PG库实现t+1同步

需求:业务场景中有很多需要查询t+1的数据,但又不想影响生产实时的业务,是否可以搭建一个延时的灾备库就可以解决这个问题呢。
问题:如何实现延时?
解决方向:recovery_min_apply_delay (integer)
这个参数可以实现从库的延时同步。
测试过程:
配置在备库recovery.conf中
recovery_min_apply_delay = 5min
主库插入一条数据,5分钟后从库可以查到该数据,在此期间,不影响从库的使用。
需要注意的是,如果从库配置了synchronous_commit 这个参数,一定要配为on,配为remote_apply时,在主库上插入一条数据,主库会hang住等待5min(等待从库完成apply操作)后,然后才能返回执行成功or失败的结果。
9.4版本之前存在bug,配置好这个参数后,马上重启standby库,连接数据库会报错如下:psql: FATAL: the database system is starting up,这时候需要等待配置时间,然后连接才可以正常使用数据库,但是目前这个bug已经修复了。高版本不存在这个问题。
从库放开给用户使用,带来的问题:
在进行主从复制的时候,如果从库放开给用户使用,很容易产生冲突。举个例子,从库有一个长事务或者长查询正在执行,此时,主库执行 UPDATE 并 VACUUM,由于主库上已经不存在使用被更新元组的事务,VACUUM 会将这些元组清理掉,当从库回放到 VACUUM 对应的日志时,检测到当前 VACUUM 清理的元组仍然有事务在使用,则认为有冲突,在等待 max_standby_streaming_delay(默认30s) 后,若事务仍然没有执行完,则中断 SLAVE 上的连接,这时候就产生了冲突。
解决方向:hot_standby_feedback (boolean)
通过设置 HOT_STANDBY_FEEDBACK 解决因 MASTER 执行 VACUUM 引起的复制冲突。
测试过程:
配置在主库postgresql.conf中
hot_standby_feedback = on --如果有错误的数据复制,向主库进行反馈
HOT_STANDBY_FEEDBACK 的原理很简单,就是将从库的最小活跃事务ID定期告知主库,使得主库在执行 VACUUM 时对这些事务还需要的数据手下留情。
设置 HOT_STANDBY_FEEDBACK 的好处是可以减少从库执行查询时复制冲突的可能,但也有其弊端,即会使主库延迟回收,从而导致数据膨胀;极端情况下,如果从库有一个很长的事务,且涉及的表上DML操作又很频繁,则表的膨胀是不容小觑的,表膨胀,进而使得主库出现IO抖动。
解决冲突问题:
max_standby_streaming_delay(默认30s):
从库因为接收wal流日志产生查询冲突而取消查询之前的等待时间,设置该参数会在发生冲突时,备库查询不会立即取消,而是等待一个时间后如果还没结束再抛出报错。这个值的大小可以参考从库可能产生的长事务运行时间。
测试过程:
配置在主库postgresql.conf中
max_standby_streaming_delay = 30s --数据流备份的最大延迟时间
max_standby_archive_delay:
备机因为处理归档的wal日志产生查询冲突而取消查询之前的等待时间,和上面的参数类似。
测试过程:
配置在主库postgresql.conf中
max_standby_archive_delay = 30s --数据流备份的最大延迟时间
注意这两个参数不要配置为-1,如果配置为-1, 那么在从库上可以无限时常的执行sql。后果是从库只接收但是不归档 xlog. 造成从库 xlog文件越来越多, 甚至撑爆磁盘分区。
vacuum_defer_cleanup_age:
指定vacuum延迟清理死亡元组的事务数,vacuum会延迟清除无效的记录,延迟的事务个数通过vacuum_defer_cleanup_age进行设置。即vacuum和vacuum full操作不会立即清理刚刚被删除元组。
生产环境里可以根据pg_stat_database和pg_stat_database_confliects视图查看冲突发生的情况,以此来进行如上参数的调整。
Oracle:
方法1: 在备库指定delay属性
alter database recover managed standby database delay 10 disconnect from session;
--备库延迟10分钟应用主库日志
方法2: log_ archive_dest_n参数中指定了delay属性
alter system set log_archive_dest_3="service=goolen lgwr async delay=10 valid_for=(all_logfiles,all_roles) db_unique_name=goolen";
注意:delay属性并不是说延迟发送主库日志到备库,而是指日志到备库后,延迟多长时间应用主库日志。如果在备库应用主库日志的语句中指定了实时应用,也就是使用了using current logfile,如alter database recover managed standby database using current logfile disconnect from session;那么,即使在log_ archive_dest_n参数中指定了delay属性,备库也会忽略delay属性。
方法3:alter system set log_archive_dest_state_2=defer;
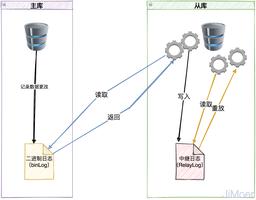
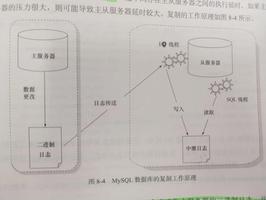
MYSQL:
使用MASTER_DELAY选项CHANGE MASTER TO将延迟设置为N秒:
CHANGE MASTER TO MASTER_DELAY = N;
在修改延迟从库的master_delay数值的时候,设置新的master_delay之后,MySQL自动将从库的所有relay log清空,并重新生成,序号从000001开始,清掉relay log以后,MySQL会重新拉取还没应用过的binlog,避免数据丢失。
每次修改延迟数据,都要清掉relay log,再重新拉取binlog,造成主库和从库之间重复的数据流量,消耗了不必要的资源。
修改master_delay,根本不需要stop slave将整个从库停止,而只需要stop slave sql_thread即可, MySQL就不会清除并重新生成relay log了。
以上是 PG库实现t+1同步 的全部内容, 来源链接: utcz.com/z/534493.html