Redis设计与实现2.1:主从复制

主从复制
这是《Redis设计与实现》系列的文章,系列导航:Redis设计与实现笔记
SLAVEOF
新旧复制功能
旧版复制功能
旧版复制功能的实现为 同步 和 命令传播:
当刚连上Master时,要做一次全同步:
sequenceDiagram
participant Slave
participant Master
Slave->>Master: SYNC
Master->>Master: BGSAVE
Master->>Master: 记录此时的命令到缓冲区中
Master->>Slave: 发送RDB
Master->>Slave: 发送命令缓冲区中的命令
之所以要用到缓冲区是因为,在主节点进行 BGSAVE 的过程中如果有命令执行,那么我们要把这些命令也记录下来。
之后,主从节点之间只用 命令传播 就可以做到同步了,也就是说主节点执行什么命令,从节点跟着执行。(当然,一些随机、时间类的函数会直接转换成定值)
旧版复制的缺陷
如果从节点断线后重新连接,旧版复制功能的效率很低,因为为了让从服务器补足一小部分的确实却要进行一次 SYNC 命令。
为什么低效:
- 主节点 BGSAVE 要消耗大量的CPU、内存、IO资源
- 主节点发送需要消耗网络资源
- 从节点需要载入,且载入期间处于阻塞状态
新版复制功能
用 PSYNC 命令代替 SYNC。
PSYNC 具有 完整重同步 和 部分重同步 两种模式,分别针对初次同步和重新同步两种场景。
复制功能的实现
复制的实现
复制的一些具体的细节,当进行复制时:
从服务器设置主服务器的地址和端口
struct redisServer{//...
char *masterhost;
int masterport;
//...
}
建立套接字连接,并关联一个专门处理复制工作的文件事件处理器
发送 PING 命令,检查套接字和主服务器的状态是否正常
身份验证,主从必须配置一致且密码正确(如果有)才能通过验证
发送端口信息:主节点也得知道给从节点的哪个端口发消息,不是么
同步:干正事儿喽
这里书上说:
- 在同步操作执行之前,只有从服务器是主服务器的客户端,但是在执行同步操作之后,主服务器也会成为从服务器的客户端。
- 正是因为主服务成为了从服务器的客户端,所以主服务器才能通过发送写命令来改变从服务器的数据库状态。
我想了想,似乎一般确实都是客户端改变服务端的数据的,所以这么说倒也在理,但是服务端不是也可以给客户端发送数据么?所以这里可能和 Redis 的具体实现有关?
命令传播:进入了第二个阶段
如何部分重同步
要关注的三个部分:
复制偏移量:主从服务器都有复制偏移量,通过这个值判断主从是否处于一致状态
主服务器的复制积压缓冲区:保存执行命令的历史记录
一个固定长度(默认1MB)的 FIFO 的队列,当主从不一致时可以计算并从中获取缺少的命令。
由于固定长度,所以如果缺的多了就只能进行完整重同步了。
大小一般设为 断连平均时间 * 每秒的命令数,安全起见再乘以2。
服务器的运行 ID
毕竟只有 ID 一致同步才有意义,否则说明换主人了,那还是全同步吧
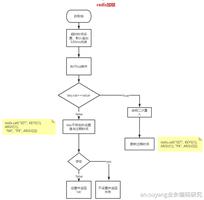
PSYNC的逻辑
graph LR;
S(接收到SLAVEOF命令) --> A{第一次复制?}
A --Y--> A1[发送PSYNC ? -1] --> E1(返回+FULLRESYNC <runid> <offset>)
A --N--> A2[发送PSYNC <runid> <offset>] --> B{主服务器返回 +CONTINUE}
B --N--> E1
B --Y--> E2[执行部分重同步]
主要是判断 是否是第一次复制 、 是否是同一个主服务器,从而决定是部分重同步还是全同步。
上图没有展示的是,如果主服务器不支持 PSYNC,则返回 -ERR
心跳检测
心跳检测:在命令传播阶段,从服务器默认每秒发送一次心跳:REPLCONF ACK <replication_offset>。
作用有三:
检测主从服务器的网络状态
辅助实现 min-slaves 配置选项
min-slaves-to-write、min-slaves-max-lag 可以防止发生脑裂现象
通过 offset 检测命令是否丢失
以上是 Redis设计与实现2.1:主从复制 的全部内容, 来源链接: utcz.com/z/536456.html