【数据库】优化SQL语言

博客推行版本更新,成果积累制度,已经写过的博客还会再次更新,不断地琢磨,高质量高数量都是要追求的,工匠精神是学习必不可少的精神。因此,大家有何建议欢迎在评论区踊跃发言,你们的支持是我最大的动力,你们敢投,我就敢肝
第1章数据模型设计
第1条:确保所有表都有主键
【1】当表缺少主键时,会出现各种问题,所有表都必须有一列(或多列)设置为主键。
【2】主键应当具备的特征
唯一性,值非空,不可变,尽可能简单
【3】不要使用复合主键,效率太低
定义主键时,大多数数据库会同时强制创建唯一索引
适用主键做连接查询很常见,但是在具有多个列的主键上这样做很复杂,效率也很低
【4】如果不希望非键列出现重复数据,在列上定义唯一索引以保证其完整性。
第2条:避免存储冗余数据
【1】规范化是按照不同的主题将信息分类,以避免冗余数据的存在
【2】冗余是指用户在不同地方输入相同数据的情况
【3】规范化最重要的目标就是最小化数据重复
【4】通过消除冗余数据,避免插入、更新和删除时出现异常
第3条:消除重复数据组
【1】数据库规范化的目标是消除重复的数据组,并尽可能减少表结构的修改
【2】通过删除重复的数据组,可以使用唯一的索引来防止以外的重复数据,并大大简化查询语句
【3】删除重复的数据组使设计更加灵活,因为添加新的数据组只需要加一条记录,而不用修改表设计增加更多的列
第4条:每列只存储一个属性
【1】正确的表设计师为每个分配单独的列,当列包含多个属性时,搜索和分组即使有可能做,也会是极其困难的
【2】对于某些应用程序,有过滤列中的某部分数据的需求,这可能会决定列的粒度级别
【3】当需要重新把属性组合成报表或打印清单时,适用连接
第5条:理解为什么存储计算列通常有害无益
【1】如果这个表用于大型在线数据录入系统,创建计算列可能会对服务器造成巨大的负载,从而影响服务器的响应时间
【2】许多数据库系统允许你在创建表时定义计算类,但应该主义性能影响,特别是在适用非确定性表达式或函数的时候
【3】你还可以像定义普通列一样定义计算列,然后适用触发器来维护,但是编写触发器的代码可能会很复杂
【4】计算列会对数据库系统产生额外的开销,只有当利大于弊时候才考虑适用它
【5】大多数情况下,你希望在计算列上创建一个索引,以小号更多的存储空间和搅蛮的更新作为交换,获得一些便利性
【6】当不能使用索引时,使用视图来做计算通常可以作为在表里创建计算列的计算方法
第6条:定义外键以确保引用完整性
【1】正确地设计数据库时,在许多表中都会包含应用相关父表主键的外键
【2】外键明显有助于保证相关表之间的数据完整性,确保子表的记录能在父表找到对应的记录
【3】如果表中存在违反约束的数据,向表中添加FOREIGN KEY约束将失败
【4】在某些数据库系统中,定义FOREIGN KEY约束将会最懂创建索引,这样可以提高连接查询的性能。在其他一些数据库系统中,创建索引来覆盖FOREIGN KEY约束必须小心。即使没有索引,一些数据库系统优化器也会特别对待这些列,以提供更好的查询效率
第7条:确保表间关系的合理性
【1】再三斟酌,为了简化关系模型而合并包含相似字段的表是否真的有意义
【2】只要对应列数据类型匹配【或可以隐式地强制转换】,就可以在两个表之间创建连接,但只有当列当属于同一个业务领域时,关系才是有效的。所以,最理想的连接是两端都具有相同的数据类型和业务领域
【3】在建模之前,检查你处理的数据是否是结构化数据。如果是半结构化的,则要做特殊的处理
【4】明确数据模型的目标通常有助于判断给定的设计是否由于简化关系模型和适用此数据模型应用程序的设计导致了复杂性或异常的增加
第8条:当第三范式不够时,采用更多范式
【1】判断一个设计遵循第三范式但可能违反更高范式的警告标志是,看一个表是否与其他多个表关联,特别是当表参与了多个多对多的关系时。
【2】另一个判断方法是,如果表包含复合键就有可能违反较高的范式。
【3】前三个范式关注关系中属性之间的功能依赖,功能依赖是指属性依赖于关系中的键。
【4】对于四个范式,我们关注的是多值依赖,是两个彼此独立的属性同时依赖关系中同一个键的情况
【5】大多数数据模型已经满足了较高的范式。因此,只需要注意某些明显违反高级范式的情况
【6】第四范式只有在某些特殊的情况下才会违反
【7】第五范式要求候选键可推导出所有连接依赖,意味着你应该能够基于各个属性来约束候选键的有效值。这种情况只发生在复合键上
【8】第六范式是将表的关系减少到只存在一个非关键属性,这样会导致表的数量膨胀,但是可以避免出现空值的列
【9】无损分解是检测表是否违反较高范式的一个有效工具
第9条:非规范化数据仓库
【1】规范化的表通常比非规范化的表更小且占用的空间更少
【2】数据被拆分成多个小表,小到足以存在缓存中,性能通常也更好
【3】想清楚要复制的数据及原因
【4】计划如何保持数据同步
【5】适用非规范化字段重构查询
第2章可编程性与索引设计
第10条:创建索引时空值的影响
【1】null是关系数据库中的特殊值,表示列位置或数据确实。
【2】null永远不能等于或不等于另一个值,甚至是另一个null也不行
【3】要检测是否存在null值,必须适用IS NULL条件
【4】创建索引时考虑列是否包含空值
【5】如果要搜索空值,但列中的大多数值都可能为NULL,那么最好不要对列进行索引。这也可能表明表需要重新设计
【6】如果希望更快地对列进行搜索,但列中大多数值为NULL,具有数据库支持的话,可以创建排除空值的索引
【7】每种数据库处理索引中空值的方法都不同。在为可能包含空值的列上创建索引时,确保了解数据库系统的选项
第11条:创建索引时谨慎考虑以最小化索引和数据扫描
【1】尽管加大硬件的投资可以提高性能,但是优化查询通常可以以更低成本的方式获得更好的效果
【2】导致性能问题常见的原因是缺少索引或者设置了错误的索引,这会导致数据库引擎必须处理更多的数据来查找符合条件的记录。这些问题通常被称为索引扫描和表扫描
【3】当数据库引擎需要通过扫描索引或者数据块来能找到相应的记录时,就需要索引扫描或表扫描
【4】分析数据,创建正确的索引以提高性能
【5】确保创建的索引都被使用
第12条:索引不只是过滤
【1】数据库索引在数据库中拥有独特的数据结构
【2】由于索引会复制已索引表的数据,所以每个索引都有属于自己的磁盘空间,所以索引时纯冗余的,但这种冗余是可以接受的
【3】因为索引不需要在每次查询中索引表中的每一个行,可以快速定位数据提高数据检索操作的速度
【4】WHERE子句中的列是否包含在索引中会查询的性能产生影响,一个写的很差的WHERE字句是缓慢查询的罪魁祸首
【5】SELECT子句中的列是否被索引也会影响查询的效率
【6】连接查询的列是否被索引可能会影响查询的效率
第13条:不要过度使用触发
【1】创建表时,因为使用约束提供的DRI以及内置功能创建的计算列,性能通常会更好,所以我们建议将约束或创建计算列的内置功能作为默认解决方案
【2】触发器通常不可移植:一个数据库系统的触发器,在不做修改的情况下,很难在另一个数据库系统中运行
【3】仅在绝对必要时才使用触发器。如果可能,确保触发器是幂等的
第14条:使用过滤索引包含或排除数据子集
【1】过滤索引进队少部分行有用,可节省空间
【2】过滤索引可用于对行自己执行为以约束
【3】过滤索引可避免排序操作
【4】考虑是否需要分区表来提供类似过滤索引的功能,从而避免维护一个索引的成本
第15条:使用声明式约束替代编码校验
【1】考虑使用约束来枪支数据完整性
【2】查询优化器可以使用约束定义来构建高性能查询执行计划
第16条:了解数据库使用的SQL方言并编写相应的
【1】即使一条语句可能复合SQL标准,也可能无法在你的DBMS中使用
【2】由于不同的DBMS以不同方式执行,相同的SQL语句在性能上的表现也会不同
第17条:了解何时在索引中使用计算结果
【1】不要过度使用索引
【2】分析数据库预期的使用情况,以确保过滤索引仅在真正有意义的地方使用
第3章 当你不能改变设计时
第18条:使用视图来简化不能更改的
【1】视图是一种让用户创建自然或至关的结构化数据的方式
【2】使用视图来限制对数据的访问,限制用户尽可以看到【有时候可以修改】他们所需要的数据
【3】使用视图来隐藏和重用复杂的查询
【4】视图可从各种表中汇总用于生成报告的数据
【5】使用视图实现和强制命名及编码标准,特别是在需要更新旧数据库的结构时
第19条:使用ETL将非关系数据转换为有用的信息
【1】ETL工具让你能更容易并非关系数据导入到数据库中
【2】ETL工具可帮助你重新格式化并重新排列导入的数据,以便将其转换为有用的信息
【3】大多数数据库系统中提供了某些勒死的ETL工具,也有一些商业工具可用
第20条:创建汇总表并维护
【1】存储汇总数据可以帮助最小化聚合流程
【2】使用表存储汇总数据后,可以索引包含聚合数据的字段,以便更有效地查询汇总数据
【3】汇总对于几乎静态的表效果最好。如果原表变化太频繁,则汇总的开销可能太大
【4】触发器可用于执行汇总,但重建汇总表的存储过程通常更好
第21条:使用UNION语句将非规范化数据列转行
【1】UNION查询中的每个SELECT语句必须具有相同数量的列
【2】尽管SELECT语句的列名并不重要,但每列的数据类型必须兼容
【3】要控制数据出现的顺序,可以再最后一个SELECT语句之后使用ORDER BY子句
【4】如果你不希望消除重复行或能够承受移除重复行带来的性能损失,请使用UNION ALL替代UNION
第4章过滤与查找数据
第22条:了解关系代数及其如何在SQL实理
【1】关系模型定义了你可以再集合上执行的8个操作
【2】所有主流的SQL实现都支持选择、投影、连接、笛卡尔积和并集
【3】一些SQL的实现使用INTERSECT和EXCEPT或MINUS关键字支持交集和差集
【4】实现SQL的主流数据库系统都不支持除操作,但可以通过SQL的其他操作得到相同的结果
第23条:查找不匹配或缺失的记
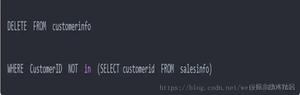
【1】虽然易于理解,但使用NOT IN运算符通常不是最有效的办法
【2】使用NOT EXISTS操作符通常比使用NOT IN运算符更快
【3】使用无效连接通常是非常有效的,但这取决于DBMS如何处理空值
【4】使用DBMS查询分析器来确定哪种方式最适合你的具体情况
第24条:了解何时使用CASE解决问题
【1】当你需要解决IF...THEN...ELSE这类问题时,CASE是一个强大的工具
【2】你可以使用简单的CASE来执行相等判断和基于搜索的CASE以使用复杂的条件
【3】可以使用表达式的地方都可以使用CASE,包括作为SELECT子句的列定义或作为WHERE或HAVING子句条件的一部分
第25条:了解解决多条件查询的技术
【1】需要通过关联表或多个表判断多个条件才能解决问题,通常都比较复杂
【2】当父表查询需要在其一个或多个子表的相应记录满足多个条件时才能翻会记录,必须在表子查询中使用INNER JOIN或OUTER JOIN并结合空值判断,或者或者在表子查询中使用IN和AND或NOT IN和OR才能得到正确的结果
第26条:如需完美匹配,先对数据进行除操作
【1】除是8个公认的关系集操作之一,但SQL标准和主流数据库系统都不支持DIVIDE关键字
【2】你可以使用除来查找一组数据中匹配另一组数据所有记录的记录
【3】你可以通过测试除数集中的每一行、NOT EXISTS和GROUP BY或HAVING来执行除操作
第27条:如何按时间范围正确地过滤日期和时间的列
【1】不要依赖隐式日期转换;使用显式转换函数来处理日期字符
【2】不要将函数应用于日期和时间列,否则查询将不能使用索引
【3】摄入误差可能导致日期和时间值不正确;使用>=和<替代BETWEEN
第28条:书写可参数化搜索的查询以确保引擎使用索引
【1】避免使用不可参数化搜索的操作符
【2】不要再WHERE子句中的一个或多个字段上使用函数
【3】不要对WHERE子句的字段进行算数运算
【4】使用LIKE操作符时,只能在字符串末尾使用通配符【不是‘%something’或‘some%thing’】
第29条:正确地定义“左”连接的“右”侧
【1】在SQL中使用OUTER JOIN执行差集操作
【2】当你对外部WHERE子句中的左连接加入右侧数据使用过滤时,你将无法获得所需的结果,反之亦然
【3】要正确地过滤数据自己,必须在数据库系统执行外连接之前使用过滤
第5章聚合
第30条:理解GROUPBY的工作原理
【1】聚合在执行WHERE子句之后完成
【2】GROUP BY子句聚合过滤后的数据集
【3】HAVING子句过滤聚合后的数据集
【4】ORDER BY子句对变换后的数据集进行排序
【5】在SELECT子句中没有使用聚合函数或计算的任何列必须同时出现在GROUP BY子句中
【6】使用ROLLUP、CUBE和GROUPING SETS可以在单个查询中提供更多可能的组合、以代替创建多个聚合查询,然后再将其合并
第31条:简化GROUP BY子句
【1】某些DMBS要求将非聚合的列也添加到GROUP BY,即使当前的SQL标准不再需要这么做
【2】GROUP BY中的列过多可能会对查询的性能产生负面影响、也会使阅读、理解和重写变得困难
【3】对于同时需要聚合和详细信息的查询,首先在子查询中执行所有聚合,然后将结果再连接到其他表以查询详细信息
第32条:利用GROUP BY或HAVING解决复杂的问题
【1】在分组之前使用WHERE子句过滤记录,分组后使用HAVING过滤记录
【2】HAVING子句可以过滤聚合表达式
【3】即使你在SELECT子句中已给聚合表达式明明,如果要在HAVING子句中使用表达式,必须重写该表达式。不能重用SELECT中的名称。
【4】可以将简单文字的聚合值与复杂子查询聚合返回的值进行比较
第33条:避免使用GROUP BY来查找最大值或最小值
【1】主表连接到自身需要使用LEFT JOIN
【2】将GROUP BY子句中的每一列都变成ON 子句的一部分,并使用相等=进行比较
【3】MAX()或MIN()子句中的列将成为ON子句的一部分,并且使用<或>
【4】应该为ON子句中的列添加索引,以过的更好的性能,特别是针对较大的数据集时
第34条:使用OUTER JOIN时避免获取错误的COUNT()
【1】使用COUNT(*)来统计所有记录的总数,也包括空值的记录
【2】使用COUNT()仅统计列值不为NULL的记录的总数
【3】有时一个子查询甚至一个相关的子查询,也会比使用GROUP BY有效率
第35条:测试HAVING COUNT(x) <某数时包含零值记录
【1】使用INNER JOIN不能找出零计数
【2】过滤左连接的右侧,将获得相当于内连接的结果。将过滤器移入子查询或在ON条件中过滤右侧
【3】当想大于1的总计数时,寻找零计数可以帮助你识别数据中的问题
第36条:使用DISTINCT获取不重复的计数
【1】使用COUNT()函数适当的方式来简化计算
【2】可以考虑使用函数作为COUNT()函数的参数,以便不需要使用WHERE子句就能执行组合计算
第37条:知道如何使用窗口函数
【1】窗口函数感知周围的行,这使得创建运行或移动聚合比传统的聚合函数和语句级分组更容易
【2】窗口函数是更需要对不同的或独立的数据应用聚合的理想选择
【3】窗口函数可以与现有的聚合函数一起使用,并通过包含OVER子句来启用
【4】PARTITION BY谓词可用于制定必须将该分组应用于聚合表达式
【5】ORDER BY谓词通常很重要,因为它影响后续行将如何计算其聚合表达式
第38条:创建行号与排名
【1】必须始终对ROW_NUMBER()、RANK()和其他排序函数进行窗口化,因此必须与相应的OVER子句一起出现
【2】考虑如何使用排序函数处理关联。如果你需要连续排名,应该使用DENSE_RANK()
【3】ORDER BY谓词对于这类函数是强制性的,因为它会影响结果如何排序
第39条:创建可移动聚合函
【1】无论如何需要将窗口框架的边界更改为非默认设置,即使可选,也必须指定ORDER BY谓词
【2】如果需要为窗口框架定义任意大小,则必须使用ROWS,这样可以输入需要包含在窗口框架中的前后几行
【3】RANGE只能接受UNBOUNDED PRECEDING、CURRENT ROW或UNBOUNDED FOLLOWING作为有效选项
【4】你可以选择RANGE逻辑分组行货ROWS物理偏移行。如果ORDER BY谓词不返回重复值,则两者结果是等效的
第6章 子查询
第40条:了解在何处使用子查询
【1】你可以在任何使用表、视图或能够返回表的函数或过程的位置使用表子查询
【2】你可以在任何使用表子查询和需要为IN或NOT IN条件提供一个列表的位置,使用返回单列的表子查询
【3】你可以在任何使用列名的位置使用标量子查询,如在一个SELECT语句中,或在一个SELECT语句的表达式,或作为比较条件的一部分
第41条:了解关联和非关联子查询的差异
【1】关联子查询在WHERE或HAVING子句中使用一个应用,该应用依赖于潜入子查询的查询返回值
【2】非关联子查询不依赖于外部查询,并且可以独立执行
【3】通常,你可以使用非关联子查询,为FROM子句提供已过滤的数据集,或作为IN条件的单列数据集,或作为在WHERE或HAVING子句中为比较条件返回的标量值
【4】你可以使用关联子查询,为SELECT子句返回标量值,在WHERE或HAVING子句中为比较条件提供单个值进行测试,或者在EXISTS子句中提供用于存在性检验的数据集合
【5】关联子查询不一定比其他方法慢,但它可能是返回正确结果的唯一方法
第42条:尽可能使用公共表表达式而不是子查询
【1】利用公用表表达式【CTE】,你可以简化多次使用相同子查询的复杂查询
【2】CTE可以免除使用可能无意中更改的功能,而这样的修改会导致使用该函数的查询无法正常工作
【3】在同一SQL中,CTE允许你直接定义要嵌入到另一个查询中的子查询,这样做也更容易理解
【4】虽然你可以使用递归CTE生成一些数据值,这些值在计数表中找到,但保存的基数表效率更高,因为你可以对其添加索引
【5】你可以使用递归CTE遍历层次关系,并以有意义的方式进行展示
第43条:使用连接而非子查询创建更高效的查询
【1】不要认为按顺序解决问题是首选方法。SQL语句最适合按集合,而不是按行运行
【2】了解DBMS优化器多种处理方式的特性,从而决定首选的解决方案
【3】确保为任何链接都建立了适当的索引
第7章 获取与分析元数据
第44条:了解如何使用系统的查询分析器
【1】执行计划中显示地信息可能会随时间而变化
【2】DB2要求先创建系统表。它将执行计划存储在这些系统表中,而不是显示它们。它会产生预估的计划
第45条:学习获取数据库的元数据
【1】尽可能使用SQL标准的INFORMATION_SCHEMA视图
【2】INFORMATION_SCHEMA在DBMS之间并不完全一样
第46条:理解执行计划的工作原理
【1】每当你阅读执行计划时,将其转换为实际步骤,分析是否存在未使用的索引,并确定其未被使用的原因
【2】分析各个步骤,并判断它们是否有效。请注意,效率受数据分部的影响。因此没有所谓的“坏”操作,而是分析所使用的的操作是否适合正在使用的查询
【3】不要因为一个查询就加上索引来改善执行计划,你必须从数据库出发全盘考虑以确保索引尽可能的通用
【4】注意大与小情况,其中数据分布不均的数据对同一个查询会需要不同的优化。当执行计划被缓存和重用时,这个问题就特别严重
第8章 笛卡儿积
第47条:生成两张表所有行的组合并标示一张表中间接关联另一张表的列
【1】使用笛卡尔积产生两个表之间的各种组合
【2】使用INNER JOIN确定实际发生的组合
【3】使用LEFT JOIN将笛卡尔积的结果与实际发生的组合列表进行比较
【4】你还可以使用SELECT子句中CASE语句中的IN子查询来产生于使用笛卡尔积及LEFT JOIN相同的结果,但性能取决于数据流、索引和特定DBMS
第48条:理解如何以等分量排名
【1】将等分数据分成排名区间是评估信息有趣有用的方式
【2】使用RANK()窗口函数轻松创建排名值
【3】将1除以分区数以产生每个分区的乘数
第49条:知道如何对表中的行配对
【1】找出从N个项目中取出K个项目的排列组合很有用
【2】有独特列时找出排列组合很容易
【3】要增加每个组合选择的项目数量时,只需将目标表的另一个副本添加到查询中即可
【4】操作大量数据时要小心,因为最终可能产生成百上千亿行
第50条:理解如何列出类别与前三偏好
【1】除运算可找出完全匹配
【2】如果接受部分匹配,则需要套用其他技巧
【3】表中有排名的数据可以帮助你决定最佳的匹配
第9章计数表
第51条:根据计数表内定义的参数生成空行
【1】生成空白行可能是有用的,特别是对于报表
【2】你可以使用递归CTE或技术表来帮助你生成空行。在某些情况下,直接使用表可能会更快
【3】为了方便为空行数提供参数值,创建一个接收参数的函数,以便你可以从SELECT语句中调用它
第52条:使用计数表和窗口函数生成序列
【1】计数表可以与窗口函数一起使用,以提供更多的序列或其他需要以窗口描述的方式
【2】非等式连接与计数表在需要凭空产生记录时很有用
第53条:根据计数表内定义的范围生成行
【1】使用计数表产生数据库中没有的值
【2】当计数表包含一个范围的值时,你可以比较此范围与现有数据以产生相对值
【3】你可以使用序列计数表根据另一个计数表的值生成行
第54条:根据计数表定义的值范围转换某个表中的值
【1】确保你的转换计数表符合你的数据设计
【2】确保非等式中使用的不等式适用于正在使用的计数表
第55条:使用日期表简化日期计算
【1】对于日期与日期运算密集的应用程序,日期表可大幅简化逻辑
【2】日期表可加入工作日、假日或财年等特定应用领域
【3】由于日期表基本上是个维度表,因此即使是在线交易处理数据库也可以大量创建索引。如果可能,将表明确地存储在内存中能够避免磁盘存取并改善优化器的判断
第56条:创建在某个范围内所有日期的日程表
【1】确保你的日期表有适当的索引
【2】确保WHERE子句从适当的表中测试值
第57条:使用计数表行转列
【1】需要行转列数据时,你的数据库系统可能有专属的语法
【2】若只想要使用标准SQL,你可以使用CASE表达式对数据进行行列转换,以提供聚合函数中每行需要的值
第10章 层次数据建模
第58条:从邻接列表模型开始
【1】邻接列表只是在表中添加一个自引用表的主键的一个外键。不需要元数据
【2】始终使用邻接列表模型构建一致的层次模型
第59条:对不常更新的数据使用嵌套集以提升查询性能
【1】你必须使用存储过程来维护嵌套集模型,以封装构建集合后的逻辑,并为每个节点分配正确的左和右数字。
【2】嵌套集模型不适用于频繁更新的情况,因为对层次结构的更改需要对其他几个节点进行重新编号,可能是整个表,这可能会导致死锁。
【3】获取计数不需要查找其他记录,因为它可以从lft和rgt元数据列计算,使得嵌套集模型对于维护统计信息非常有效。
【4】嵌套集模型只能使用单个根节点的单个层次结构。如果你需要多个层次结构,多个根节点,请考虑其他模型。
第60条:使用存储路径简化设置与搜索
【1】存储路径的好处是容易理解与处理,因为它基于我们都熟悉的文件系统路径。
【2】设计的限制很难发现,因为没有简单的方法预知层次结构是否太深或太宽而超过索引的限制。因此你必须对层次结构加上限制以避免产生问题。
【3】存储路径的搜索仅在一个方向上有效,因为在开始或谓词中有通配符时不能创建可搜索的查询。设计时要考虑这一点。
第61条:使用祖先遍历闭包做复杂搜索
【1】当你需要频繁更新和易于搜索时,使用祖先遍历闭包模型,但代价是维护祖先表的额外复杂性。
【2】虽然比较规范化,但是不能将祖先表中的元数据保持为最新,可能导致查询结果不正确。这可以通过在Employees表上使用触发器来自动修改祖先表来缓解,但需要付出一定的成本。
在黑夜里梦想着光,心中覆盖悲伤,在悲伤里忍受孤独,空守一丝温暖。
我的泪水是无底深海,对你的爱已无言,相信无尽的力量,那是真爱永在。
我的信仰是无底深海,澎湃着心中火焰,燃烧无尽的力量,那是忠诚永在
以上是 【数据库】优化SQL语言 的全部内容, 来源链接: utcz.com/z/536358.html