📖Mysql基本操作 [数据库教程]

??Mysql基本操作
shell 命令
-u后输入用户名 -p后用于输入用户密码
mysql -uroot -proot
数据库
显示所有数据库
show databases;
创建数据库
create database 数据库名称;
删除数据库
drop database 数据库名称;
查看创建修改后的数据库详细信息
show create database 数据库名称;
选择数据库
use 数据库名称;
表
创建数据表,即在已存在的数据库中建立新表,必须先使用use指定数据库
create table 表名( 字段名 数据类型[完整型约束条件],
字段名 数据类型[完整型约束条件],
字段名 数据类型[完整型约束条件]
);
删除数据表
drop table 表名
修改表名
alter table 旧表名 rename 新表名
查看所有数据表
show tables;
查看数据表详情
show create table 表名;
使用G使结果更美观
show create table 表名G;
查看数据表详情-2
desc 表名;
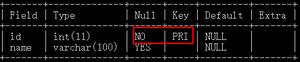
定义主码
## 方法一## 定义属性时,说明主码
create table s1(
id int primary key,
sname varchar(10)
);
## 方法二
## 定义完所有属性后,说明主码
create table s2(
id int,
sname varchar(10),
primary key(id)
);
## 多个属性为主码时
## 必须使用第二种方法
create table s3(
id int,
sno int,
sname varchar(10),
primary key(id, sno)
);
定义外码
create table c( cno int,
cname varchar(10),
cpno int,
primary key(cno),
foreign key (cpno) references c(cno)
// c(cno)表示它参考的是c表中的cno
// 故cpno的值有两种 空值NULL 或 存在的cno的值
);
字段
添加字段
alter table 表名 add 字段名 数据类型
删除字段
alter table 表名 drop 字段名
修改字段名
alter table 表名 change 旧字段名 新字段名 新数据类型
修改字段的数据类型
alter table 表名 modify 字段名 数据类型
修改字段在表中的排列位置, 放到第一或某个字段名后;
alter table 表名 modify 字段名1 数据类型 first(after 字段名2)
也可以增加一个新字段的同时决定它的位置
alter table 表明 add 字段名1 数据类型 first(after 字段名2)
表中数据
查看表中的数据
select * from 表名;
为表中字段添加数据
# 有主码时,必须给主码一个值insert into 表名(字段名1, 字段名2, ...)
values(值1, 值2, ...);
# 简写: 必须为所有字段都插入值
insert into 表名
values(值1, 值2, ....);
## 一次插入多个数据
insert into 表名(字段名1, 字段名2, ...)
values(值1, 值2, ...),
(值1, 值2, ...),
(值1, 值2, ...);
修改数据
update 表名set 字段名=值1[,字段名2=值2 ...]
[where 条件表达式]
where表示条件,例如where id=1表示只更改id=1的数据
没有where时会统一修改该字段名的所有数据
条件里面使用null时 where is null
提示: 有外码时,先插入其他数据,再更新外码
删除表数据
delete from 表名 [where 条件表达式]单表查询
select [*][字段名1,字段名2...] from 表名
[ where 条件表达式 ]
[ order by 字段名 [asc|desc] ]
[ group by 字段名 [Having条件表达式] ]
[ limit [num][num1,num2] ]
查询(去除重复结果)
select distinct 字段名 from 表名;
where
where后都可以用 or 或 and
in用来判断某个字段的值是否在指定集合中, not in用来判断不在
where 字段名 [not] in(元素1,元素2...)
判断字段的值是否在某个范围内
where 字段名 [not] between 值1 and 值2
模糊查询
where 字段名 [not] like ‘匹配字符va串‘
匹配字符串中使用通配符: %表示单个或多个字符, _表示单个字符
空值查询
where 字段名 is [not] null
排序和记录数
asc 升序, desc 倒序
asc 可以省略,因为 order by 默认是升序.
limit[num] 从第0个开始,查看num个数据
limit[num1,num2] 从num1开始,查看num2个数据
select 字段名 from 表名
order by 字段名 asc[desc]
limit [num][num1,num2];
统计记录的条数
查询记录条数select count(字段名) [重命名] from 表名;
查询去除重复项后的记录总数
select count(distinct(字段名)) [重命名] from 表名;
聚合函数
例:
select avg(grade) 平均分, max(grade) 最高分, min(grade) 最低分 from sc;
平均分 最高分 最低分
88.4000
96
70
group 分组
group by 字段名 [having条件表达式]
例:
对表sc, 根据cno进行分组, 显示不同组中 avg(grade)>=90 的 max,min,avg,sum 数据
select max(grade),min(grade),avg(grade),sum(grade) from sc
group by cno
having avg(grade)>=90;
多表连接查询
基础概念
笛卡尔积 : 左表的每一行数据 与 右表的每一行数据 组合
交叉连接 cross join : 笛卡尔积
内连接 inner join : 两个表先进行笛卡尔积, 然后只保留 具有相同数据 的行数据
左外连接 left join : 在内连接的基础上, 把 左表 舍弃的数据加入进来
右外连接 right join : 在内连接的基础上, 把 右表 舍弃的数据加入进来
内连接也叫自然连接
where 实现表的连接
自身连接
表c
cno cname teacher cpno
1
数据库_设计
Feng
2
2
数据结构
Huang
3
3
C语言
NULL
NULL
# 查询每门课程的先修课程 cpno# c1 c2 都是 c 表
# 相当于把 c1 c2 当做 c类 的 实例对象
select c1.cname, c2.cname
from c c1, c c2
where c1.cpno = c2.cno;
内连接 (自然连接)
# 因为两个表都有sno字段, 我们必须明确指定显示的是哪一个表的 sno# 又因为我们指定了s.sno=sc.sno , 所以显示 s.sno 或 sc.sno 是相同的
select s.sno, sname, grade
from s, sc
where cno=1 and s.sno=sc.sno;
join 实现表的连接
交叉连接
select * from 表1 cross join 表2;
内连接 (自然连接)
# 可以省略 innerselect 查询字段
from 表1 inner join 表2
on 表1.关系字段 = 表2.关系字段
左外连接 , 右外联接
select 查询字段 from 表1 left[right] join 表2
on 表1.关系字段 = 表2.关系字段
例:
select s.sno, sname, sclass, cno, gradefrom s left join sc
on s.sno = sc.sno;
嵌套查询 (子查询)
[not] in
# 查询选修了2号课程的学生姓名select sname
from s
where sno in(
select sno
from sc
where cno=2
);
any
将表达式与子查询的结果比较,只要有一个返回结果满足比较条件,就是符合条件的查询结果
selectall
将表达式与子查询的结果比较,所有的返回结果满足比较条件,就是符合条件的查询结果
将子查询的结果插入指定表中
INSERT INTO <表名> [(<属性列1> [,<属性列2>...)] 子查询;
保存子查询的结果
# 第一步:建表CREATE TABLE deptage(sdept CHAR(15),avgage INT);
# 第二步:插入数据
INSERT INTO deptage(sdept,avgage)
SELECT sdept,AVG(Sage)
FROM s
GROUP BY sdept;
带子查询的修改数据
# 将计算机科学系全体学生的成绩置零UPDATE sc
SET grade=0
WHERE sno in(
SELETE sno FROM s
WHERE sdept=‘CS‘
);
带子查询的删除数据
# 删除计算机科学系所有学生的选课记录delete from sc
where sno in(
selete sno
from s
where sdept=‘CS‘
);
集合查询
并查询 union
查询块1
union
查询块2
把两个查询块的结果,并集
参加UNION操作的各结果表的列数必须相同;对应项的数据类型也必须相同
交查询 intersect
差查询 except / minus
视图
视图可以从已有的表中提取出想要的字段
组合成一个你想要的类似表的东西
对视图的操作,会影响原表的数据
创建视图
createview <视图名> [(<列名>)]
as <子查询>
[with check option]
-- 加上with check option后就不能增删改(不满足子查询里where条件)的数据
修改视图
create or replaceview <视图名> (列名 列名 ...)
as <子查询>
[with check option]
删除视图
drop view 视图名,视图名2...查看视图,修改数据,修改字段 都与表操作相同
update 修改数据时,不能同时修改两个或多个表以上 中的数据
例如sc的grade和s的sname,不能同时修改它俩
删除数据时, 如果该视图包含两个表的信息,会没办法删除
范例
create view view_m
as select * from s where ssex=‘男‘;
insert into view_m
values(20,‘B‘,‘男‘,‘计科17-2‘,‘MA‘,20);
索引
一般对经常查询的内容创建索引
查看是否使用了索引
explain select * from t where sname="a";创建索引,在已有表上创建
create [unique|fulltext|spatial] index 索引名 on 表名(字段名[asc|desc]);范例:
create index index_sage on s(sage);
alter table 表名 add [unique|fulltext|spatial] index 索引名(字段名[asc|desc])
范例:
alter table s add index index_sage(sage);
创建索引,新建表时创建 普通索引
create table t ( id INT PRIMARY KEY auto_increment,
sname VARCHAR(20),
sage INT,
index(sanme)
);
创建索引,新建表时创建 唯一索引
create table t ( id INT PRIMARY KEY auto_increment,
sname VARCHAR(20),
sage INT,
unique index(sanme)
);
如果不加索引名,那么MySQL会以索引的第一个字段的名字来命名
而如果一个表下有多个索引的第一个字段都是相同的,
那么索引名会在字段名后加序数
create table t2 ( id INT PRIMARY KEY auto_increment,
sname VARCHAR(20),
sage INT,
index(sname),
index(sname,id)
);
index(sname)的索引名是sname
index(sname,id)的索引名时sname_2
删除索引
drop index 索引名 on 表名存储过程(函数)
查询
-- 例1:统计一共有多少名学生delimiter //
create procedure dp_s_count(out num int)
begin
select count(*) into num from s;
end; //
-- 调用存储过程
call dp_s_count(@snum);
select @snum 总人数;
-- 例2 变量:Mysql中变量不需要声明,可以直接使用@
#使用set时可以用“=”或“:=”,
#但是使用select时必须用“:=赋值”
#第一种用法
set @a=1;
SELECT @a;
#第二种用法
SELECT @c:=1;
-- 例3:通过使用declare 声明变量
create table test(id int);
delimiter//
create procedure sp1(in p int)
begin
declare v1 int;
set v1=p;
insert into test(id) values(v1);
end;//
delimiter//
create procedure sp2(in p int)
begin
insert into test(id) values(p);
end;//
#上述代码表示的含义:
-- 调用存储过程
call sp1(1);
-- 查看test表
SELECT * FROM test;
-- 例4:存储过程返回数据集
-- 统计男女生的总人数
delimiter //
create procedure sp_ssex()
begin
select ssex, count(sno) 人数 from s group by ssex;
end; //
-- 调用
call sp_ssex();
-- 例5:创建一个简单的存储过程,输出hello world,并执行该存储过程。
SELECT "hello";
delimiter //
create procedure hello()
begin
select "hello world";
end; //
-- 调用
call hello();
-- 例6:创建一个带输入参数的简单存储过程:
#计算某名学生所选课程总数,并执行该存储过程。
select count(sno) from sc where sno=1;
delimiter //
create procedure sp_sc_num(in id int)
begin
select count(sno) from sc where sno=id;
end; //
-- 调用
call sp_sc_num(1);
-- 例7:创建一个测试表test1(id int,sname varchar(10)),
#创建一个含有两个输入参数的存储过程,用来给test1表插入数据
create table test(id int, sname varchar(10));
delimiter //
create procedure p_insert_two_param(in p1 int, in p2 varchar(10))
begin
insert into test values(p1,p2);
end; //
-- 调用
call p_insert_two_param(1, "zy");
-- 例8:统计某课程的选课人数,
#创建带有一个输入参数和一个输出参数的存储过程。
#并执行该存储过程。
delimiter //
create procedure p_in_and_out(in p1 int, out p2 varchar(10))
begin
insert into test(id) values(p1);
select count(*) into p2 from test;
end; //
-- 调用
#在调用带有输出参数的存储过程时
#输出参数必须是一个带@符号的变量
call p_in_and_out(3,@num);
select * from test;
select @num;
-- 例9:创建一个不带有任何参数的存储过程,用来统计学生表中的男女人数
#并执行该存储过程
delimiter //
create procedure p_num_man_and_women()
begin
select ssex, count(sno)人数 from s group by ssex;
end; //
-- 调用
call p_num_man_and_women();
删除
-- 例10:删除存储过程 DROP Procedure <存储过程名>;(只能一个一个的删除)
drop procedure sp_ssex_count,sp_c_count; -- 错误
触发器
参考地址: MySql触发器使用
-- 例1:利用触发器实现学生与成绩表学生编号上的级联更新。delimiter //
create trigger update_sc_sno after update on s for each row
begin
update sc set sno = new.sno where sno = old.sno;
end; //
-- 验证
set foreign_key_checks=0;
update s set sno = 1 where sno = 11;
-- 如果发生错误
-- 例2:利用触发器实现学生与成绩表学生编号上的级联删除。
insert into sc values(9,1,80);
insert into s(sno) values(9);
delimiter //
create trigger del_sc after delete on s for each row
begin
delete from sc where sno = old.sno;
end; //
delete from s where sno = 9;
-- 验证
set foreign_key_checks=0;
delete from s where sno = 9;
-- 如果发生错误
-- 例3:在学生基本情况表(s)上建立一个插入触发器,
#实现当向表中插入一条记录时系表(sdept)相应的系人数自动加1。
#1创建表
create table t_sdept(
id int primary key auto_increment,
sdept_name varchar(10),
s_num int);
#2表中插入数据
insert into t_sdept(sdept_name,s_num)
select sdept,COUNT(sno) from s group by sdept;
#3创建触发器
delimiter //
CREATE TRIGGER sdept_oneplus after insert on s for each row
BEGIN
update t_sdept set s_num = s_num + 1 where sdept_name = new.sdept;
END; //
#4验证
insert into s values(9,"夏一","女","计科17-1","IS",20);
select * from s;
select * from t_sdept;
事务
-- 银行转账例子#创建账户表
create table account(
id int primary key auto_increment,
name varchar(20),
money int
);
#表中插入数据
insert into account
values(1, "张三",1000),
(2,"李四",0);
#查看表中数据
select * from account;
#创建一个触发器(触发器的作用是使得每个账号的钱不少于1块钱)
## delimiter$$表示将语句的结束符;改成$$
delimiter $$
create trigger tri_account_money before update on account for each row
begin
if new.money<1 then
set new.money = old.money;
end if;
end; $$
-- 模拟转账:张三转账1000元给李四
update account set money = money - 1000 where name="张三";
update account set money = money + 1000 where name="李四";
rollback;
-- 转账后账户余额:
张三 1000
李四 1001
-- 撤销刚才的事务
rollback; #撤销刚才的事务(没有起作用)
-- 通过事务实现转账业务
#每条单独的SQL语句视为一个事务
#MySQL默认状态,事务会自动提交,
#关闭默认提交状态后,-- 语法:set autocommit=0;
#也可以手动开启、关闭事务;
#事务的手动开始:start transaction 或 begin
#事务的手动正常结束--提交:commit; (手动结束事务)
#事务的手动回滚(撤销)--提交:rollback; (手动结束事务)
-- 例1:转账演示(转账失败rollback)
start transaction;
select * from account;
update account set money = money - 1000 where name="张三";
update account set money = money + 1000 where name="李四";
select * from account;
rollback;
select * from account;
-- 例2:转账演示(commit)张三给李四转100元
start transaction;
select * from account;
update account set money = money - 100 where name="张三";
update account set money = money + 100 where name="李四";
select * from account;
commit;
📖Mysql基本操作
以上是 📖Mysql基本操作 [数据库教程] 的全部内容, 来源链接: utcz.com/z/534762.html