如何深入理解关系型数据库的三大范式

该文章,GitHub已收录,欢迎老板们前来Star!
GitHub地址: https://github.com/Ziphtracks/JavaLearningmanual
数据库范式
一、什么是数据库范式
设计关系数据库时,遵从不同的规范要求,设计出合理的关系型数据库,这些不同的规范要求被称为不同的范式,各种范式呈递次规范,越高的范式数据库冗余越小。
范式来自英文Normal form,简称NF。要想设计—个好的关系,必须使关系满足一定的约束条件,此约束已经形成了规范,分成几个等级,一级比一级要求得严格。满足这些规范的数据库是简洁的、结构明晰的,同时,不会发生插入(insert)、删除(delete)和更新(update)操作异常。
二、数据库范式分类
目前关系数据库有六种范式:第一范式(1NF)、第二范式(2NF)、第三范式(3NF)、巴斯-科德范式(BCNF)、第四范式(4NF)和第五范式(5NF,又称完美范式)。满足最低要求的范式是第一范式(1NF)。在第一范式的基础上进一步满足更多规范要求的称为第二范式(2NF),其余范式以次类推。一般来说,数据库只需满足第三范式(3NF)就行了。
三、数据库三大范式剖析
3.1 第一范式(1NF)
第一范式强调每一列都是不可分割的原子数据项。
说到原子这个词,肯定有小伙伴就先到了原子性问题,其实这么想也是没有错的。那就让我带你们去剖析一下第一范式。
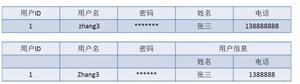
首先,我用Excel表格模拟数据库中的表,并在表中填入了一些数据。如下:
当你看到这些数据的时候,是否有些数据让你感到不适?我的答案,是的。当我看到系名/系主任这一列数据的时候感觉这并不合符我们数据库的设计理念,因为它完全可以拆分为两个列的。其实每一个人的思想中的已经有了这个范式要求的概念,只是你并不知道这个概念叫做第一范式。
如果有的小伙伴说,这些数据都让感到不适,那我就在这里夸上你一句,你很聪明。但是请你跟紧我的思路,我会一步一步的将数据落实到范式中!
表1显然不遵循第一范式,那我们就把它修改一下,让其遵循第一范式的要求。
将系名/系主任的列拆分成了两个列系名和系主任后,很明显改数据已经遵循的第一范式的要求。再来看看这张表2,聪明的你是不是第一眼又发现了问题呢?
存在的问题:
- 存在非常严重的数据冗余,姓名、系名、系主任
- 添加数据问题:当在数据表中添加一个新系和系主任时,比如:在数据表中添加高主任管理化学系。你会发现添加之后,在一个数据表中就会多出来了高主任和化学系,而这两个数据并没有对应哪个学生,显然这时不合法的数据。
- 删除数据问题:如果Jack同学毕业多年了,我们数据表中没有必要在留Jack相关的数据了,就会想到把Jack相关的删除掉。当你在表2的表结构中删除了Jack相关数据,你会发现整个刘主任和管理系以及会计和酒店管理都消失了,难道数据表中没有这些数据就证明这个学校没有它们吗?显然这更加离谱了!
了解了只遵循第一范式带来的麻烦,我们就需要去看一下第二范式是怎么定义的,是否能解决第一范式留下来的问题!
3.2 第二范式(2NF)
第二范式在1NF的基础上,非属性码的属性必须完全依赖于主码。(在1NF基础上消除非属性码的属性对主码的部分函数依赖)
看到第二范式的概念,现在你应该是一个不懂的状态。那让我带你了解几个概念吧,这样你就会懂了!
函数依赖(完全、部分、传递)
函数依赖: A - > B,如果通过A属性(或属性组)的值可以确定唯一B属性的值,则可以成为B依赖于A(- >符号是确定关系)。例如:可以通过学号来确定姓名,可以通过学号和课程来确定该课程的分数等等
- 完全函数依赖: A - > B,如果A是一个属性组,则B属性的确定需要依赖A属性组中的所有属性值。例如:分数的确定需要依赖于学号和课程,而学号和课程可以称为一个属性组。如果有学号没有课程,我们只知道是谁的分数,而不知道是那一学科的分数。如果有课程没有学号,那我们只知道是哪一个学科的分数,而不知道是谁的分数。所以该属性组的两个值是必不可少的。这就是完全函数依赖。
- 部分函数依赖: A - > B,如果A是一个属性组,则B属性的确定需要依赖A属性组中的部分属性值。例如:如果一个属性组中有两个属性值,它们分别是学号和课程名称。那姓名的确定只依赖这个属性组中的学号,于课程名称无关。简单来说,依赖于属性组的中部分成员即可成为部分函数依赖。
- 传递函数依赖: A - > B - > C,传递函数依赖就是一个依赖的传递关系。通过确定A来确定B,确定了B之后,也就可以确定C,三者的依赖关系就是C依赖于B,B依赖于A。例如:我们可以通过学号来确定这位学生所在的系部,再通过系部来确定系主任是谁。而这个三者的依赖关系就是一种传递函数依赖。
候选码、主属性码与非属性码
- 码: 如果在一张表中,一个属性或属性组,被其他所有属性所完全函数依赖 ,则称这个属性(或属性组)为该表的候选码,简称码。然而码又分为主属性码和非属性码。例如:分数的确定没有学号和课程是不行的,所以分数完全函数依赖于课程和学号。
- 主属性码: 主属性码也叫主码,即在所有候选码挑选一个做主码,这里相当于是主键。例如:分数完全函数依赖于课程和学号。该码属性组中的值就有课程、学号和分数,所以我们要在三个候选码中,挑选一个做主码,那就可以挑选学号。
- 非属性码: 除主码属性组以外的属性,叫做非属性码。例如:在分数完全函数依赖于课程和学号时,其中学号已经让我们选为主码。那么我们就可以确定,除了学号以外的属性值,其他的属性值都是非属性码。也就是说在这个完全函数依赖关系中,课程和分数是非属性码。
当我们了解这些概念后,回过头来再看2NF的概念:在1NF的基础上,非属性码的属性必须完全依赖于主码(在1NF基础上消除非属性码的属性对主码的部分函数依赖)
我们还使用分数完全函数依赖于学号和课程这个函数依赖关系。此关系中非属性码为:课程和分数,主码为学号。梳理清楚关系后,遵循在1NF基础上,非属性码的属性必须完全依赖于主码的第二范式。就需要继续修改表结构了。遵循1NF和2NF的表结构如下:
正如你所看到的,我们把表2根据1NF和2NF拆分成了表3和表4。这时候你再看表3,表3中的分数就完全函数依赖于表3中的学号和课程。表4中也挑选学号做主码。虽然解决了数据冗余问题,但是仅仅这样还是不够的,上述问题中其他的两个问题并没有得到解决!
存在的问题:
- 数据删除问题
- 数据添加问题
注意: 在第二范式中存在的这两个问题,就是在第一范式中存在问题的其中两个并没有得到解决。
既然第一范式和第二范式都没有解决这两个问题,那第三范式帮你解决!
3.3 第三范式(3NF)
第三范式在2NF基础上,消除传递依赖。
说到传递依赖,那我们的数据表中还有哪些传递依赖呢?这时候你会发现表4中含有传递依赖的。表4中的传递依赖关系为:姓名 - > 系名 - > 系主任。该传递依赖关系为系主任传递依赖于姓名。再根据此传递依赖关系分析我们添加和删除问题就漏洞百出了。消除传递依赖的办法还是将表4进行拆分。拆分后的表结构如下:
当我们把表4拆分成表5和表6时,你再来分析添加和删除问题就会有不一样的结果。假设在数据表中添加高主任管理的化学系时,该数据只会添加到表6中,不会发生传递依赖而影响其他数据。那假设Jack同学毕业了,要将Jack同学的相关数据从表中删除,这时我们需要删除表6中的学号3数据和表3中的学号3数据即可,它们也没有传递依赖关系,同样不会影响到其他数据。
四、范式的表设计
在这里我详细讲解了数据库的三大范式,为什么一般我们只研究三大范式而不去延申至六大范式呢?在上面数据库范式概念的时候,我也有讲过。这里我还需要强调一下!
数据库六大范式,一级比一级要求得严格。各种范式呈递次规范,越高的范式数据库冗余越小。范式即是对数据库表设计的约束,约束越多,表设计就越复杂。表数据过于复杂,对于我们后期对数据库表的维护以及扩展、删除、备份等种种操作带来了一定的难度。所以,在实际开发中我们只需要遵循数据库前面的三大范式即可,不需要额外延申扩展。
注意: 在剖析三大范式的时候,最终版本的表结构就是表3 + 表5 + 表6。我需要在这里说明一个问题,其实这样设计表是可以的,但并不是很合理。因为我们在建表的时候是有主键和外键约束的。这三张表中,第一列的表默认为主键,其中主键为学号还可以接收,如果主键为系名那就占用的空间变大了。在表的级联查询中会损耗性能。所以,一般我们在设计表的时候,是需要主外键约束的,而其主外键基本是都是占用内容空间很小的数字。当你的表结构和需求满足主键递增时,则可以通过设置auto_increment参数来完成!
这里如果不了解MySQL主外键约束的小伙伴,可以参考此文章MySQL基础来查补缺漏知识点。
以上是 如何深入理解关系型数据库的三大范式 的全部内容, 来源链接: utcz.com/z/534135.html