redis系列之数据库与缓存数据一致性解决方案 [数据库教程]

场景一
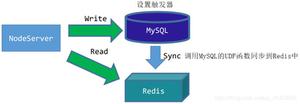
一般来说,只要你用到了缓存,不管是Redis还是memcache,就可能会涉及到数据库缓存与数据的一致性问题,这里我们以Redis为例。
我们该如何保证Redis与数据库的一致性呢?
So easy:
- 更新的时候,先更新数据库,然后再删除缓存。
- 读的时候,先读缓存;如果没有的话,就读数据库,同时将数据放入缓存,并返回响应。
乍一看,一致性问题貌似很好的得到了解决。但仔细一想,你会发现还是有问题:如果先更新了数据库,删除缓存的时候失败了怎么办?那么数据库中是新数据,缓存中是老数据,数据出现不一致了。
改进方案:
先删除缓存,后更新数据库。因为即使后面更新数据库失败了,缓存是空的,读的时候会从数据库中重新拉,虽然都是旧数据,但数据是一致的。
这种情况应该是先删除缓存,然后在更新数据库,如果删除缓存失败,那就不要更新数据库,如果说删除缓存成功,而更新数据库失败,那查询的时候只是从数据库里查了旧的数据而已,这样就能保持数据库与缓存的一致性。
所以方案就变成了:
- 更新的时候,先删除缓存,然后再更新数据库。
- 读的时候,先读缓存;如果没有的话,就读数据库,同时将数据放入缓存,并返回响应。
场景二
在高并发的情况下,如果当删除完缓存的时候,这时去更新数据库,但还没有更新完,另外一个请求来查询数据,发现缓存里没有,就去数据库里查,还是以上面商品库存为例,如果数据库中产品的库存是100,那么查询到的库存是100,然后插入缓存,插入完缓存后,原来那个更新数据库的线程把数据库更新为了99,导致数据库与缓存不一致的情况
场景二解决方案
遇到这种情况,可以用队列的去解决这个问,创建几个队列,如20个,根据商品的ID去做hash值,然后对队列个数取摸,当有数据更新请求时,先把它丢到队列里去,当更新完后在从队列里去除,如果在更新的过程中,遇到以上场景,先去缓存里看下有没有数据,如果没有,可以先去队列里看是否有相同商品ID在做更新,如果有也把查询的请求发送到队列里去,然后同步等待缓存更新完成。
这里有一个优化点,如果发现队列里有一个查询请求了,那么就不要放新的查询操作进去了,用一个while(true)循环去查询缓存,循环个200MS左右,如果缓存里还没有则直接取数据库的旧数据,一般情况下是可以取到的。
在高并发下解决场景二要注意的问题
(1)读请求时长阻塞
由于读请求进行了非常轻度的异步化,所以一定要注意读超时的问题,每个读请求必须在超时间内返回,该解决方案最大的风险在于可能数据更新很频繁,导致队列中挤压了大量的更新操作在里面,然后读请求会发生大量的超时,最后导致大量的请求直接走数据库,像遇到这种情况,一般要做好足够的压力测试,如果压力过大,需要根据实际情况添加机器。
(2)请求并发量过高
这里还是要做好压力测试,多模拟真实场景,并发量在最高的时候QPS多少,扛不住就要多加机器,还有就是做好读写比例是多少
(3)多服务实例部署的请求路由
可能这个服务部署了多个实例,那么必须保证说,执行数据更新操作,以及执行缓存更新操作的请求,都通过nginx服务器路由到相同的服务实例上
(4)热点商品的路由问题,导致请求的倾斜
某些商品的读请求特别高,全部打到了相同的机器的相同丢列里了,可能造成某台服务器压力过大,因为只有在商品数据更新的时候才会清空缓存,然后才会导致读写并发,所以更新频率不是太高的话,这个问题的影响并不是很大,但是确实有可能某些服务器的负载会高一些。
redis系列之数据库与缓存数据一致性解决方案
以上是 redis系列之数据库与缓存数据一致性解决方案 [数据库教程] 的全部内容, 来源链接: utcz.com/z/535188.html