/server/apache-zookeeper-3.8.0-bin/data
# 端口,默认2181
clientPort=12181
# 集群中的follower服务器(F)与leader服务器(L)之间初始连接时能容忍的最多心跳数(tickTime的数量),超过此数量没有回复会断开链接
initLimit=10
# 集群中的follower服务器与leader服务器之间请求和应答之间能容忍的最多心跳数(tickTime的数量)
syncLimit=5
# 最大客户端链接数量,0不限制,默认是0
maxClientCnxns=60
# zookeeper集群配置项,server.1,server.2,server.3是zk集群节点;hadoop-node1,hadoop-node2,hadoop-node3是主机名称;2888是主从通信端口;3888用来选举leader
server.1=hadoop-node1:2888:3888
server.2=hadoop-node2:2888:3888
server.3=hadoop-node3:2888:3888
EOF
4、启动服务
$ ./bin/zookeeper-server-start.sh -daemon ./config/zookeeper.properties好像kafka自带的zookeeper没办法查zookeeper的集群状态,所以不建议使用kafka内置的zookeeper,如果有小伙伴知道怎么查kafka里自带zookeeper的集群状态,欢迎给我留言哦~
七、常用操作命令
# kafka自带的zookeeper客户端启动如下:$ cd $KAFKA_HOME
$ ./bin/zookeeper-shell.sh hadoop-node1:12181
# 独立zookeeper客户端启动如下:
$ cd $ZOOKEEPER_HOME
$ zkCli.sh -server hadoop-node1:2181
# 查看帮助
help
1)创建节点
虽然上面只说了两种节点类型,其实严格来讲有四种节点类型:
持久节点持久顺序节点
临时节点
临时顺序节点
接下来分别创建这四种类型的节点
# 【持久节点】数据节点创建后,一直存在,直到有删除操作主动清除,示例如下:create /zk-node data
# 【持久顺序节点】节点一直存在,zk自动追加数字后缀做节点名,后缀上限 MAX(int),示例如下:
create -s /zk-node data
# 【临时节点】生命周期和会话相同,客户端会话失效,则临时节点被清除,示例如下:
create -e /zk-node-temp data
# 【临时顺序节点】临时节点+顺序节点后缀,示例如下:
create -s -e /zk-node-temp data
2)查看节点
# 列出zk执行节点的所有子节点,只能看到第一级子节点ls /
# 获取zk指定节点数据内容和属性
get /zk-node
3)更新节点
# 表达式:set ${path} ${data} [version]set /zk-node hello
get /zk-node
4)删除节点
# 对于包含子节点的节点,该命令无法成功删除,使用deleteall /zk-nodedelete /zk-node
Zookeeper架构、环境部署和基础操作就到这里了,后续会有更多相关内容的文章,请小伙伴耐心等待,有疑问的欢迎给我留言哦~
以上是 分布式开源协调服务——Zookeeper 的全部内容, 来源链接: utcz.com/z/536572.html