Zookeeper选举机制(重点)

前言
半数机制(Paxos 协议):集群中半数以上机器存活,集群可用。所以zookeeper适合装在奇数台机器上。
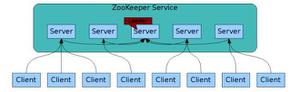
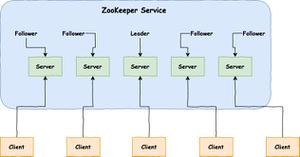
Zookeeper虽然在配置文件中并没有指定master和slave。但是,zookeeper工作时,是有一个节点为leader,其他则为follower,Leader是通过内部的选举机制临时产生的
第一次启动选举机制
假设有五台服务器组成的zookeeper集群,它们的id从1-5,同时它们都是最新启动的,也就是没有历史数据,在存放数据量这一点上,都是一样的。假设这些服务器依序启动,来看看会发生什么。
(1)服务器1启动,此时只有它一台服务器启动了,它发出去的报没有任何响应,所以它的选举状态一直是LOOKING状态。(由于人都是自私的,机器也一样,所以服务器1先给自己投一个leader票)
(2)服务器2启动,同样,服务器2在启动以后也会先给自己投一票。它与最开始启动的服务器1进行通信,互相交换自己的选举结果,由于两者都没有历史数据,并且server2的id比server1大,所以id较大的服务器2胜出,但是由于没有达到超过半数以上的服务器都同意选举它(这个例子中的半数以上是3),所以服务器1、2还是继续保持LOOKING状态。
(3)服务器3启动,根据前面的理论分析,服务器3成为服务器1、2、3中的老大,而与上面不同的是,此时有三台服务器选举了它,所以它成为了这次选举的leader。
(4)服务器4启动,根据前面的分析,理论上服务器4应该是服务器1、2、3、4中最大的,但是由于前面已经有半数以上的服务器选举了服务器3,所以它只能接收当小弟的命了。
(5)服务器5启动,同4一样当小弟。
这里有几个需要注意的概念:
SID:服务器ID。用来唯一标识一台ZooKeeper集群中的机器,每台机器不能重复,和myid一致。
ZXID:事务ID。ZXID是一个事务ID,用来标识一次服务器状态的变更。在某一时刻,集群中的每台机器的ZXID值不一定完全一致,这和ZooKeeper服务器对于客户端"更新请求"的处理逻辑有关。
Epoch:每个Leader任期的代号。没有Leader时同一轮投票过程中的逻辑时钟值是相同的。每投完一次票这个数据就会增加
非第一次启动选举机制
总的来说,可以将选举机制想象成公司选领导。第一次选领导时,大家的资历、掌握的技术都相同,此时可以将每个人的年龄看做选举条件,谁的年龄大就选谁当领导。经历一段时间之后,这个领导辞职了,没有领导了,这时候又要继续选领导。此时就先看谁之前当过领导,当过领导的直接商人。如果大家都没当过,或者有多个人都当过领导,就看谁平常干的事多,谁的贡献更大就选谁当领导。如果出现相同的情况,就再根据年龄选领导,谁大选谁。
以上是 Zookeeper选举机制(重点) 的全部内容, 来源链接: utcz.com/z/535864.html