删库到跑路?还得看这篇Redis数据库持久化与企业容灾备份恢复实战指南

本章目录
0x00 数据持久化
- 1.RDB 方式
- 2.AOF 方式
- 如何抉择 RDB OR AOF?
0x01 备份容灾
一、备份
- 1.手动备份redis数据库" title="redis数据库">redis数据库
- 2.迁移Redis指定db-数据库
- 3.Redis集群数据备份与迁移
二、恢复
- 1.系统Redis用户被删除后配置数据恢复流程
- 2.Kubernetes中单实例异常数据迁移恢复实践
- 3.当Redis集群中出现从节点slave,fail,noaddr问题进行处理恢复流程。
前置知识学习补充
Redis数据库基础入门介绍与安装 - https://blog.weiyigeek.top/2019/4-17-49.html
Redis数据库基础数据类型介绍与使用 - https://blog.weiyigeek.top/2020/5-17-50.html
Redis基础运维之原理介绍和主从配置 - https://blog.weiyigeek.top/2019/4-17-97.html
Redis基础运维之哨兵和集群安装配置 - https://blog.weiyigeek.top/2019/4-17-576.html
Redis基础运维之在K8S中的安装与配置 - https://blog.weiyigeek.top/2019/4-17-524.html
Redis数据库性能测试及优化配置 - https://blog.weiyigeek.top/2019/4-17-527.html
Redis数据库客户端操作实践及入坑出坑 - https://blog.weiyigeek.top/2019/4-17-577.html
0x00 数据持久化
描述: Redis 是将数据存储在内存之中所以其读写效率非常高,但是往往事物都不是那么美好,当由于某些不可抗力导致机器宕机、redis服务停止此时您在内存中的数据将完全丢失;
所以为了使 Redis 在异常重启后仍能保证数据不丢失, 我们就需要对其进行设置持久化存储,使其将内存的数据通过某种方式存入磁盘中,当Redis服务端重启后便会从该磁盘中进行读取数据进而恢复Redis中的数据, 所以Redis数据持久化是容灾恢复必备条件;
Redis支持两种持久化方式:
- (1) RDB 持久化(默认支持): 该机制是指在指定的时间间隔内将内存中数据集写入到磁盘;
- (2) AOF 持久化: 该机制将以日志的形式记录服务器所处理的每一个写操作,同时在Redis服务器启动之初会读取该文件来重新构建数据库,以保证启动后数据库中的数据完整;
- (3) 无持久化: 将 Redis 作为一个临时缓存,并将数据存放到
memcached之中;
Tips: 为保证数据安全性,我们可以设置 Redis 同时使用RDB和AOF持久化方式,来保证重启后Redis服务器中的数据完整;
1.RDB 方式
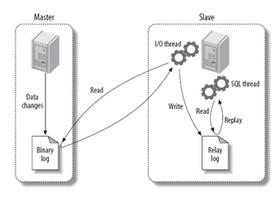
描述: Redis 将某一时刻的快照(备份的数据库数据)保存成一种称为RDB格式的文件中,这种格式是经过压缩的二进制文件,数据库的保存和恢复文件如下图所示。
保存RDB数据的两种方式:
- 1、save命令:save命令会阻塞redis服务器的进程,直到RDB文件创建完,在该期间redis不能处理任何的命令请求,这就是save命令最大的缺陷。
- 2、bgsave命令:与save命令不同的是 bgsave在生成RDB文件时,会派生出一个子进程,子进程负责创建RDB文件,在此期间,主进程和子进程是同时存在的,因此不会阻塞redis服务器进程。 (推荐方式)
说明:可用lastsave命令查看生成RDB文件是否成功
优势
- 采用子线程创建RDB文件(
dump.rdb),不会对redis服务器性能造成大的影响( 性能最大化);
- 采用子线程创建RDB文件(
- 快照生成的RDB文件是一种压缩的二进制文件,可以方便的在网络中传输和保存。通过RDB文件可以方便的将redis数据恢复到某一历史时刻,可以提高数据安全性,避免宕机等意外对数据的影响。
- 适合大规模的数据恢复, RDB的启动恢复效率高。
- 如果业务对数据完整性和一致性要求不高,RDB是很好的选择。
劣势
- 在redis文件在时间点A生成,之后产生了新数据,还未到达另一次生成RDB文件的条件,redis服务器崩溃了,那么在时间点A之后的数据会丢失掉,数据一致性不是完美的好, 如果可以接受这部分丢失的数据,可以用生成RDB的方式;
- 快照持久化方法通过调用fork()方法创建子线程。当redis内存的数据量比较大时,创建子线程和生成RDB文件会占用大量的系统资源和处理时间,对 redis处理正常的客户端请求造成较大影响。
- 数据的完整性和一致性不高,因为RDB可能在最后一次备份时宕机了。
- 备份时占用内存,因为Redis 在备份时会独立创建一个子进程,将数据写入到一个临时文件(此时内存中的数据是原来的两倍哦),最后再将临时文件替换之前的备份文件。所以 Redis 的持久化和数据的恢复要选择在夜深人静的时候执行是比较合理的。
Q: 通过RDB文件恢复数据?
答: 将dump.rdb 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可。在实际开发中,一般会考虑到物理机硬盘损坏情况,选择备份dump.rdb 。
配置说明:
# Redis 配置文件cat > redis.conf <<"EOF"
# 密码认证
requirepass WeiyiGeek.top
# 持久化文件保存路径目录
dir /data
# RDB核心规则之触发保存条件
说明:save <指定时间间隔> <执行指定次数更新操作>,满足条件就将内存中的数据同步到硬盘中。官方出厂配置默认是 900秒内有1个更改,300秒内有10个更改以及60秒内有10000个更改, 则将内存中的数据快照写入磁盘。
save 900 1 # 900秒(15分钟)至少有1条key变化,其他同理
save 300 10
save 60 10000 #每60描述至少有1000个key发生变化时候则dump内存快照
# RDB 生成的文件名称
dbfilename dump.rdb
# 是否压缩(ZF压缩方式),会占用部分cpu资源,默认yes(建议开启)
rdbcompression yes
# rdb 文件校验
rdbchecksum yes
# 备份进程出错时,主进程停止接受写入操作,默认yes
stop-writes-on-bgsave-error yes
# RDB自动触发策略是否启用,默认为yes
rdb-save-incremental-fsync yes
EOF
实际案例:
# 1.如上面配置所示,按配置情况触发# 比如在Redis服务终止的时候执行
# 2.手动保存数据连接redis后使用命令save、bgsave触发
127.0.0.1:6379> SAVE #save 会阻塞redis服务器直到完成持久化
OK
127.0.0.1:6379> BGSAVE #bgsave 不会阻塞redis服务器(它会fork一个子进程,由子进程进行持久化。)
OK
127.0.0.1:6379> quit
# 3.redis aof 持久化文件完整性检查与异常修正
/usr/local/redis/bin/redis-check-aof --fix appendonly.aof
# The AOF appears to start with an RDB preamble.
# Checking the RDB preamble to start:
# [offset 0] Checking RDB file --fix
# [offset 27] AUX FIELD redis-ver = "5.0.10"
# [offset 41] AUX FIELD redis-bits = "64"
# [offset 53] AUX FIELD ctime = "1631088747"
# [offset 68] AUX FIELD used-mem = "31554944"
# [offset 84] AUX FIELD aof-preamble = "1"
# [offset 86] Selecting DB ID 0
# [offset 13350761] Checksum OK
# [offset 13350761] o/ RDB looks OK! o/
# [info] 157070 keys read
# [info] 0 expires
# [info] 0 already expired
# RDB preamble is OK, proceeding with AOF tail...
# 0x 27b66b0: Expected prefix "*", got: "R"
# AOF analyzed: size=116993914, ok_up_to=41641648, ok_up_to_line=1816854, diff=75352266
# This will shrink the AOF from 116993914 bytes, with 75352266 bytes, to 41641648 bytes
# Continue? [y/N]: y
# Successfully truncated AOF
# 4.再利用rdb数据文件进行恢复数据
root@dfbf8c0c0625:/data# ls
dump.rdb
# 将容器中的dump.rdb拷贝一份到宿主机中的`/var/lib/redis/`中,并需要在redis.conf中配置 `dir "/var/lib/redis/"`;
docker cp dfbf8c0c0625:/data/dump.rdb /var/lib/redis/dump.rdb
RDB文件恢复数据流程
1、先备份一份 dump.rdb 为 dump_bak.rdb(模拟线上)2、flushall 清空数据(模拟数据丢失,需要注意 flushall 也会触发rbd持久化)
3、将 dump_bak.rdb 替换为 dump.rdb
4、重启redis服务,恢复数据
2.AOF 方式
描述: AOF是redis对将所有的写命令保存到一个aof文件中,根据这些写命令实现数据的持久化和数据恢复。
AOF文件生成机制
答: 生成过程包括三个步骤,即
命令追加、文件写入、文件同步。redis 打开AOF持久化功能之后,redis在执行完一个写命令后,把执行的命令首先追加到redis内部的aof_buf缓冲区膜末尾,此时缓冲区的记录还没有写到appendonly.aof文件中。然后,缓冲区的写命令会被写入到 AOF 文件,这一过程是文件写入过程。对于操作系统来说,调用write函数并不会立刻将数据写入到硬盘,为了将数据真正写入硬盘,还需要调用fsync函数,调用fsync函数即是文件同步的过程,只有经过了文件的同步过程,写命令才真正的被保存到了AOF文件中。选项 appendfsync 就是配置同步的频率的。
AOF文件重写
- 1、redis不断的将写命令保存到AOF文件中,导致AOF文件越来越大,当AOF文件体积过大时,数据恢复的时间也是非常长的,因此,redis提供了重写或者说压缩AOF文件的功能。
比如
对key1初始值是0,调用incr命,100次,key1的值变为100,那么其实直接一句set key1 100 就可以顶之前的100局调用,AOF重写功能就是干这个事情的。重写时,可以调用BGREWRITEAOF命令重写AOF文件,与新建子线程bgsave命令的工作原理相似。也可以通过配置文件配置什么条件下对AOF文件重写。 - 2、重写的原理:Redis 会fork出一条新进程,读取内存中的数据,并重新写到一个临时文件中。并没有读取旧文件(太大了)。最后替换旧的aof文件
- 3、重写触发机制:当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发,这里的“一倍”和“64M” 可以通过配置文件修改
优势
- 该机制可以带来更高的数据安全性,即数据持久化; 常规三种同步策略即每秒同步(
异步完成效率高)、每修改同步(同步插入修改删除操作效率最低)和不同步;
- 该机制可以带来更高的数据安全性,即数据持久化; 常规三种同步策略即每秒同步(
- 由于该机制对日志文件的写入操作采用的是append模式,即使过程中出现宕机也不会破坏日志文件中已经存在的内容,如果数据不完整在Redis下次启动之前, 通过redis-check-aof解决数据一致性问题;
- 如果日志文件体积过大可以启动rewrite机制,即redis以append模式不断的将修改数据写到老的磁盘文件中,同时创建新文件记录期间有哪些修改命令执行,此项极大的保证数据的安全性;
- AOF文件可读性强,其包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作(
可通过此文件完成数据的重构)
- AOF文件可读性强,其包含一个格式清晰、易于理解的日志文件用于记录所有的修改操作(
- 数据的完整性和一致性更高
- 数据的完整性和一致性更高
劣势
- AOF文件比RDB文件较大, 对于相同数量的数据集而言;
- redis负载较高时,RDB文件比AOF文件具有更好的性能;
- RDB使用快照的方式持久化整个redis数据,而aof只是追加写命令,因此从理论上来说,RDB比AOF方式更加健壮,另外,官方文档也指出,在某些情况下,AOF的确也存在一些bug,比如使用阻塞命令时,这些bug的场景RDB是不存在的。
- 因为AOF记录的内容多,文件会越来越大,数据恢复也会越来越慢。
- 根据同步策略的不同,AOF在运行效率上往往会慢于RDB,总的来说每秒同步策略的效率还是比较高的
Q: 如何触发AOF快照?
答: 根据配置文件触发,可以是每次执行触发,可以是每秒触发,可以不同步。
Q: 如何根据AOF文件恢复数据?
答: 正常情况下,将appendonly.aof 文件拷贝到redis的安装目录的bin目录下,重启redis服务即可。但在实际开发中,可能因为某些原因导致
appendonly.aof文件格式异常,从而导致数据还原失败,可以通过命令redis-check-aof --fix appendonly.aof进行修复 。
配置说明:
cat > redis.conf <<"EOF"# 持久化数据存储
dir "/data"
# 是否开启AOF默认为否
appendonly yes
# AOF文件名字及路径,若RDB路径已设置这里可不设置
appendfilename "appendonly.aof"
# AOF的3种模式,no(使用系统缓存处理,快)、always(记录全部操作,慢但比较安全)、everysec(每秒同步,折中方案,默认使用)
appendfsync everysec
# 重写期间是否同步数据,默认为no
no-appendfsync-on-rewrite no
# 配置重写触发机制: 确保AOF日志文件不会过大,保持跟redis内存数据量一致。
# 配置说明:当AOF文件大小是上次rewrite后大小的一倍且文件大于64M时触发(根据实际环境进行配置)
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 256mb
# AOF重写策略是否启用,默认为yes
aof-rewrite-incremental-fsync yes
# 加载AOF时如果报错则会继续但写入log,如果为no则不会继续
aof-load-truncated yes
# Redis5.0有的功能AOF重写及恢复可以使用RDB文件及AOF文件,速度更快,默认yes
aof-use-rdb-preamble yes
EOF
Q: 如何通过AOF文件恢复数据流程?
1、执行flushall,模拟数据丢失2、重启 redis 服务,恢复数据
3、修改 appendonly.aof,模拟文件异常
4、重启 Redis 服务失败,这同时也说明了RDB和AOF可以同时存在,且优先加载AOF文件。
5、使用 redis-check-aof 校验 appendonly.aof 文件。
# 针对Redis aof 持久化文件进行完整性检测并进行修复
/usr/local/redis/bin/redis-check-aof --fix appendonly.aof
# The AOF appears to start with an RDB preamble.
# Checking the RDB preamble to start:
# [offset 0] Checking RDB file appendonly.aof
# [offset 27] AUX FIELD redis-ver = "5.0.10"
# [offset 41] AUX FIELD redis-bits = "64"
# [offset 53] AUX FIELD ctime = "1631088747"
# [offset 68] AUX FIELD used-mem = "31554944"
# [offset 84] AUX FIELD aof-preamble = "1"
# [offset 86] Selecting DB ID 0
# [offset 13350761] Checksum OK
# [offset 13350761] o/ RDB looks OK! o/
# [info] 157070 keys read
# [info] 0 expires
# [info] 0 already expired
# RDB preamble is OK, proceeding with AOF tail...
# 0x 27b66b0: Expected prefix "*", got: "R"
# AOF analyzed: size=116993914, ok_up_to=41641648, ok_up_to_line=1816854, diff=75352266
# AOF is not valid. Use the option to try fixing it.
6、重启Redis 服务后正常。
# 利用源实例生成的aof文件数据进行恢复到其它主机中。
redis-cli -h 17.20.0.2 -a password --pipe < applendonly.aof
注意:当你使用 flushall 清空数据的时候,重启redis服务发现数据没恢复,是因为 FLUSHALL 命令也被写入AOF文件中,会导致数据恢复失败,所只需要删除aof文件中的flushall就行了
Tips : 在数据库恢复时把 aof(append only file) 从中对redis数据库操作的命令,增删改操作的命令,执行了一遍即可。
实际案例:
描述: 用于异步执行一个 AOF(AppendOnly File) 文件重写操作, 重写会创建一个当前 AOF 文件的体积优化版本,因为AOF为记录每次的操作会导致实际记录冗杂、使得文件过大,所以需要做重写操作。
重写方式分为以下两种:
# (1) AOF自动重写:按配置文件条件自动触发重写auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 256mb
# (2) AOF手动重写:使用 redis-cli 连接到 server 端执行 bgrewriteaof 进行手动重写。
# 注意:从 Redis 2.4 开始, AOF 重写由 Redis 自行触发, BGREWRITEAOF 仅仅用于手动触发重写操作。
127.0.0.1:6379> BGREWRITEAOF
# 即使 Bgrewriteaof 执行失败,也不会有任何数据丢失,因为旧的 AOF 文件在 Bgrewriteaof 成功之前不会被修改。
Background append only file rewriting started
如何抉择 RDB OR AOF?
描述: 在实际生产环境中不要仅使用RDB(加载快、不保证数据完整性)或仅使用AOF(加载慢、数据完整性保证), 所以推荐综合使用AOF和RDB两种持久化机制进行数据备份。
- AOF 机制保证数据不丢失,并且文件有一定的可读性即可以选择性恢复一部分数据,所以作为数据恢复的第一选择;
- RDB 机制在AOF文件都丢失或损坏不可用的时候,可以利用其冷备文件来进行快速的数据恢复;
AOF和RDB同时工作特点:
- 当 rdb 进行 snapshotting 时, redis 便不会再执行 AOF rewrite, 反之则一样。
- 当 rdb 进行 snapshotting 时, 其它用户也在执行 BGREWRITEAOF 命令, 结果是只有等RDB快照生成之后,才会执行AOF rewrite;
- 当同时拥有rdb 快照文件和AOF日志文件时, Redis 重启时会优先使用AOF日志进行恢复,。
- 数据恢复完全依赖于磁盘持久化,如果rdb和aof上都没有数据,数据就无法恢复了。
Tips : 重点再记录、为保证数据容灾建议启用rdb与aof持久化机制,前者保证数据备份而后者保证数据的完整性。
Tips : 重点再记录、当在服务器中同时启用rdb与aof持久化机制时,在redis服务启动时优先加载AOF文件(其数据的完整性)。
合并两个不同实例的数据
描述: 我们可以利用如下方式进行集群多个主节点持久化数据的合并。
(1) AOF 备份合并: 我们说过它实际上是一些列Redis的命令文本。
例如,假设有两台 Redis(6379, 6479),它们的AOF文件名分别为(6379.aof, 6479.aof),现在要将6379的数据合并到 6479.aof
# 首先cp 6379.aof 6379.aof.bak, cp 6479.aof 6479.aof.bak
# 合并
cat 6379.aof 6479.aof > new.aof
# 检查&修复
/usr/local/redis/bin/redis-check-aof --fix appendonly.aof
(2) RDB 备份合并: 注意以下方法可能由于服务端版本不同而有些许差异。
RDB格式如下:头5个字节是字符REDIS,之后4个字节代表版本号,阿里的版本分别是 00 00 00 06,之后2个字节 FE 00,FE是标识 00是数据库,还好我们只有一个库, 最后的结尾9个字节 , FF 加上8个字节的CRC64校验码(实在没空弄,后来偷了一个懒)
# 1.线上服务使用的阿里云的集群版本redis服务,数据量1千万,rdb文件4GB,8个rdb文件,每个500MB。#文件1 大小566346503,截取尾部的9个字节
dd bs=1 if=src_1.rdb of=1.rdb count=566346494
#文件2 大小570214520,跳过头部的11个字节,再截取尾部的9个字节
dd bs=1 if=src_2.rdb of=2.rdb skip=11 count=570214500
...
#文件8 大小569253061,跳过头部的11个字节,再截取尾部的8个字节,保留FF。
dd bs=1 if=src_8.rdb of=8.rdb skip=11 count=569253042
# 2.合并文件(得到备份文件dump.rdb)
cat 1.rdb > dump.rdb
cat 2.rdb >> dump.rdb
...
cat 8.rdb >> dump.rdb
# 3.检查备份文件(应该会提示没有crc校验)
redis-check-rdb dump.rdb
# 4.修改配置文件,因为数据库备份文件里面不包含crc64的校验码,配置文件中关闭选项。
rdbchecksum no
Tips : 数据恢复到此结束,此方法只适合用于临时恢复和导出数据,数据完整性不敢保证。
参考地址: https://github.com/sripathikrishnan/redis-rdb-tools/wiki/Redis-RDB-Dump-File-Format
其它工具:
- https://github.com/leonchen83/redis-rdb-cli/ | 一个可以解析, 过滤, 分割, 合并 rdb 离线内存分析的工具. 也可以在两个redis之前同步数据并允许用户自定义同步服务来把redis数据同步到其他地方.
0x01 备份容灾
一、备份
1.手动备份redis数据库
#!/bin/bash# 方式1.通过redis-cli内置命令将内存中的数据存储到rdb文件中
echo "auth 123456
ping
save
" | redis-cli -h 127.0.0.1 -p 6379
echo "auth 123456
ping
bgsave
" | redis-cli -h 127.0.0.1 -p 6379
# 方式2.将远程主机Redis-Server中存储的数据保存到本地/tmp/backup/目录中。
redis-cli -h 127.0.0.1 -p 6379 --rdb /tmp/backup/app-6379.rdb
# 方式3.定时执行拷贝rdb与aof文件进行备份。
# 例如: 每天0点执行一次 0 0 * * * sh /tmp/redisBackup.sh
current_date=$(date +%Y%m%d-%H%M%S)
BACKUPDIR="/backup/redis"
RDBFILE="/data/dump.rdb"
AOFFILE="/data/appendonly.aof"
# del_date=$(date -d -1day +%Y%m%d)
if [ ! -d ${BACKUPDIR} ];then
mkdir -vp ${BACKUPDIR}
fi
if [ ! -f ${RDBFILE} ];then
cp -a ${RDBFILE} ${BACKUPDIR}/${current_date}-dump.rdb
fi
if [ ! -f ${AOFFILE} ];then
cp -a ${AOFFILE} ${BACKUPDIR}/${current_date}-appendonly.aof
fi
# 删除七天前的备份
find ${BACKUPDIR} -type f -mtime +7 >> delete.log
find ${BACKUPDIR} -type f -mtime +7 -exec rm -rf {} ;
2.迁移Redis指定db-数据库
方式1.同主机db迁移到另外一个dbn中
$ redis-cli -h localhost -a weiyigeek.top -n 0 keys "*" | while read keydo
redis-cli -h localhost -a weiyigeek.top -n 0 --raw dump $key | perl -pe "chomp if eof" | redis-cli -h localhost -a weiyigeek.top -n 12 -x restore $key 0
done
方式2.跨主机迁移db
# redis 把db2 的数据迁移到 db14 里 (注意:某些格式的数据不能完全已此种方式进行迁移)# 需求分析:
"""1、建立两个redis连接
2、获取所有的keys()
3、获取keys的类型:string hash"""
import redis
src_redis = redis.Redis(host="211.149.218.16",
password="123456",
port=6379,
db=2)
target_redis = redis.Redis(host="211.149.218.16",
password="123456",
port=6379,
db=14)
for key in src_redis.keys(): # redis获取的数据都是bytes类型的,所以key的类型是 bytes 类型
if src_redis.type(key) == b"string":# 也可以用decode() 把key转换成string,这样等号右边就不需要加b
v = src_redis.get(key) #先获取原来的数据
target_redis.set(key,v) #set到新的数据库里
else:
all_hash_data = src_redis.hgetall(key) # 获取hash类型里面所有的数据,获取出来的数据是字典格式的 但是有b,需要转换
for k,v in all_hash_data.items():# 因为获取到字典格式的hash类型的原数据有b,所以需要用for循环来进行转换后重新赋值给新的数据库
target_redis.hset(key,k,v) # key是外面的,k是里面的key,v是k对应的value
3.Redis集群数据备份与迁移
描述: 当我们需要备份或迁移Redis集群时可以采用以下方案。
# (1) 备份集群数据到本地目录中(已rdb格式文件存储)。redis-cli -a weiyigeek --cluster backup 172.16.243.97:6379 .
# >>> Node 172.16.243.97:6379 -> Saving RDB...
# SYNC sent to master, writing 178 bytes to "./redis-node-172.16.243.97-6379-d97cb5b15b7130ca0bd5322758e0c2dce061fd7b.rdb"
# Transfer finished with success.
# >>> Node 172.16.183.95:6379 -> Saving RDB...
# SYNC sent to master, writing 178 bytes to "./redis-node-172.16.183.95-6379-94b8d3748dc47053454e657da8d6bb90e0081f2c.rdb"
# Transfer finished with success.
# >>> Node 172.16.24.214:6379 -> Saving RDB...
# SYNC sent to master, writing 178 bytes to "./redis-node-172.16.24.214-6379-2674f21a88a9573f51ec46f9dc248ad4a5c5974d.rdb"
# Transfer finished with success.
# (2) 把 192.168.1.187:6379 上的数据导入到 192.168.75.187:6379 这个节点所在的集群,如有密码将询问
redis-cli -a weiyigeek --cluster import 192.168.75.187:6379 --cluster-from 192.168.1.187:6379 --cluster-from-askpass --cluster-copy
# (3) 迁移后利用 dbsize 命令查看数据是否正确
Tips: 第三方redis集群数据迁移工具项目参考(https://github.com/alibaba/RedisShake)
二、恢复
1.系统Redis用户被删除后配置数据恢复流程
描述:在系统删除了配置文件后以及用户账号后恢复方法流程,实际环境中建议利用rdb文件进行重新部署。
Step1.Redis账户数据恢复首先确定系统中是否还有redis用户。(如果拷贝过来的系统也安装了redis,那么肯定是会有redis账户)
Step2.如果发现有redis用户以下步骤可以跳过,否则进行手动添加。
echo "redis:x:996:994:Redis Database Server:/var/lib/redis:/sbin/nologin" >> /etc/passwdecho "redis:!!:17416::::::" >> /etc/shadow
echo "redis:x:994:" >> /etc/group
echo "redis:!::" >> /etc/gshadow
- Step3.Redis配置文件恢复, Redis的配置文件恢复相对简单一些,官方提供了
CONFIG REWRITE命令重写redis.conf配置文件。
redis-cli> CONFIG REWRITE
OK
- Step4.修改配置文件权限
touch /etc/redis.confchown redis:redis /etc/redis.conf
2.Kubernetes中单实例异常数据迁移恢复实践
方案1.利用其他kubernetes集群进行恢复原k8s集群的redis数据。
#!/bin/bash# author: WeiyiGeek
# usage: ./K8SRedisRecovery.sh [aof|rdb] redis原持久化目录
BACKUP_TYPE=$1
BACKUP_DIR=$2
DATA_DIR="$(pwd)/data"
echo "开始时间: $(date +%s)"
# 1.判断备份文件以及持久化文件是否存在
if [ ! -d ${BACKUP_DIR} ];then echo -e "[Error] - Not Found ${BACKUP_DIR} Dirctory!"; return -1; fi
if [ ! -d ${DATA_DIR} ];then mkdir -vp ${DATA_DIR};else rm -rf "${DATA_DIR}/*"; fi
# 2.redis配置与k8s部署恢复redis清单
# tee redis.conf <<"EOF"
# bind 0.0.0.0
# port 6379
# daemonize no
# supervised no
# protected-mode no
# requirepass "weiyigeek"
# dir "/data"
# pidfile "/var/run/redis.pid"
# logfile "/var/log/redis.log"
# loglevel verbose
# maxclients 10000
# timeout 300
# tcp-keepalive 60
# maxmemory-policy volatile-lru
# slowlog-max-len 128
# lua-time-limit 5000
# save 300 10
# save 60 10000
# dbfilename "dump.rdb"
# rdbcompression yes
# rdb-save-incremental-fsync yes
# # appendonly yes
# appendfilename "appendonly.aof"
# appendfsync everysec
# # rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
# rename-command FLUSHDB WeiyiGeekFLUSHDB
# rename-command FLUSHALL WeiyiGeekFLUSHALL
# rename-command EVAL WeiyiGeekEVAL
# rename-command DEBUG WeiyiGeekDEBUG
# rename-command SHUTDOWN WeiyiGeekSHUTDOWN
# EOF
tee redisrecovery.yaml <<"EOF"
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-recovery
namespace: database
data:
redis.conf: |+
bind 0.0.0.0
port 6379
daemonize no
supervised no
protected-mode no
requirepass "weiyigeek"
dir "/data"
pidfile "/var/run/redis.pid"
logfile "/var/log/redis.log"
loglevel verbose
maxclients 10000
timeout 300
tcp-keepalive 60
maxmemory-policy volatile-lru
slowlog-max-len 128
lua-time-limit 5000
save 300 10
save 60 10000
dbfilename "dump.rdb"
rdbcompression yes
rdb-save-incremental-fsync yes
# appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
rename-command FLUSHDB WeiyiGeekFLUSHDB
rename-command FLUSHALL WeiyiGeekFLUSHALL
rename-command EVAL WeiyiGeekEVAL
rename-command DEBUG WeiyiGeekDEBUG
rename-command SHUTDOWN WeiyiGeekSHUTDOWN
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-recovery
namespace: database
spec:
serviceName: redisrecovery
replicas: 1
selector:
matchLabels:
app: redis-recovery
template:
metadata:
labels:
app: redis-recovery
spec:
containers:
- name: redis
image: redis:6.2.5-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
name: server
command: [ "redis-server", "/conf/redis.conf"]
volumeMounts:
# 从configmap获取的配置文件,挂载到指定文件中
- name: conf
mountPath: /conf/redis.conf
subPath: redis.conf
- name: data
mountPath: /data
# 时区设置
- name: timezone
mountPath: /etc/localtime
volumes:
- name: conf
# 配置文件采用configMap
configMap:
name: redis-recovery
defaultMode: 0755
# redisc持久化目录采用hostPath卷
- name: data
hostPath:
type: DirectoryOrCreate
path: {PersistentDir}
# 时区定义
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
---
apiVersion: v1
kind: Service
metadata:
name: redisrecovery
namespace: database
spec:
type: ClusterIP
ports:
- port: 6379
targetPort: 6379
name: server
selector:
app: redis-recovery
EOF
# 3.删除原有的恢复Pod
kubectl delete -f redisrecovery.yaml
# kubectl delete configmap -n database redis-recovery
# 4.判断redis备份格式
if [ "${BACKUP_TYPE}" == "aof" ];then
sed -i "s|# appendonly yes|appendonly yes|g" redisrecovery.yaml
cp -a ${BACKUP_DIR}/appendonly.aof ${DATA_DIR}
else
cp -a ${BACKUP_DIR}/dump.rdb ${DATA_DIR}
fi
# 5.更新redis备份恢复k8s资源清单中的持久化目录
sed -i "s#{PersistentDir}#${DATA_DIR}#g" redisrecovery.yaml
# 6.创建configmap和部署redis备份恢复应用
# kubectl create configmap -n database redis-recovery --from-file=$(pwd)/redis.conf
kubectl create --save-config -f redisrecovery.yaml
# 7.验证Pod状态是否正常
flag=$(kubectl get pod -n database -o wide -l app=redis-recovery | grep -c "Running")
echo -e "e[31m[Error]: Pod Status is not Running! e[0m"
while [ ${flag} -ne 1 ];do
sleep 0.5
flag=$(kubectl get pod -n database -o wide -l app=redis-recovery | grep -c "Running")
done
# 8.验证数据是否恢复
# apt install -y redis-tools
echo "[OK] redis-recovery Status is Running"
echo -e "AUTH weiyigeek
ping
info" | redis-cli -h redisrecovery.database.svc.cluster.local | grep -A 16 "# Keyspace"
while [ $? -ne 0 ];do
echo -e "AUTH weiyigeek
ping
info" | redis-cli -h redisrecovery.database.svc.cluster.local | grep -A 16 "# Keyspace"
done
echo "数据恢复完成......"
echo "完成时间: $(date +%s)"
命令执行示例:
# (1) 利用 AOF 文件进行恢复百万数据/nfsdisk-31/datastore/redis/demo2# time ./K8sredisRecovery.sh aof /nfsdisk-31/data/database-data-redis-cm-0-pvc-00ee48e8-b1ca-4640-96c5-16f7265a2c61
# # Keyspace
# db0:keys=1000000,expires=0,avg_ttl=0
# 数据恢复完成......
# 完成时间: 1631067931
# real 0m12.039s
# user 0m0.647s
# sys 0m0.199s
/nfsdisk-31/datastore/redis/demo2/data# ls -alh
# -rw-r--r-- 1 root root 41M Sep 7 22:14 appendonly.aof
# -rw-r--r-- 1 root root 41M Sep 8 2021 dump.rdb
# (2) 利用 rdb 文件进行恢复 百万数据
root@WeiyiGeek-107:/nfsdisk-31/datastore/redis/demo2# time ./K8sredisRecovery.sh rdb /nfsdisk-31/data/database-data-redis-cm-0-pvc-00ee48e8-b1ca-4640-96c5-16f7265a2c61
# # Keyspace
# db0:keys=993345,expires=0,avg_ttl=0
# 数据恢复完成......
# 完成时间: 1631069375
# real 0m11.106s
# user 0m0.606s
# sys 0m0.192s
/nfsdisk-31/datastore/redis/demo2# ls -lah data/
# -rw-r--r-- 1 root root 41M Sep 8 2021 dump.rdb
# root@WeiyiGeek-107:/nfsdisk-31/datastore/redis/demo2#
Tips : 从上述恢复结果可以看出以aof方式恢复的数据比rdb恢复的数据完整,但所加载的时间会随着数据增大会使得AOF方式耗时比rdb耗时更多。
方案2.利用宿主机安装编译redis源码,进行恢复原k8s集群的redis数据
#!/bin/bash# author: WeiyiGeek
# usage: ./RedisRecovery.sh [aof|rdb] redis原持久化目录
# 验证环境: Ubuntu 20.04.1 LTS
# 脚本说明: 将Redis数据恢复到物理中
if [ $# -eq 0 ];then
echo -e "e[31m[*] $0 [aof|rdb] redis原持久化目录 e[0m"
exit
fi
BACKUP_TYPE=$1
BACKUP_DIR=$2
DATA_DIR="$(pwd)/data"
REDIS_DIR="/usr/local/redis"
echo "开始时间: $(date +%s)"
if [ ! -d ${BACKUP_DIR} ];then echo -e "[Error] - Not Found ${BACKUP_DIR} Dirctory!"; return -1; fi
if [ ! -d ${DATA_DIR} ];then mkdir -vp ${DATA_DIR};else rm -rf "${DATA_DIR}/*"; fi
## 1.基础环境准备
# - 设置内存分配策略
sudo sysctl -w vm.overcommit_memory=1
# - 尽量使用物理内存(速度快)针对内核版本大于>=3.x
sudo sysctl -w vm.swapniess=1
# - SYN队列长度设置,此参数可以容纳更多等待连接的网络。
sudo sysctl -w net.ipv4.tcp_max_syn_backlog=4096
# - 禁用 THP 特性减少内存消耗
echo never > /sys/kernel/mm/transparent_hugepage/enabled
# redis 客户端: apt remove redis-tools
## 2.REDIS 源码包
if [ ! -f /usr/local/redis/redis.conf ];then
REDIS_VERSION="redis-6.2.5"
REDIS_URL_TAR="https://download.redis.io/releases/${REDIS_VERSION}.tar.gz"
REDIS_TAR="${REDIS_VERSION}.tar.gz"
# redis 编译环境以及编译redis安装在指定目录
apt install -y gcc make gcc+ pkg-config
wget ${REDIS_URL_TAR} -O /tmp/${REDIS_TAR}
tar -zxf /tmp/${REDIS_TAR} -C /usr/local/
mv /usr/local/${REDIS_VERSION} ${REDIS_DIR}
cd ${REDIS_DIR} && make distclean
make PREFIX=${REDIS_DIR} install
cp -a ${REDIS_DIR}/redis.conf /etc/redis.conf
for i in $(ls -F ${REDIS_DIR}/bin | grep "*"| sed "s#*##g");do
sudo chmod +700 ${REDIS_DIR}/bin/${i}
sudo ln -s ${REDIS_DIR}/bin/${i} /usr/local/bin/${i}
done
fi
# 物理机运行可以将daemonize设置为后台运行。
tee ${REDIS_DIR}/redis.conf <<"EOF"
bind 0.0.0.0
port 6379
daemonize yes
supervised no
protected-mode no
requirepass "weiyigeek"
dir "/data"
pidfile "/var/run/redis.pid"
logfile "/var/log/redis.log"
# loglevel verbose
maxclients 10000
timeout 300
tcp-keepalive 60
maxmemory-policy volatile-lru
slowlog-max-len 128
lua-time-limit 5000
save 900 1
save 300 100
save 60 10000
dbfilename "dump.rdb"
rdbcompression yes
rdb-save-incremental-fsync yes
# appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
# rename-command CONFIG b840fc02d524045429941cc15f59e41cb7be6c52
rename-command FLUSHDB WeiyiGeekFLUSHDB
rename-command FLUSHALL WeiyiGeekFLUSHALL
rename-command EVAL WeiyiGeekEVAL
rename-command DEBUG WeiyiGeekDEBUG
rename-command SHUTDOWN WeiyiGeekSHUTDOWN
EOF
# 3.判断要使用的备份格式
if [ "${BACKUP_TYPE}" == "aof" ];then
sed -i "s|# appendonly yes|appendonly yes|g" ${REDIS_DIR}/redis.conf
cp -a ${BACKUP_DIR}/appendonly.aof ${DATA_DIR}
else
cp -a ${BACKUP_DIR}/dump.rdb ${DATA_DIR}
fi
sed -i "s#/data#${DATA_DIR}#g" ${REDIS_DIR}/redis.conf
# 4.启动redis服务恢复数据
${REDIS_DIR}/bin/redis-server ${REDIS_DIR}/redis.conf
ps -aux | grep redis-server
echo -e "AUTH weiyigeek
ping
info" | redis-cli -h 127.0.0.1 | grep -A 16 "# Keyspace"
while [ $? -ne 0 ];do
echo -e "AUTH weiyigeek
ping
info" | redis-cli -h 127.0.0.1 | grep -A 16 "# Keyspace"
done
echo "数据恢复完成......"
echo "完成时间: $(date +%s)"
方案3.利用Kubernetes部署的Redis集群,进行恢复原k8s集群的redis数据
#!/bin/bash# author: WeiyiGeek
# K8s 中 redis 集群数据恢复
# useage: K8SRedisClusterRecovery.sh [single|cluster] PODMATCH K8SVOLUMNDIR
if [ $# -eq 0 ];then
echo -e "e[31m[*] $0 [single|cluster] PODMATCH K8SVOLUMNDIR e[0m"
echo -e "e[31m[*] PODMATCH : redis-cluster {异常集群 statefulset 资源对象名称} e[0m"
echo -e "e[31m[*] K8SVOLUMNDIR : /nfsdisk-31/data {K8S 持久化跟目录} e[0m"
exit
fi
RECTARGET="${1}"
PODMATCH="${2}"
K8SVOLUMNDIR="${3}"
AUTH="weiyigeek"
PWD=$(pwd)
AOFNAME="appendonly.aof"
DATADIR="${PWD}/database"
K8SSVCNAME="database.svc.cluster.local"
# 1.原`Redis`集群nodes信息一览,获取aof文件路径。
grep "myself,master" ${K8SVOLUMNDIR}/*${PODMATCH}-[0-9]-*/nodes.conf | head -n 3 > /tmp/nodes.log
cat /tmp/nodes.log
node1=$(grep "0-5460" /tmp/nodes.log | cut -d ":" -f 1)
aofpath1=${node1%/*}
node2=$(grep "5461-10922" /tmp/nodes.log | cut -d ":" -f 1)
aofpath2=${node2%/*}
node3=$(grep "10923-16383" /tmp/nodes.log | cut -d ":" -f 1)
aofpath3=${node3%/*}
# 2.验证aof文件是否存在并拷贝到当前路径下,合并AOF文件到当前目录的data下。
if [ ! -f ${aofpath1}/${AOFNAME} -o ! -f ${aofpath2}/${AOFNAME} -o ! -f ${aofpath3}/${AOFNAME} ];then echo -e "e[31m[-] ${AOFNAME} file not found e[0m";exit;fi
cp ${aofpath1}/${AOFNAME} ./1.${AOFNAME}
cp ${aofpath2}/${AOFNAME} ./2.${AOFNAME}
cp ${aofpath3}/${AOFNAME} ./3.${AOFNAME}
if [ ! -d ${DATADIR} ];then mkdir -v ${DATADIR};fi
cat *.aof > ${DATADIR}/${AOFNAME}
# 校验合并的原集群aof文件并尝试进行修复
echo "y" | /usr/local/redis/bin/redis-check-aof --fix ${DATADIR}/${AOFNAME}
ls -alh ${DATADIR}
# 3.验证原集群相关文件是否有误(如有误需要人工进行相应处理)
echo -e "e[32m[*] 请验证原Redis集群Nodes信息是否无误? 请输入[Y|N] e[0m"
read flag
if [ "${flag}" == "N" -o "${flag}" == "n" ];then echo -e "e[31m[-] FAILED: 需要人工进行干预处理. e[0m";exit;fi
# 4.判断恢复到单实例还是cluster集群中。
if [ "${RECTARGET}" == "single" ];then
echo -e "e[32m[*] 正在进行异常的K8S集群 -> 单实例数据恢复! e[0m"
./K8SRedisRecovery.sh aof ${DATADIR}
return 0
else
echo -e "e[32m[*] 正在进行异常的K8S集群 -> 集群数据恢复! e[0m"
fi
# 5.redis集群资源清单(注意:此处默认是采用nfs类型的动态卷)
tee Redis-cluster-6.2.5.yaml <<"EOF"
apiVersion: v1
kind: ConfigMap
metadata:
name: redis-cluster-recovery
namespace: database
data:
update-node.sh: |
#!/bin/sh
if [ ! -f /data/nodes.conf ];then touch /data/nodes.conf;fi
REDIS_NODES="/data/nodes.conf"
sed -i -e "/myself/ s/[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}.[0-9]{1,3}/${POD_IP}/" ${REDIS_NODES}
exec "$@"
redis.conf: |+
port 6379
protected-mode no
masterauth {RedisAuthPass}
requirepass {RedisAuthPass}
dir /data
dbfilename dump.rdb
rdbcompression yes
no-appendfsync-on-rewrite no
appendonly yes
appendfilename appendonly.aof
appendfsync everysec
auto-aof-rewrite-percentage 100
auto-aof-rewrite-min-size 128mb
# 集群模式打开
cluster-enabled yes
cluster-config-file /data/nodes.conf
cluster-node-timeout 5000
slave-read-only yes
# 当负责一个插槽的主库下线且没有相应的从库进行故障恢复时集群仍然可用
cluster-require-full-coverage no
# 只有当一个主节点至少拥有其他给定数量个处于正常工作中的从节点的时候,才会分配从节点给集群中孤立的主节点
cluster-migration-barrier 1
---
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: redis-cluster-recovery
namespace: database
spec:
serviceName: redisclusterrecovery
replicas: 6
selector:
matchLabels:
app: redis-cluster-recovery
template:
metadata:
labels:
app: redis-cluster-recovery
spec:
containers:
- name: redis
image: redis:6.2.5-alpine
imagePullPolicy: IfNotPresent
ports:
- containerPort: 6379
name: client
- containerPort: 16379
name: gossip
command: ["/conf/update-node.sh", "redis-server", "/conf/redis.conf"]
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: conf
mountPath: /conf
readOnly: false
- name: data
mountPath: /data
readOnly: false
- name: timezone
mountPath: /etc/localtime
volumes:
- name: conf
configMap:
name: redis-cluster-recovery
defaultMode: 0755
- name: timezone
hostPath:
path: /usr/share/zoneinfo/Asia/Shanghai
volumeClaimTemplates:
- metadata:
name: data
spec:
accessModes: [ "ReadWriteOnce" ]
storageClassName: "managed-nfs-storage"
resources:
requests:
storage: 1Gi
---
# headless Service
apiVersion: v1
kind: Service
metadata:
name: redisclusterrecovery
namespace: database
spec:
clusterIP: "None"
ports:
- port: 6379
targetPort: 6379
name: client
- port: 16379
targetPort: 16379
name: gossip
selector:
app: redis-cluster-recovery
EOF
sed -i "s#{RedisAuthPass}#${AUTH}#g" Redis-cluster-6.2.5.yaml
sed "s#replicas: 6#replicas: 0#g" Redis-cluster-6.2.5.yaml > Redis-cluster-6.2.5-empty.yaml
# 6.部署恢复数据的redis集群:判断是否存在旧的资源对象,是则清理相关文件,否则创建集群。
sts=$(kubectl get sts -n database | grep -c "redis-cluster-recovery")
if [ ${sts} -eq 1 ];then
# 将副本数量至为0
kubectl apply -f Redis-cluster-6.2.5-empty.yaml;
podrun=$(kubectl get pod -n database | grep -c "redis-cluster-recovery")
while [ ${run} -ne 0 ];do podrun=$(kubectl get pod -n database | grep -c "redis-cluster-recovery");sleep 5;echo -n .; done
find ${K8SVOLUMNDIR}/database-data-redis-cluster-recovery-* -type f -delete;
# 清理后将副本数量至为6
kubectl apply -f Redis-cluster-6.2.5.yaml
run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running")
while [ ${run} -ne 6 ];do run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running");sleep 2;echo -n .; done
else
# 新建部署集群资源清单
kubectl create --save-config -f Redis-cluster-6.2.5.yaml
run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running")
while [ ${run} -ne 6 ];do run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running");sleep 2;echo -n .; done
fi
echo -e "e[32m[*] Happy,redis-cluster-recovery Pod is Running....e[0m"
kubectl get pod -n database -l app=redis-cluster-recovery
# 7.redis集群快速创建配置
echo -e "yes" | redis-cli -h redisclusterrecovery.${database.svc.cluster.local} -a weiyigeek --cluster create --cluster-replicas 1 $(kubectl get pods -n database -l app=redis-cluster-recovery -o jsonpath="{range.items[*]}{.status.podIP}:6379 "| sed "s# :6379 ##g")
# 将其他两个Master卡槽归于一个Master
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.${database.svc.cluster.local} --no-auth-warning -a weiyigeek cluster nodes | grep "master" > /tmp/rnodes.log
cat /tmp/rnodes.log
m1=$(grep "0-5460" /tmp/rnodes.log | cut -d " " -f 1)
m2=$(grep "5461-10922" /tmp/rnodes.log | cut -d " " -f 1)
m3=$(grep "10923-16383" /tmp/rnodes.log | cut -d " " -f 1)
redis-cli --no-auth-warning -a weiyigeek --cluster reshard --cluster-from ${m2} --cluster-to ${m1} --cluster-slots 5462 --cluster-yes redis-cluster-recovery-0.redisclusterrecovery.${database.svc.cluster.local}:6379 > /dev/null
redis-cli --no-auth-warning -a weiyigeek --cluster reshard --cluster-from ${m3} --cluster-to ${m1} --cluster-slots 5461 --cluster-yes redis-cluster-recovery-0.redisclusterrecovery.${database.svc.cluster.local}:6379 > /dev/null
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local --no-auth-warning -a weiyigeek cluster nodes
echo -e "e[32m[*] 请验证Nodes信息是否无误? 请输入[Y|N] e[0m"
read flag
if [ "${flag}" == "N" -o "${flag}" == "n" ];then echo -e "e[31m[-] FAILED: 需要人工进行干预处理. e[0m";exit;fi
# 8.将所有slots都归于一个master节点后我们需要,将redisclusterrecovery 资源对象所管理的Pod先关闭。
# 将副本数量至为0
kubectl apply -f Redis-cluster-6.2.5-empty.yaml;
podrun=$(kubectl get pod -n database | grep -c "redis-cluster-recovery")
while [ ${run} -ne 0 ];do podrun=$(kubectl get pod -n database | grep -c "redis-cluster-recovery");sleep 5;echo -n .; done
# find ${K8SVOLUMNDIR}/database-data-redis-cluster-recovery-* -type f -delete;
# 此处只清空了redis持久化数据文件。
master=$(find /nfsdisk-31/data/*redis-cluster-recovery-0* -type d)
rm -rf ${master}/*.aof ${master}*/.rdb
cp ${DATADIR}/appendonly.aof {${master}}
# 清理后将副本数量至为6
kubectl apply -f Redis-cluster-6.2.5.yaml
run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running")
while [ ${run} -ne 6 ];do run=$(kubectl get pod -n database -l app=redis-cluster-recovery | grep -c "Running");sleep 2;echo -n .; done
echo -e "e[32m[*] Happy,redis-cluster-recovery Pod is Running....e[0m"
kubectl get pod -n database -l app=redis-cluster-recovery
# 9.处理K8s重启redis集群出现的fail问题,我们可以将错误节点剔出集群并重新指定节点信息加入到集群之中
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local --no-auth-warning -a weiyigeek cluster nodes | grep "fail" > /tmp/errnodes.log
# 将该从节点剔出集群
for err in $(cat /tmp/errnodes.log | cut -d " " -f 1);do
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local -a weiyigeek cluster forget ${errid}
done
# 重新将该节点加入集群
for ip in $(kubectl get pods -n database -l app=redis-cluster-recovery -o jsonpath="{range.items[*]}{.status.podIP} "| sed "s# :6379 ##g");do
redis-cli -h -a weiyigeek cluster meet ${ip} 6379
done
# 10.集群状态检测以及重新分配slots卡槽到Master节点
redis-cli -h redisclusterrecovery.database.svc.cluster.local -a weiyigeek --cluster check redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local:6379
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local -a weiyigeek --cluster rebalance --cluster-threshold 1 --cluster-use-empty-masters redis-cluster-recovery-1.redisclusterrecovery.database.svc.cluster.local:6379
# 11.验证分配的slots卡槽到各个Master节点节点信息。
redis-cli -h redisclusterrecovery.database.svc.cluster.local -a weiyigeek --cluster check redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local:6379
# 12.主master节点验证keyspace数据
redis-cli -h redis-cluster-recovery-0.redisclusterrecovery.database.svc.cluster.local -c -a weiyigeek info keyspace
# 13.任何节点访问恢复的数据
redis-cli -h redisclusterrecovery.database.svc.cluster.local -c -a weiyigeek
3.当Redis集群中出现从节点slave,fail,noaddr问题进行处理恢复流程。
- Step 1.利用cluster nodes查看你集群状态,发现其中一个从节点异常(是Fail状态)。
f86464011d9f8ec605857255c0b67cff1e794c19 :0@0 slave,fail,noaddr 2cb35944b4492748a8c739fab63a0e90a56e414a - Step 2.在问题节点上查看节点状态,发现它已脱离集群,且其ID都已发生了变化.
127.0.0.1:6379> cluster nodes0cbf44ef3f9c3a8a473bcd303644388782e5ee78 192.168.109.132:6379@16379 myself,master - 0 0 0 connected 0-5461
Tips : 若id没发生变化,直接重启下该从节点就能解决。
- Step 3.但如果ID与Node IP都发生变化时,此时我们需要将该从节点剔出集群。
# 在集群每个正常节点上执行cluster forget 故障从节点idecho "cluster forget f86464011d9f8ec605857255c0b67cff1e794c19" | /usr/local/bin/redis-cli -a "weiyigeek"
- Step 4.我们重新将该节点加入集群,此时我们只需要 在集群内任意节点上执行
cluster meet命令加入新节点,握手状态会通过信息在集群内传播,这样其他节点会自动发现新节点并发起握手流程。
# 1.使用集群强制联系指定节点(握手)echo "cluster meet 192.168.109.132 6379" | /usr/local/bin/redis-cli -p 6379 -a "密码"
# 2.从节上执行cluster replicate 主节点id( 配置主从关系 )
echo "cluster replicate 2cb35944b4492748a8c739fab63a0e90a56e414a" | /usr/local/bin/redis-cli -p 6383 -a "密码"
- Step 5.最后检测集群是否恢复正常,执行如下命令即可。
echo "cluster nodes" | /usr/local/bin/redis-cli -p 6384 -a "密码"38287a7e715c358b5537a369646e9698a7583459 192.168.109.132:6383@16383 slave 2cb35944b4492748a8c739fab63a0e90a56e414a 0 1615233239757 8 connected
2cb35944b4492748a8c739fab63a0e90a56e414a 192.168.109.133:6383@16383 master - 0 1615233239000 8 connected 0-5461
.......
原文地址: https://blog.weiyigeek.top/2019/4-17-51.html
文章书写不易,如果您觉得这篇文章还不错的,请给这篇专栏 【点个赞、投个币、收个藏、关个注,转个发】(人间五大情),这将对我的肯定,谢谢!。
本文章来源 我的Blog站点 或 WeiyiGeek 公众账号 以及 我的BiliBili专栏 (
技术交流、友链交换请邮我哟),谢谢支持!(๑′ᴗ‵๑) ❤欢迎各位志同道合的朋友一起学习交流,如文章有误请留下您宝贵的知识建议,通过邮箱【master#weiyigeek.top】联系我哟!
以上是 删库到跑路?还得看这篇Redis数据库持久化与企业容灾备份恢复实战指南 的全部内容, 来源链接: utcz.com/z/536416.html