高可用的MongoDB集群

高可用的MongoDB集群
davidpp
0.9432015.09.22 23:48:04
字数 2,254
阅读 35,992
刚接触MongoDB,就要用到它的集群,只能硬着头皮短时间去看文档和尝试自行搭建。迁移历史数据更是让人恼火,近100G的数据文件,导入、清理垃圾数据执行的速度蜗牛一样的慢。趁着这个时间,把这几天关于Mongod集群相关的内容整理一下。大概介绍一下MongoDB集群的几种方式:Master-Slave、Relica Set、Sharding,并做简单的演示。
使用集群的目的就是提高可用性。高可用性H.A.(High Availability)指的是通过尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。它与被认为是不间断操作的容错技术有所不同。HA系统是目前企业防止核心计算机系统因故障停机的最有效手段。
HA的三种工作方式:
主从方式 (非对称方式)
工作原理:主机工作,备机处于监控准备状况;当主机宕机时,备机接管主机的一切工作,待主机恢复正常后,按使用者的设定以自动或手动方式将服务切换到主机上运行,数据的一致性通过共享存储系统解决。
双机双工方式(互备互援)
工作原理:两台主机同时运行各自的服务工作且相互监测情况,当任一台主机宕机时,另一台主机立即接管它的一切工作,保证工作实时,应用服务系统的关键数据存放在共享存储系统中。
集群工作方式(多服务器互备方式)
工作原理:多台主机一起工作,各自运行一个或几个服务,各为服务定义一个或多个备用主机,当某个主机故障时,运行在其上的服务就可以被其它主机接管
主从架构(Master-Slave)
Mater-Slaves
主从架构一般用于备份或者做读写分离。由两种角色构成:
主(Master)
可读可写,当数据有修改的时候,会将oplog同步到所有连接的salve上去。
从(Slave)
只读不可写,自动从Master同步数据。
特别的,对于Mongodb来说,并不推荐使用Master-Slave架构,因为Master-Slave其中Master宕机后不能自动恢复,推荐使用Replica Set,后面会有介绍,除非Replica的节点数超过50,才需要使用Master-Slave架构,正常情况是不可能用那么多节点的。
还有一点,Master-Slave不支持链式结构,Slave只能直接连接Master。Redis的Master-Slave支持链式结构,Slave可以连接Slave,成为Slave的Slave。
下面演示一下搭建过程:
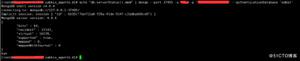
1>. 启动Master
mongod --port 2000 --master --dbpath masterdb/2>. 启动Slave
mongod --port 2001 --slave --source 127.0.0.1:2000 --dbpath slavedb/3>. 给Master里面导入数据,查看Master和Slave的数据。你会发现导入Master的数据同时也会在Slave中出现。
mongoimport --port 2000 -d test -c dataset dataset.json
mongo --port 2000 testdb.dataset.count()
> 25359
mongo --port 2001 testdb.dataset.count()
> 25359
4>. 试一下Master和Slave的写操作。你会发现,只有Master才可以对数据进行修改,Slave修改时候会报错。
mongo --port 2001 testdb.dataset.drop()
> Error: drop failed: { "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" }
mongoimport --port 2001 -d test -c dataset dataset.json
> Failed: error checking connected node type: no reachable servers
副本集架构(Replica Set)
为了防止单点故障就需要引副本(Replication),当发生硬件故障或者其它原因造成的宕机时,可以使用副本进行恢复,最好能够自动的故障转移(failover)。有时引入副本是为了读写分离,将读的请求分流到副本上,减轻主(Primary)的读压力。而Mongodb的Replica Set都能满足这些要求。
Replica Set的一堆mongod的实例集合,它们有着同样的数据内容。包含三类角色:
主节点(Primary)
接收所有的写请求,然后把修改同步到所有Secondary。一个Replica Set只能有一个Primary节点,当Primar挂掉后,其他Secondary或者Arbiter节点会重新选举出来一个主节点。默认读请求也是发到Primary节点处理的,需要转发到Secondary需要客户端修改一下连接配置。
副本节点(Secondary)
与主节点保持同样的数据集。当主节点挂掉的时候,参与选主。
仲裁者(Arbiter)
不保有数据,不参与选主,只进行选主投票。使用Arbiter可以减轻数据存储的硬件需求,Arbiter跑起来几乎没什么大的硬件资源需求,但重要的一点是,在生产环境下它和其他数据节点不要部署在同一台机器上。
注意,一个自动failover的Replica Set节点数必须为奇数,目的是选主投票的时候要有一个大多数才能进行选主决策。
应用客户端
客户端连接单个mongod和副本集的操作是相同,只需要配置好连接选项即可,比如下面是node.js连接Replica Set的方式:
mongoose.connect("mongodb://[username:password@]host1[:port1][,host2[:port2],...[,hostN[:portN]]][/[database][?options]]"[, options]);Primary和Secondary搭建的Replica Set
Primary和Secondary搭建的Replica Set
奇数个数据节点构成的Replica Set,下面演示精典的3个数据节点的搭建过程。
1> 启动3个数据节点,--relSet指定同一个副本集的名字
mongod --port 2001 --dbpath rs0-1 --replSet rs0mongod --port 2002 --dbpath rs0-2 --replSet rs0
mongod --port 2003 --dbpath rs0-3 --replSet rs0
2> 连接到其中一个,配置Replica Set,同时正在执行rs.add的节点被选为Primary。开发环境中<hostname>指的是机器名,生产环境下就是机器的IP。
mongo --port 2001rs.initiate()
rs.add("<hostname>:2002")
rs.add("<hostname>:2003")
rs.conf()
3> 连接Primary节点,导入数据成功。
mongoimport --port 2001 -d test -c dataset dataset.jsonmongo --port 2001 test
db.dataset.count()
> 25359
4> 默认情况下,Secondary不能读和写。
mongo --port 2003 testdb.dataset.count()
> Error: count failed: { "note" : "from execCommand", "ok" : 0, "errmsg" : "not master" }
注意,其中Secondary宕机,不受影响,若Primary宕机,会进行重新选主:
自动Failover
使用Arbiter搭建Replica Set
偶数个数据节点,加一个Arbiter构成的Replica Set,下面演示精典的2个数据节点加一个仲裁者的搭建过程。
特别的,生产环境中的Arbiter节点,需要修改一下配置:
journal.enabled = falsesmallFiles = true
使用Arbiter搭建Replica Set
1> 启动两个数据节点和一个Arbiter节点
mongod --port 2001 --dbpath rs0-1 --replSet rs0mongod --port 2002 --dbpath rs0-2 --replSet rs0
mongod --port 2003 --dbpath arb --replSet rs0
2> 连接到其中一个,添加Secondary和Arbiter。当仅需要添加Aribiter的时候,只需连接当前Replica Set的Primary,然后执行rs.addArb。
mongo --port 2001rs.initiate()
rs.add("<hostname>:2002")
rs.addArb("<hostname>:2003")
rs.conf()
数据分片架构(Sharding)
当数据量比较大的时候,我们需要把数据分片运行在不同的机器中,以降低CPU、内存和IO的压力,Sharding就是这样的技术。数据库主要由两种方式做Sharding:纵向,横向,纵向的方式就是添加更多的CPU,内存,磁盘空间等。横向就是上面说的方式,如图所示:
MongoDB的Sharding架构:
MongoDB的Sharding架构
MongoDB分片架构中的角色:
数据分片(Shards)
保存数据,保证数据的高可用性和一致性。可以是一个单独的
mongod实例,也可以是一个副本集。在生产环境下Shard是一个Replica Set,以防止该数据片的单点故障。所有Shard中有一个PrimaryShard,里面包含未进行划分的数据集合:
查询路由(Query Routers)
mongos的实例,客户端直接连接mongos,由mongos把读写请求路由到指定的Shard上去。一个Sharding集群,可以有一个mongos,也可以有多mongos以减轻客户端请求的压力。
配置服务器(Config servers)
保存集群的元数据(metadata),包含各个Shard的路由规则。
搭建一个有2个shard的集群
1> 启动两个数据分片节点。在此仅演示单个mongod的方式,Replica Set类似。
mongod --port 2001 --shardsvr --dbpath shard1/mongod --port 2002 --shardsvr --dbpath shard2/
2> 启动配置服务器
mongod --port 3001 --dbpath cfg1/mongod --port 3002 --dbpath cfg2/
mongod --port 3003 --dbpath cfg3/
3> 启动查询路由mongos服务器
mongos --port 5000 --configdb 127.0.0.1:3001,127.0.0.1:3002,127.0.0.1:30034> 连接mongos,为集群添加数据分片节点。
mongo --port 5000 amdminsh.addShard("127.0.0.1:2001")
sh.addShard("127.0.0.1:2002")
如果Shard是Replica Set,添加Shard的命令:
sh.addShard("rsname/host1:port,host2:port,...")rsname - 副本集的名字
5> 可以连接mongos进行数据操作了。
mongo --port 5000 testmongoimport.exe --port 5000 -d test dataset.json
> 25359
数据的备份和恢复
MongodDB的备份有多种方式,这里只简单介绍一下mongodump和mongorestore的用法。
1> 备份和恢复所有db
mongodump -h IP --port PORT -o BACKUPPATHmongorestore -h IP --port PORT BACKUPPATH
2> 备份和恢复指定db
mongodump -h IP --port PORT -d DBNAME -o BACKUPPATHmongorestore -h IP --port PORT -d DBNAME BACKUPPATH
mongorestore -h IP --port PORT --drop -d DBNAME BACKUPPATH
3> 备份和恢复指定collection
mongodump -h IP --port PORT -d DBNAME -c COLLECTION -o xxx.bsonmongorestore -h IP --port PORT -d DBNAME -c COLLECTION xxx.bson
mongorestore -h IP --port PORT --drop -d DBNAME -c COLLECTION xxx.bson
小结
MongoDB的集群能力还是很强的,搭建还算是简单。最关键的是要明白上面提到的3种架构的原理,才能用的得心应手。当然不限于MongoDB,或许其他数据库也多多少少支持类似的架构。
参考资料
- 百度百科: http://baike.baidu.com/view/2850255.htm
- MongodDB官网文档:http://docs.mongodb.org/
davidpp
公众号:fury-programer(狂暴的游戏程序员) 知乎:davidpp
总资产91 (约7.77元)
共写了3.5W字
获得146个赞
共55个粉丝
全部评论
9
熊超华
8楼 03.12 10:48
怎么感觉分片,副本跟ES差不多
congyh
7楼 2016.12.08 16:50
我很喜欢您的文章, 请问可以转载吗?
davidpp
2016.12.08 19:02
@congyh 可以的
以上是 高可用的MongoDB集群 的全部内容, 来源链接: utcz.com/z/534803.html