那些你不知道的TCP冷门知识

最近在做数据库相关的事情,碰到了很多TCP相关的问题,新的场景新的挑战,有很多之前并没有掌握透彻的点,大大开了一把眼界,选了几个案例分享一下。
案例一:TCP中并不是所有的RST都有效
背景知识:在TCP协议中,包含RST标识位的包,用来异常的关闭连接。在TCP的设计中它是不可或缺的,发送RST段关闭连接时,不必等缓冲区的数据都发送出去,直接丢弃缓冲区中的数据。而接收端收到RST段后,也不必发送ACK来确认。
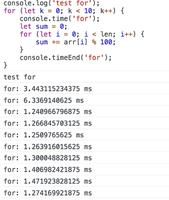
问题现象:某客户连接数据库经常出现连接中断,但是经过反复排查,后端数据库实例排查没有执行异常或者Crash等问题,客户端Connection reset的堆栈如下图
经过复现及双端抓包的初步定位,找到了一个可疑点,TCP交互的过程中客户端发了一个RST(后经查明是客户端本地的一些安全相关iptables规则导致),但是神奇的是,这个RST并没有影响TCP数据的交互,双方很愉快的无视了这个RST,很开心的继续数据交互,然而10s钟之后,连接突然中断,参看如下抓包:
关键点分析
从抓包现象看,在客户端发了一个RST之后,双方的TCP数据交互似乎没有受到任何影响,无论是数据传输还是ACK都很正常,在本轮数据交互结束后,TCP连接又正常的空闲了一会,10s之后连接突然被RST掉,这里就有两个有意思的问题了:
- TCP数据交互过程中,在一方发了RST以后,连接一定会终止么
- 连接会立即终止么,还是会等10s
查看一下RFC的官方解释:
简单来说,就是RST包并不是一定有效的,除了在TCP握手阶段,其他情况下,RST包的Seq号,都必须in the window,这个in the window其实很难从字面理解,经过对Linux内核代码的辅助分析,确定了其含义实际就是指TCP的 —— 滑动窗口,准确说是滑动窗口中的接收窗口。
我们直接检查Linux内核源码,内核在收到一个TCP报文后进入如下处理逻辑:
下面是内核中关于如何确定Seq合法性的部分:
总结
Q:TCP数据交互过程中,在一方发了RST以后,连接一定会终止么?
A:不一定会终止,需要看这个RST的Seq是否在接收方的接收窗口之内,如上例中就因为Seq号较小,所以不是一个合法的RST被Linux内核无视了。
Q:连接会立即终止么,还是会等10s?A:连接会立即终止,上面的例子中过了10s终止,正是因为,linux内核对RFC严格实现,无视了RST报文,但是客户端和数据库之间经过的SLB(云负载均衡设备),却处理了RST报文,导致10s(SLB 10s 后清理session)之后关闭了TCP连接
这个案例告诉我们,透彻的掌握底层知识,其实是很有用的,否则一旦遇到问题,(自证清白并指向root cause)都不知道往哪个方向排查。
案例二:Linux内核究竟有多少TCP端口可用
背景知识:我们平时有一个常识,Linux内核一共只有65535个端口号可用,也就意味着一台机器在不考虑多网卡的情况下最多只能开放65535个TCP端口。
但是经常看到有单机百万TCP连接,是如何做到的呢,这是因为,TCP是采用四元组(Client端IP + Client端Port + Server端IP + Server端Port)作为TCP连接的唯一标识的。如果作为TCP的Server端,无论有多少Client端连接过来,本地只需要占用同一个端口号。而如果作为TCP的Client端,当连接的对端是同一个IP + Port,那确实每一个连接需要占用一个本地端口,但如果连接的对端不是同一个IP + Port,那么其实本地是可以复用端口的,所以实际上Linux中有效可用的端口是很多的(只要四元组不重复即可)。
问题现象:作为一个分布式数据库,其中每个节点都是需要和其他每一个节点都建立一个TCP连接,用于数据的交换,那么假设有100个数据库节点,在每一个节点上就会需要100个TCP连接。当然由于是多进程模型,所以实际上是每个并发需要100个TCP连接。假如有100个并发,那就需要1W个TCP连接。但事实上1W个TCP连接也不算多,由之前介绍的背景知识我们可以得知,这远远不会达到Linux内核的瓶颈。但是我们却经常遇到端口不够用的情况, 也就是“bind:Address already in use”:
其实看到这里,很多同学已经在猜测问题的关键点了,经典的TCP time_wait 问题呗,关于TCP的 time_wait 的背景介绍以及应对方法不是本文的重点就不赘述了,可以自行了解。乍一看,系统中有50W的 time_wait 连接,才65535的端口号,必然不可用:
但是这个猜测是错误的!因为系统参数 net.ipv4.tcp_tw_reuse 早就已经被打开了,所以不会由于 time_wait 问题导致上述现象发生,理论上说在开启 net.ipv4.cp_tw_reuse 的情况下,只要对端IP + Port 不重复,可用的端口是很多的,因为每一个对端IP + Port都有65535个可用端口:
问题分析
- Linux中究竟有多少个端口是可以被使用
- 为什么在 tcp_tw_reuse 情况下,端口依然不够用
Linux有多少端口可以被有效使用
理论来说,端口号是16位整型,一共有65535个端口可以被使用,但是Linux操作系统有一个系统参数,用来控制端口号的分配:
net.ipv4.ip_local_port_range我们知道,在写网络应用程序的时候,有两种使用端口的方式:
- 方式一:显式指定端口号 —— 通过 bind() 系统调用,显式的指定bind一个端口号,比如 bind(8080) 然后再执行 listen() 或者 connect() 等系统调用时,会使用应用程序在 bind()中指定的端口号。
- 方式二:系统自动分配 —— bind() 系统调用参数传0即 bind(0) 然后执行 listen()。或者不调用 bind(),直接 connect(),此时是由Linux内核随机分配一个端口号,Linux内核会在 net.ipv4.ip_local_port_range 系统参数指定的范围内,随机分配一个没有被占用的端口。
例如如下情况,相当于 1-20000 是系统保留端口号(除非按方法一显式指定端口号),自动分配的时候,只会从 20000 - 65535 之间随机选择一个端口,而不会使用小于20000的端口:
为什么在 tcp_tw_reuse=1 情况下,端口依然不够用
细心的同学可能已经发现了,报错信息全部都是 bind() 这个系统调用失败,而没有一个是 connect() 失败。在我们的数据库分布式节点中,所有 connect() 调用(即作为TCP client端)都成功了,但是作为TCP server的 bind(0) + listen() 操作却有很多没成功,报错信息是端口不足。
由于我们在源码中,使用了 bind(0) + listen() 的方式(而不是bind某一个固定端口),即由操作系统随机选择监听端口号,问题的根因,正是这里。connect() 调用依然能从
net.ipv4.ip_local_port_range 池子里捞出端口来,但是 bind(0) 却不行了。为什么,因为两个看似行为相似的系统调用,底层的实现行为却是不一样的。
源码之前,了无秘密:bind() 系统调用在进行随机端口选择时,判断是否可用是走的 inet_csk_bind_conflict ,其中排除了存在 time_wait 状态连接的端口:
而 connect() 系统调用在进行随机端口的选择时,是走 __inet_check_established 判断可用性的,其中不但允许复用存在 TIME_WAIT 连接的端口,还针对存在TIME_WAIT的连接的端口进行了如下判断比较,以确定是否可以复用:
一张图总结一下:
于是答案就明了了,bind(0) 和 connect()冲突了,ip_local_port_range 的池子里被 50W 个 connect() 遗留的 time_wait 占满了,导致 bind(0) 失败。知道了原因,修复方案就比较简单了,将 bind(0) 改为bind指定port,然后在应用层自己维护一个池子,每次从池子中随机地分配即可。
总结
Q:Linux中究竟有多少个端口是可以被有效使用的?
A:Linux一共有65535个端口可用,其中 ip_local_port_range 范围内的可以被系统随机分配,其他需要指定绑定使用,同一个端口只要TCP连接四元组不完全相同可以无限复用。
Q:什么在 tcp_tw_reuse=1 情况下,端口依然不够用?
A:connect() 系统调用和 bind(0) 系统调用在随机绑定端口的时候选择限制不同,bind(0) 会忽略存在 time_wait 连接的端口。
这个案例告诉我们,如果对某一个知识点比如 time_wait,比如Linux究竟有多少Port可用知道一点,但是只是一知半解,就很容易陷入思维陷阱,忽略真正的Root Case,要掌握就要透彻。
案例三:诡异的幽灵连接
背景知识:TCP三次握手,SYN、SYN-ACK、ACK是所有人耳熟能详的常识,但是具体到Socket代码层面,是如何和三次握手的过程对应的,恐怕就不是那么了解了,可以看一下如下图,理解一下(图源:小林coding):
这个过程的关键点是,在Linux中,一般情况下都是内核代理三次握手的,也就是说,当你client端调用 connect() 之后内核负责发送SYN,接收SYN-ACK,发送ACK。然后 connect() 系统调用才会返回,客户端侧握手成功。
而服务端的Linux内核会在收到SYN之后负责回复SYN-ACK再等待ACK之后才会让 accept() 返回,从而完成服务端侧握手。于是Linux内核就需要引入半连接队列(用于存放收到SYN,但还没收到ACK的连接)和全连接队列(用于存放已经完成3次握手,但是应用层代码还没有完成 accept() 的连接)两个概念,用于存放在握手中的连接。
问题现象:我们的分布式数据库在初始化阶段,每两个节点之间两两建立TCP连接,为后续数据传输做准备。但是在节点数比较多时,比如320节点的情况下,很容易出现初始化阶段卡死,经过代码追踪,卡死的原因是,发起TCP握手侧已经成功完成的了 connect() 动作,认为TCP已建立成功,但是TCP对端却没有握手成功,还在等待对方建立TCP连接,从而整个集群一直没有完成初始化。
关键点分析:看过之前的背景介绍,聪明的小伙伴一定会好奇,假如我们上层的 accpet() 调用没有那么及时(应用层压力大,上层代码在干别的),那么全连接队列是有可能会满的,满的情况会是如何效果,我们下面就重点看一下全连接队列满的时候会发生什么。当全连接队列满时,connect() 和 accept() 侧是什么表现行为?实践是检验真理的最好途径我们直接上测试程序。
client.c :
server.c :
通过执行上述代码,我们观察Linux 3.10版本内核在全连接队列满的情况下的现象。神奇的事情发生了,服务端全连接队列已满,该连接被丢掉,但是客户端 connect() 系统调用却已经返回成功,客户端以为这个TCP连接握手成功了,但是服务端却不知道,这个连接犹如幽灵一般存在了一瞬又消失了:
这个问题对应的抓包如下:
正如问题中所述的现象,在一个320个节点的集群中,总会有个别节点,明明 connect() 返回成功了,但是对端却没有成功,因为3.10内核在全连接队列满的情况下,会先回复SYN-ACK,然后移进全连接队列时才发现满了于是丢弃连接,这样从客户端看来TCP连接成功了,但是服务端却什么都不知道。
Linux 4.9版本内核在全连接队列满时的行为在4.9内核中,对于全连接队列满的处理,就不一样,connect() 系统调用不会成功,一直阻塞,也就是说能够避免幽灵连接的产生:
抓包报文交互如下,可以看到Server端没有回复SYN-ACK,客户端一直在重传SYN:
事实上,在刚遇到这个问题的时候,我第一时间就怀疑到了全连接队列满的情况,但是悲剧的是看的源码是Linux 3.10的,而随手找的一个本地日常测试的ECS却刚好是Linux 4.9内核的,导致写了个demo测试例子却死活没有复现问题。排除了所有其他原因,再次绕回来的时候已经是一周之后了(这是一个悲伤的故事)。
总结
Q:当全连接队列满时,connect() 和 accept() 侧是什么表现行为?
A:Linux 3.10内核和新版本内核行为不一致,如果在Linux 3.10内核,会出现客户端假连接成功的问题,Linux 4.9内核就不会出现问题。
这个案例告诉我们,实践是检验真理的最好方式,但是实践的时候也一定要睁大眼睛看清楚环境差异,如Linux内核这般稳定的东西,也不是一成不变的。唯一不变的是变化,也许你也是可以来数据库内核玩玩底层技术的。
原文链接
本文为阿里云原创内容,未经允许不得转载。
以上是 那些你不知道的TCP冷门知识 的全部内容, 来源链接: utcz.com/z/535540.html