Spark(十一)【SparkSQL的基本使用】 [数据库教程]

一. SparkSQL简介
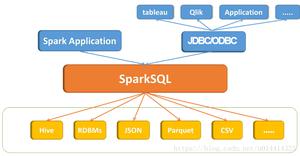
Spark SQL是Spark用于结构化数据(structured data)处理的Spark模块。
Dremel ------> Drill(Apache)------>Impala(Cloudrea) Presto(Hotonworks)
Hive -------> Shark(对Hive的模仿,区别在于使用Spark进行计算)
Shark------->SparkSQL(希望拜托对Hive的依赖,兼容Hive)
SparkSQL: 如果使用SparkSQL执行Hive语句! 这种行为称为 Spark on Hive
? 如果使用Hive,执行Hive语句,但是在配置Hive时,修改了Hive的执行引擎,将执行引擎修改为了Spark! 这种行为称为Hive on Spark!
特点
- 易整合。 在程序中既可以使用SQL,还可以使用API!
- 统一的数据访问。 不同数据源中的数据,都可以使用SQL或DataFrameAPI进行操作,还可以进行不同数据源的Join!
- 对Hive的无缝支持
- 支持标准的JDBC和ODBC
二. 数据模型
DataFrame:DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
DataSet:是DataFrame的一个扩展,类似于数据库中的表。
区别
DataSet是强类型。DataSet=DataSet[Person].
DataFrame是弱类型。DataFrame=DataSet[Row],是DataSet的一个特例。
三. SparkSQL核心编程
Spark Core:要执行应用程序,要首先构建上下文环境对象SparkContext.
SparkSQL
老的版本中,提供两种SQL查询起始点:一个叫SQLContext,用于Spark自己提供的SQL查询;一个叫HiveContext,用于连接Hive的查询。
最新的版本SparkSQL的查询入口是SparkSession。是SQLContext和HiveContext的组合,SparkSession内部封装了SparkContext
1. IDEA开发SparkSQL
pom依赖
<dependency> <groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.0.0</version>
</dependency>
2. SparkSession
创建和关闭
import org.apache.spark.SparkConf import org.apache.spark.sql.SparkSession
/**
* 创建SparkSession
*/
@Before
def innit: Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
}
/**
* 关闭SparkSession
*/
@After
def stop: Unit = {
session.stop()
}
获取SparkContext
session.sparkContext //获取SparkSession中的SparkContext3. DataFrame
3.1 入门案例
/** * DataFrame入门案例
*/
@Test
def createDF: Unit = {
//数据格式:{"username":"zhangsan","age":20}
//读取json格式文件创建DataFrame
val df: DataFrame = session.read.json("input/1.txt")
//创建临时视图:person
df.createOrReplaceTempView("person")
//查看person表
df.show()
//通过sql查询
session.sql(
"""
|select
|*
|from
|person
|""".stripMargin).show()
}
3.2 显示数据
df.show()3.3 创建DF
①读取数据源创建
session.readcsv format jdbc json load option options orc parquet schema table text textFile
②通过RDD创建DataFrame
样例类??
实际开发中,一般通过样例类将RDD转换为DataFrame
先导入隐式转换包,通过rdd.toDF()方法转换
/** * Person样例类
*/
case class Person(name: String, age: Int)
/**
* 通过RDD创建DataFrame
*/
@Test
def creatDFByRDD {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//根据样例类创建RDD
val rdd: RDD[(String, Int)] = session.sparkContext.makeRDD(List(("zhangsan", 12), ("lisi", 45), ("wangwu", 23)))
val person_RDD: RDD[Person] = rdd.map {
case (name, age) => Person(name, age)
}
//导入隐式包,session是上文创建的SparkSession对象
import session.implicits._
val df: DataFrame = person_RDD.toDF()
//查看DF
df.show()
session.stop()
}
③从hive表查询**
3.4 SQL查询语法
首先由DataFrame创建一个视图,然后用Sql语法操作
/*****************创建视图************************///临时视图
createOrReplaceTempView("视图名") //不会报错
createTempView("视图名") //视图名已存在,会报错
//永久视图
df.createGlobalTempView("person")
/******************Sql查询*************************/
//临时视图:person
//查询全局视图需要添加:global_temp.person
session.sql(
"""
|select
|*
|from
|person
|""".stripMargin).show()
注意:普通临时表是Session范围内的,如果想应用范围内有效,可以使用全局临时表。使用全局临时表时需要全路径访问,如:global_temp.people
4. DataSet
DataSet是具有强类型的数据集合,需要提供对应的类型信息。
4.1 创建DS
样例类RDD创建
/** * Person样例类
*/
case class Person(name: String, age: Int)
/**
* 通过RDD创建DataFrame
*/
@Test
def creatDFByRDD {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("MyApp")
val session: SparkSession = SparkSession.builder().config(conf).getOrCreate()
//根据样例类创建RDD
val rdd: RDD[(String, Int)] = session.sparkContext.makeRDD(List(("zhangsan", 12), ("lisi", 45), ("wangwu", 23)))
val person_RDD: RDD[Person] = rdd.map {
case (name, age) => Person(name, age)
}
//导入隐式包,session是上文创建的SparkSession对象
import session.implicits._
val df: Dataset[Person] = person_RDD.toDS()
//查看DF
df.show()
session.stop()
}
基本类型的序列创建DataSet
val list: Seq[Int] = List(1, 2, 3, 4)import session.implicits._
val df1 = list.toDS()
注意:在实际使用的时候,很少用到把序列转换成DataSet,更多的是通过RDD来得到DataSet
5. RDD、DataFrame、DataSet
三者的关系
相互转换
总结:在对DataFrame和Dataset进行操作许多操作都需要这个包:import spark.implicits._(在创建好SparkSession对象后尽量直接导入)
Spark(十一)【SparkSQL的基本使用】
以上是 Spark(十一)【SparkSQL的基本使用】 [数据库教程] 的全部内容, 来源链接: utcz.com/z/535114.html