Kafka连接器建立数据管道

1.概述
最近,有同学留言咨询Kafka连接器的相关内容,今天笔者给大家分享一下Kafka连接器建立数据管道的相关内容。
2.内容
Kafka连接器是一种用于Kafka系统和其他系统之间进行功能扩展、数据传输的工具。通过Kafka连接器能够简单、快速的将大量数据集移入到Kafka系统,或者从Kafka系统中移出,例如Kafka连接器可以低延时的将数据库或者应用服务器中的指标数据收集到Kafka系统主题中。
另外,Kafka连接器可以通过作业导出的方式,将Kafka系统主题传输到二次存储和查询系统中,或者传输到批处理系统中进行离线分析。
2.1 使用场景
Kafka连接器通常用来构建数据管道,一般来说有两种使用场景。
1. 开始和结束的端点
第一种,将Kafka系统作为数据管道的开始和结束的端点。例如,将Kafka系统主题中的数据移出到HBase数据库,或者把Oracle数据库中的数据移入到Kafka系统。
2. 数据传输的中间介质
第二种,把Kafka系统作为一个中间传输介质。例如,为了把海量日志数据存储到ElasticSearch中,可以先把这些日志数据传输到Kafka系统中,然后再从Kafka系统中将这些数据移出到ElasticSearch进行存储。
ElasticSearch是一个基于Lucene(Lucene是一款高性能、可扩展的信息检索工具库)实现的存储介质。它提供了一个分布式多用户能力的全文搜索引擎,基RESTful(一种软件架构风格、设计风格,但是并非标准,只是提供了一组设计原则和约束条件)接口实现。
Kafka连接器的存在,给数据管道带来很重要的价值。例如,Kafka连接器可以作为数据管道各个数据阶段的缓冲区,有效的将消费者实例和生产者实例进行解耦。
Kafka系统解除耦合的能力、系统的安全性、数据处理的效率等方面均表现不俗,因而使用Kafka连接器来构建数据管道是一个最佳的选举。
2.2 特性和优势
Kafka连接器包含一些重要的特性,并且给数据管道提供了一个成熟稳定的框架。同时,Kafka连接器还提供了一些简单易用的工具库,大大降低的开发人员的研发成本。
1. 特性
Kafka连接器具体包含的特性如下。
- 通用框架:Kafka连接器制定了一种标准,用来约束Kafka系统与其他系统集成,简化了Kafka连接器的开发、部署和管理;
- 单机模式和分布式模式:Kafka连接器支持两种模式,既能扩展到支持大型集群的服务管理,也可以缩小到开发、测试等小规模的集群;
- REST接口:使用REST API来提交请求并管理Kafka集群;
- 自动管理偏移量:通过连接器的少量信息,Kafka连接器可以自动管理偏移量;
- 分布式和可扩展:Kafka连接器是建立在现有的组管理协议上,通过添加更多的连接器实例来水平扩展,实现分布式服务;
- 数据流和批量集成:利用Kafka系统已有的能力,Kafka连接器是桥接数据流和批处理系统的一种理想的解决方案。
2. 优势
在Kafka连接器中有两个核心的概念,它们分别是Source和Sink。其中Source负责将数据导入到Kafka系统,而Sink则负责将数据从Kafka系统中进行导出。
Source和Sink在实现数据导入和导出的过程被称之连接器,即Source连接器和Sink连接器。这两种连接器提供了对业务层面数据读取和写入的抽象接口,简化了生命周期的管理工作。
在处理数据时,Source连接器和Sink连接器会初始化各自的任务,并将数据结构进行标准化的封装。在实际应用场景中,不同的业务中的数据格式是不一样的,因此,Kafka连接器通过注册数据结构,来解决数据格式验证和兼容性问题。
当数据源发生变化时,Kafka连接器会生成新的数据结构,通过不同的处理策略来完成对数据格式的兼容。
2.3 核心概念
在Kafka连接器中存在几个核心的概念,它们分别是连接器实例(Connectors)、任务数(Tasks)、事件线程数(Workers)、转换器(Converters)。
1. 连机器实例
在Kafka连接器中,连接器实例决定了消息数据的流向,即消息数据从何处复制,以及将复制的消息数据写入到何处。
一个连接器实例负责Kafka系统与其他系统之间的逻辑处理,连接器实例通常以JAR包的形式存在,通过实现Kafka系统应用接口来完成。
2. 任务数
在分布式模式下,每一个连接器实例可以将一个作业切分成多个任务(Task),然后再将任务分发到各个事件线程(Worker)中去执行。任务不会保存当前的状态信息,通常由特定的Kafka主题来保存,例如指定具体属性offset.storage.topic和status.storage.topic的值来保存。
在分布式模式中,会存在任务均衡的概念。当一个连接器实例首次提交到Kafka集群,所有的事件线程都会做一个任务均衡的操作,来保证每一个事件线程都运行差不多数量的任务,避免所有任务集中到某一个事件线程。
3. 事件线程
在Kafka系统中,连接器实例和任务数都是逻辑层面的,需要有具体的线程来执行。在Kafka连接器中,事件线程就是用来执行具体的任务,事件线程包含两种,分别是单机模式和分布式模式。
4. 转换器
转换器会将字节数据转换成Kafka连接器内部的格式,同时,也能将Kafka连接器内部存储的数据格式转换成字节数据。
3.操作连接器
连接器作为Kafka的一部分,随着Kafka系统一起发布,所以无需独立安装。在大数据应用场景下,建议在每台物理机上安装一个Kafka。根据实际需求,可以在一部分物理机上启动Kafka实例(即代理节点Broker),在另一部分物理机上启动连接器。
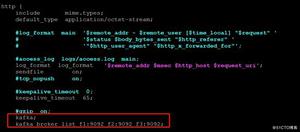
在Kafka系统中,Kafka连接器最终是以一个常驻进程的形式运行在后台服务中,它提供了一个用来管理连接器实例的REST API。默认情况下,服务端口地址是8083。
提示:Representational State Transfer,简称REST,即表现层状态转移。REST是所有Web应用程序都应用遵守的一种规范。符合REST设计规范的应用接口,即REST API。
在Kafka连接器中,REST API支持获取、写入、创建等接口,具体内容如下图所示:
在Kafka系统中,Kafka连接器目前支持两种运行模式,它们分别是单机模式和分布式模式。
3.1 单击模式导入
在单机模式下,所有的事件线程都在一个单进程中运行。单机模式使用起来更加简单,特别是在开发和定位分析问题的时候,使用单机模式会比较适合。
(1)编辑单机模式配置文件。
在单机模式下,主题的偏移量是存储在/tmp/connect.offsets目录下,在$KAFKA_HOME/config目录下有一个connect-standalone.properties文件,通过设置offset.storage.file.filename属性值来改变存储路径。
每次Kafka连接器启动时,通过加载$KAFKA_HOME/config/connect-file-source.properties配置文件中的name属性来获取主题的偏移量,然后执行后续的读写操作。
# 设置连接器名称name
=local-file-source# 指定连接器类
connector.class
=FileStreamSource# 设置最大任务数
tasks.max
=1# 指定读取的文件
file=/tmp/test.txt# 指定主题名
topic
=connect_test
(2)在即将读取的文件中,添加数据,具体操作命令如下。
# 新建一个test.txt文件并添加数据
[hadoop@dn1 ~]$ vi /tmp/test.txt
# 添加内容如下kafka
hadoop
kafka
-connect# 保存并退出
在使用Kafka文件连接器时,连接器实例会监听配置的数据文件,如果文件中有数据更新,例如:追加新的消息数据。连接器实例会及时处理新增的消息数据。
(3)启动Kafka连接器单机模式的命令与启动Kafka代理节点类似,具体操作命令如下。
# 启动一个单机模式的连接器[hadoop@dn1 bin]$ .
/connect-standalone.sh ../config/connect-standalone.properties..
/config/connect-file-source.properties
(4)使用Kafka系统命令查看导入到主题(connect_test)中的数据,具体操作命令如下。
# 使用Kafka命令查看[hadoop@dn1 bin]$ .
/kafka-console-consumer.sh --zookeeper dn1:2181 --topic connect_test--from-beginning
3.2 分布式模式导入
在分布式模式中,Kafka连接器会自动均衡每个事件线程所处理的任务数。允许用户动态的增加或者减少,在执行任务、修改配置、以及提交偏移量时能够得到容错保障。
在分布式模式中,Kafka连接器会在主题中存储偏移量、配置、以及任务状态。建议手动创建存储偏移量的主题,可以按需设置主题分区数和副本数。
需要注意的是,除了配置一些通用的属性之外,还需要配置以下几个重要的属性。
- group.id(默认值connect-cluster):连接器组唯一名称,切记不能和消费者组名称冲突;
- config.storage.topic(默认值connect-configs):用来存储连接器实例和任务配置,需要注意的是,该主题应该以单分区多副本的形式存在,建议手动创建,如果自动创建可能会存在多个分区;
- offset.storage.topic(默认值connect-offsets):用来存储偏移量,该主题应该以多分区多副本的形式存在;
- status.storage.topic(默认值connect-status):用来存储任务状态,该主题建议以多分区多副本的形式存在。
在分布式模式中,Kafka连接器配置文件不能使用命令行,需要使用REST API来执行创建、修改和销毁Kafka连接器操作。
(1)编辑分布式模式配置文件(connect-distributed.properties)
# 设置Kafka集群地址bootstrap.servers
=dn1:9092,dn2:9092,dn3:9092# 设置连接器唯一组名称
group.
id=connect-cluster# 指定键值对JSON转换器类
key.converter
=org.apache.kafka.connect.json.JsonConvertervalue.converter
=org.apache.kafka.connect.json.JsonConverter# 启用键值对转换器
key.converter.schemas.enable
=truevalue.converter.schemas.enable
=true# 设置内部键值对转换器, 例如偏移量、配置等
internal.key.converter
=org.apache.kafka.connect.json.JsonConverterinternal.value.converter
=org.apache.kafka.connect.json.JsonConverterinternal.key.converter.schemas.enable
=falseinternal.value.converter.schemas.enable
=false# 设置偏移量存储主题
offset.storage.topic
=connect_offsets# 设置配置存储主题
config.storage.topic
=connect_configs# 设置任务状态存储主题
status.storage.topic
=connect_status# 设置偏移量持久化时间间隔
offset.flush.interval.ms
=10000
(2)创建偏移量、配置、以及任务状态主题,具体操作命令如下。
# 创建配置主题kafka
-topics.sh --create --zookeeper dn1:2181 --replication-factor 3 --partitions 1--topic connect_configs# 创建偏移量主题
kafka
-topics.sh --create --zookeeper dn1:2181 --replication-factor 3 --partitions 6--topic connect_offsets# 创建任务状态主题
kafka
-topics.sh --create --zookeeper dn1:2181 --replication-factor 3 --partitions 6--topic connect_status
(3)启动分布式模式连接器,具体操作命令如下。
# 启动分布式模式连接器[hadoop@dn1 bin]$ .
/connect-distributed.sh ../config/connect-distributed.properties
(4)执行REST API命令查看当前Kafka连接器的版本号,具体操作命令如下。
# 查看连接器版本号[hadoop@dn1
~]$ curl http://dn1:8083/
(5)查看当前已安装的连接器插件,通过浏览器访问http://dn1:8083/connector-plugins地址来查看
(6)创建一个新的连接器实例,具体操作命令如下。
# 创建一个新的连接器实例[hadoop@dn1
~]$ curl "http://dn1:8083/connectors" -X POST -i –H"Content-Type:application/json" -d "{"name":"distributed-console-source","config":{"connector.class":"org.apache.kafka.connect.file.FileStreamSourceConnector",
"tasks.max":"1","topic":"distributed_connect_test",
"file":"/tmp/distributed_test.txt"}}"
然后在浏览器访问http://dn1:8083/connectors地址查看当前成功创建的连接器实例名称,如下图所示:
(7)查看使用分布式模式导入到主题(distributed_connect_test)中的数据,具体操作命令如下。
# 在文件/tmp/distributed_test.txt中添加消息数据[hadoop@dn1
~]$ vi /tmp/distributed_test.txt# 添加如下内容(这条注释不要写入到distributed_test.txt文件中)
distributed_kafka
kafka_connection
kafka
hadoop
# 然后保存并退出(这条注释不要写入到distributed_test.txt文件中)
# 使用Kafka系统命令,查看主题distributed_connect_test中的数据
[hadoop@dn1
~]$ kafka-console-consumer.sh --zookeeper dn1:2181 –topicdistributed_connect_test
--from-beginning
4.总结
Kafka 连接器可以从DB存储或应用程序服务器收集数据到Topic,使数据可用于低延迟的流处理。导出作业可以将数据从Topic传输到二次存储和查询系统,或者传递到批处理系统以便进行离线分析。
5.结束语
这篇博客就和大家分享到这里,如果大家在研究学习的过程当中有什么问题,可以加群进行讨论或发送邮件给我,我会尽我所能为您解答,与君共勉!
另外,博主出书了《Kafka并不难学》和《Hadoop大数据挖掘从入门到进阶实战》,喜欢的朋友或同学, 可以在公告栏那里点击购买链接购买博主的书进行学习,在此感谢大家的支持。关注下面公众号,根据提示,可免费获取书籍的教学视频。
TRANSLATE with x
English
Arabic
Hebrew
Polish
Bulgarian
Hindi
Portuguese
Catalan
Hmong Daw
Romanian
Chinese Simplified
Hungarian
Russian
Chinese Traditional
Indonesian
Slovak
Czech
Italian
Slovenian
Danish
Japanese
Spanish
Dutch
Klingon
Swedish
English
Korean
Thai
Estonian
Latvian
Turkish
Finnish
Lithuanian
Ukrainian
French
Malay
Urdu
German
Maltese
Vietnamese
Greek
Norwegian
Welsh
Haitian Creole
Persian
TRANSLATE with
EMBED THE SNIPPET BELOW IN YOUR SITE
Enable collaborative features and customize widget: Bing Webmaster Portal
Back
联系方式:
邮箱:smartloli.org@gmail.com
Twitter:https://twitter.com/smartloli
QQ群(Hadoop - 交流社区1):424769183
QQ群(Kafka并不难学): 825943084
温馨提示:请大家加群的时候写上加群理由(姓名+公司/学校),方便管理员审核,谢谢!
热爱生活,享受编程,与君共勉!
公众号:
作者:哥不是小萝莉 [关于我][犒赏]
出处:http://www.cnblogs.com/smartloli/
转载请注明出处,谢谢合作!
以上是 Kafka连接器建立数据管道 的全部内容, 来源链接: utcz.com/z/536134.html