GaussDB架构(下)

GaussDB云数据库架构
云数据库系统的主要目的是提供数据库系统服务的基础设施,以实现对计算机资源的共享。本文所讲述的GaussDB云数据库架构设计的内容,目前处于研发阶段,对应产品尚未向客户发布。
1.设计思想与目标客户
从数据存放的位置来看,云数据库系统可以分成三大类:
- 公有云数据库系统服务: 该类数据库系统服务主要面向中小型企业的数据库需求。针对中小型企业提供公有云数据库系统服务,可以大幅降低这类公司的运营成本,比如构建数据中心或者机房、构建服务器、运维服务器、运维数据库系统的成本等,同时也使得这类使用公有云数据库系统服务的公司,可以更加专注在业务领域,而无须花费太多的精力在基础设施的构建上。
- 私有云数据库系统服务: 该类数据库服务主要面向大中型企业的数据库服务需求。这类云数据库系统的构建,通常需要在公司内部购买大量的设备,同时构筑相关的PaaS层、SaaS层,其中数据库服务是非常关键的一类服务。该类服务使得公司内部的各个部门的信息新系统可以共享相关资源,同时实现数据共享,并降低整体的维护成本,最终降低总体拥有成本。
- 混合云数据库系统服务: 这类数据库服务同时包含公有云数据库系统服务和私有云数据库系统服务两类。至于哪部分数据库系统服务选择公有云服务,哪部分数据库系统服务选择私有云服务,主要从降低系统的总体拥有成本(Total Cost of Ownership,TCO)上考虑,包括构建成本、运维成本、折旧费用等。
应该选择哪种云数据库服务,主要从如下3个层面权衡。
- 成本。当企业的系统规模不是很大,通常情况下租用公有云数据库系统服务的成本会低于在企业内部构建数据库系统服务的成本,但是当系统规模扩大到一定程度,在企业内部构建私有云的成本会比购买公有云服务的成本低。当前规模稍大的物联网企业,如今日头条、美团等均是构建企业内部的云服务。
- 差异化竞争力。如果企业对外竞争力构筑在数据库系统服务的基础上,那么企业也将构筑自己的私有云数据库系统服务。
- 数据的隐私度及价值。如果数据是企业的重要资产和核心竞争力,那么这类企业大多会采用基于私有云的数据库系统服务,以更好地保护数据及个人隐私。
通过上述的分析,中小型企业通常在成本、竞争力构筑、数据隐私保护这几方面权衡后,更大概率地选择公有云数据库系统服务,而大中型企业则更大概率地选择私有云数据库系统服务或者混合云数据库系统服务,其中成本因素会占据比较高的比重。GaussDB云数据系统的目标客户主要是大中型企业。
大中型企业对云数据库系统的需求与中小型企业对云数据库系统服务的需求有较多的不同之处,具体分析如下:
- 具有更加高效的资源整合和利用能力。对于大中型企业,通常会管辖多个部门,这些独立部门有独立的、不同的业务,为此每个部门均针对各自不同的业务,配备不同的数据库系统,并由此提供数据库系统服务; 另外,对于大中型企业,为了更好地服务各个业务部门,通常会组建平台部门,并为业务部门提供更好的数据库系统服务支持。为了提升整个企业对计算机资源、数据库系统资源的利用率,实现资源的共享和整合非常有必要,将进一步降低整体成本。
- 对数据库系统的规格,特别是SLA(Service Level Agreements,服务水平协议)有更加严格的要求。大中型企业通常服务的客户数量大,业务重要,因此对数据库服务请求的吞吐量、每个请求的响应时延、容量扩展速度、计算扩展速度均有更加严格的要求。
- 大中型企业内部多个部门之间的业务并不是完全独立的,通常各自系统之间存在着一定的耦合关系。这类耦合关系,通常表现在数据库表模式之间的耦合关系、数据对象之间的一致性问题、数据之间流动关联关系(Extract Transform Loadworkflow,ETL)。例如某银行,需要通过数据中台维护各个部门之间数据表模式的一致性。
- 具有对新应用的快速迭代和快速开发需求。为了能够加速新应用的开发,在云场景下对数据库系统的克隆、回溯、合并等能力提出了新的需求。特别是在大数据规模环境下,如何高效地实现数据库数据的克隆、回溯等能力是极其重要的。
2. 弹性伸缩的多租户数据库架构
为了能够适应各类大中型企业对云数据库系统的需求,GaussDB云数据库系统提供了更强的存储资源、计算资源之间的组合能力。其主要目的是实现存储资源的独立扩容和缩容能力、计算资源的独立扩容和缩容能力,以及存储资源与计算资源在弹性扩缩容环境下的自由组合能力。从本质而言,GaussDB 云数据库系统提供多租户(Multi-tenant)和扩缩容(Elasticity)的组合能力。
多租户存储计算共享架构
单个应用服务独立部署转向共享服务,对企业内部数据库系统的运维产生较大的变革,并有效降低其运维成本。
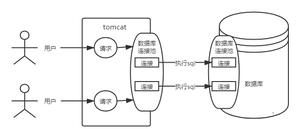
如下图所示,数据库系统从孤立的独立部署转向计算与存储共享的部署形态,在实现计算与存储共享的同时实现存储资源的独立扩缩容,以及计算资源独立的扩缩容。当云部署的数据库系统能够提供独立的存储、计算扩缩容能力后,数据系统需要被迁移的概率将被大幅度降低,由此可以提升数据库系统的业务连续性(BusinessContinuity),系统比较容易实现在运行过程中存储资源的扩缩容,以及计算资源的扩缩容。
图 多租户数据库系统部署形态
三层逻辑架构实现存储、计算独立扩缩容
为了有效实现云数据库系统在存储资源、计算资源的独立扩缩容,需要实现计算与存储的解耦,以及各自的扩缩容能力。
如下图所示,为了实现GaussDB云数据库系统在存储和计算方面的弹性,现将整个数据库系统分为3层,分别是弹性存储层、弹性事务处理层及无状态SQL 执行层。GaussDB云数据可以在事务处理层实现横向扩展,以保证满足大中型企业对数据库系统的不同需求。无状态的SQL执行层,可以实现对不同客户端连接请求数进行扩展的能力。
图 GaussDB云数据库系统的分层架构
GaussDB虽然实现了在数据库系统3个层次上的不同可扩展能力,但是不要以为这些组件是部署在不同的物理机器上。相反的,为了更好地提供性能,这3个层次的组件通常在部署的时候,具有很强的相关性,需要尽可能地联合部署(尽量部署在一台物理机上或一个交换机内),以降低网络时延带来的开销。
云数据库的克隆与复制支持
将企业的数据库系统搬到云系统之上,可以提供更加便利的数据库系统管理功能,以满足企业对业务的测试、新业务的构建等不同需求,加速业务上线的速度。
由于云数据库系统实现多个数据库系统之间数据的共享(即在一个存储池中,存储大量的数据库)。因此,可以实现对这些数据库高效的复制、克隆等功能。比如,某公司可能需要基于现有数据库系统的当前数据,开发一个新的应用。传统的做法是,为了测试应开发的应用不影响到现有的线上应用,公司通常会构建一个新的数据库系统,并从当前线上系统导出一份最新的数据,将这份新的数据导入另外一个数据库系统中(比如刚创建的数据库系统实例),并在该数据库系统开发、测试新的应用。
当这些数据库系统共同部署在云数据库系统中时,可以实现数据库系统的克隆(包括数据与系统)和复制(仅数据),比如使用COW 机制(对于持久化存储的Copyon-Write机制)可以实现对于数据库数据的快速克隆(仅克隆了元数据,数据库数据并未复制)。通过COW 机制,构建在克隆数据库上的业务可以直接修改克隆的数据库系统中的数据。
如下图所示,云数据库系统可以对生产数据库系统进行克隆、复制等操作,对于克隆、复制出来的数据库系统可以用于非生产系统,并用于开发、测试流程或是参与到基准测试中。需要说明的是,用户非生产系统的数据库系统保持了和生产系统当前一致的数据,同时生产系统中更新的一部分数据也可以实时同步到非生产数据库系统中,进而保持这两部分数据之间的一致性。
图 GaussDB云数据库系统的数据库克隆与复制
通过上述分析,GaussDB云数据库系统通过分层,实现了在存储层和计算层的弹性以及这两者的任意组合,能够较好地适应大中型企业对云数据库系统的需求。另外,GaussDB云数据库系统在此基础上又进一步实现了对现有数据库系统的高效克隆、复制,以满足中大型企业提升业务演进的速度和节奏。
GaussDB多模数据库架构
从字面意思来理解,多模数据库系统主要用于实现对多种模型数据的管理与处理。它包括3个层面的内容:
- 多模数据的存储: 一个统一的多模数据库系统需要提供多种数据模型,包括关系、时序、流、图、空间等的存储能力。
- 多模数据的处理: 一个统一的多模数据库系统需要提供多种数据库模型,包括关系、时序、流、图、空间等的处理能力。
- 多模数据之间的相关转换: 大多数情况下,客户的数据产生源只有一个,即数据产生源的数据模型是单一的,但是后续处理中可能需要使用多种数据库模型来表征物理世界,进而进行数据处理,或者需要通过多种模型之间相互协作来完成单一任务,因此不同模型之间的数据转换也是极为重要的。
1. 设计思想与目标客户
多模数据库系统的设计与实现,主要是为了简化客户对数据管理、数据处理的复杂度,以及降低整体系统运维的复杂度。为此,在数据库系统之上提供统一的多模数据管理、处理能力,以及统一运维能力是多模数据库系统核心设计思想。经过近两年的设计与开发,我们总结出客户的需求,客户可以分成如下两大类,而不同的类别的客户将影响到整个多模数据库系统的架构。
- 侧重多模数据一致性的客户: 这类客户通常有比较单一的数据产生源,并以关系数据为主,重要关键性业务是强调数据之间的一致性,如银行类客户、政府类客户。在构建多模数据库系统时,需要重点考虑多模数据之间的一致性,以及多模数据之间的融合处理。
- 侧重多模极致性能的客户: 这类客户的需求通常无法通过简单的多模数据融合来达成。在他们苛刻的条件下,通常需要极致地优化性能,才能满足他们的需求。
2. 面向数据强一致的多模数据库系统架构
GaussDB用户除能使用关系数据库外,还有使用图数据库、时序等多模引擎的能力。如公共安全场景下,用户会将MPPDB(Massively Parallel Processing DataBase,大规模并行处理数据库)的数据,导出到图数据库中,使用图引擎提供的图遍历算法,查找同航班、同乘火车等关系。在类似应用场景下,存在数据转换性能低,使用多套系统维护和开发成本高,数据导出安全性差等问题。引入多模数据库统一框架[Multi-ModelDatabase (MMDB) Uniform Framework],为用户提供关系数据库、图数据库、时序数据库等多模数据库统一数据访问和维护接口,减少运维和应用开发人员的学习和使用成本,提升数据使用安全性(数据无须在多个系统之间进行切换,减少了数据在网络上暴露的时间),如下图所示。
图 多模数据库逻辑架构图[Multi-Model Database (MMDB) Uniform Framework]
系统逻辑架构
多模数据库统一框架基于GaussDB开发,通过类似领养(Linked)机制,快速扩展图、时序数据库引擎,对外提供统一的DML、DDL、DCL、Utilities、GUI访问接口。运维和应用开发人员可以将扩展的多模数据库与GaussDB无缝衔接起来,当成一套系统,统一管理与运维通过统一接口使用扩展引擎提供的能力,减少对新的数据库引擎的学习和使用成本。具体介绍如下。
- 扩展引擎(Extension Engine)包括图引擎、时序引擎、空间引擎,扩展采用统一机制、模块化设计,并提供类似领养机制,具有扩展快速、对原系统无影响的优点。
- 统一(Uniform)DML提供关系数据库SQL、图数据库图遍历语言(Gremlin)、时序函数和操作等多语言的数据操作能力。用户可以使用统一的ODBC、JDBC、GUI接口访问MPPDB及扩展引擎。
- 统一DDL、DCL、Utilities均使用存储过程,为各扩展引擎维护专属的虚拟系统表(Pseudo Catalog),减少对MPPDB的影响和依赖。
- 统一DDL为扩展引擎提供统一数据定义能力,包括扩展引擎创建、删除,扩展引擎对象的创建、销毁[如上图所示图引擎的图(graph)、顶点(vertex)、边(edge)的创建和删除]等DDL能力。
- 统一DCL为扩展引擎提供统一数据控制能力,包括统一权限(Grant、Revoke)管理,性能统计(Analyze)能力。
- 统一Utilities提供备份恢复、安装卸载、集群管理等功能。
- 统一GUI在高斯Data Studio IDE基础上,扩展了对图数据库、时序数据库的支持,提供扩展引擎的基本数据访问接口及管理接口(备份、恢复等)。设计时尽量保持Data Studio原有系统设计及显示结构,减少对原有Data Studio的改动量。
在上图的多模数据库系统的逻辑架构中,除了统一的多模框架外,该系统架构使用了统一的数据存储,即关系型存储。据统计,当前大量客户的数据产生源主要包括两大类: ①关系型交易数据系统; ②传感器(周期性地产生比较规则的数据)。分布式关系数据库系统实现数据的统一存储与处理,可以大幅度简化客户的数据处理,最终实现数据的强一致。
为了简化用户对数据的管理与处理,我们在数据统一存储(即关系型存储)的基础上提供了多类数据处理引擎,包括图引擎、时序引擎、空间引擎等,不仅可以提高对多类数据模型的处理效率,同时也提供了多类数据处理引擎的处理语言。比如,对于图引擎,提供了Gremlin图处理语言的支持; 对于时序引擎,提供了业界标准的时序处理语言。
多模数据库系统中多模数据模型的任意组合。为了适应不同用户对不同类型数据处理的需求,GaussDB多模数据库系统提供了多种模型之间的任意组合。在整体架构上,将引擎的元数据独立出来,以实现任意时刻的启动和关闭新的多模引擎。
系统物理架构
多模数据库是处理包含图、时序等多种数据模型的统一的数据库。下图给出了多模数据库的物理设计架构图。多模数据库提供统一的DDL和DCL管理,用户可以方便地把外部引擎交给多模数据库进行管理。
图 GaussDB多模数据库的物理设计架构图
多模数据库DML采用UDF(User Defined Function,用户自定义函数)的方式,提供统一的GUI、ODBC、JDBC等外部接口,输入相应的UDF进行对外部数据的查询分析。多模数据库接收到查询请求后,发送给对应的外部引擎执行,并将执行结果返回,借助GaussDB原有的方式呈现给用户。
多模数据库的系统表采用虚拟系统表(Pseudo Catalog)的方式管理。虚拟系统表都是用户表。这样,用户可以方便地添加和删除多模的能力,对MPPDB的影响减到最小。
多模数据库在GaussDB 基础上进行设计。GaussDB 引入多模框架后,需要在GaussDB内部进行扩展,用来适配多模数据的执行和管理流程。这里的扩展指的是GaussDB内部针对多模引擎所做的适配。它既可以是功能上的,包括多模数据对象和关系数据对象的相互依赖关系,对异常处理、事务管理所做的适配,还有针对多模数据的执行流程在GaussDB内部所做的适配工作;又可以是性能上的,例如优化器等组件上提供对多模引擎的支持。
公共模块(Common Envelope)介于这些扩展和外部引擎之间,关键组件———公共模块封装(Common Envelope Wrapper)打包提供了GaussDB扩展针对不同引擎的具体实现。也可以把这部分内容叫作外部引擎封装(Foreign Engine Wrapper)。即针对不同的引擎,可以通过外部引擎封装打包不同的实现过程。
此外多模数据库还提供其他统一框架管理,包括连接管理、轻量解析(ShallowParse)和多模缓存管理等。
3. 面向极致性能的多模数据库系统架构
面向极致性能的场景,如极端的互联网场景,上述多模数据系统可能无法满足需求。如果需要处理的数据量,或者需要处理的响应时间包含有极致的要求,统一的关系存储可能无法满足要求。在这类业务场景下,通常需要面向特性数据模型的原生数据存取模型,进而加速数据的存取与处理,面向极致性能的多模数据库系统架构如下图所示。
图 面向极致性能的多模数据库系统架构
小结
GaussDB从华为公司内部开始应用,现在已经发展为多个数据库产品系列,包括了GaussDB OLTP数据库、GaussDB OLAP数据库、GaussDB云数据库、多模数据库等,形成了种类丰富、技术先进的数据库系列。随着处理器、存储介质等硬件的持续发展和软件技术的日益更新,新型应用不断产生,GaussDB数据库也将提供更加丰富的产品。
Gauss松鼠会是汇集数据库爱好者和关注者的大本营, 大家共同学习、探索、分享数据库前沿知识和技术, 互助解决问题,共建数据库技术交流圈。
以上是 GaussDB架构(下) 的全部内容, 来源链接: utcz.com/z/535494.html