索引——谈谈你对索引的认识和理解

为什么要用索引?
一般的应用系统,读写比例在10:1左右,插入操作和一般的更新操作很少出现性能问题,在生产环境中,我们遇到最多的,也是最容易出问题的,还是一些复杂的查询操作,因此对查询语句的优化显然是重中之重。说起加速查询,就不得不提到索引了。
索引是什么?
索引在MySQL中也叫做“键”,是存储引擎用于快速找到记录的一种数据结构。
索引对于良好的性能非常关键,尤其是当表中的数据量越来越大时,索引对于性能的影响愈发重要。
索引优化应该是对查询性能优化最有效的手段了。索引能够轻易将查询性能提高好几个数量级。
索引相当于字典的音序表,如果要查某个字,如果不使用音序表,则需要从几百页中逐页去查。
索引原理:
与我们查阅图书所用的目录是一个道理:先定位到章,然后定位到该章下的一个小节,然后找到页数。相似的例子还有:查字典,查火车车次,飞机航班等.
本质都是:通过不断地缩小想要获取数据的范围来筛选出最终想要的结果,同时把随机的事件变成顺序的事件,也就是说,有了这种索引机制,我们可以总是用同一种查找方式来锁定数据。
索引两大类型:
hash类型的索引:查询单条快,范围查询慢
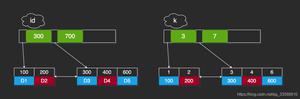
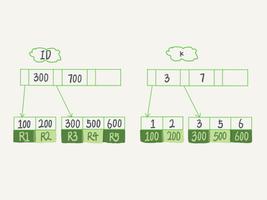
btree类型的索引:b+树,层数越多,数据量指数级增长(我们就用它,因为innodb默认支持它)
索引的功能:加速查找,约束功能
适合建索引的字段:
- 经常被查询的字段,即在where子句中出现的字段
- 在分组的字段,即在group by子句中出现的字段
- 存在依赖关系的子表和父表之间的联合查询,即主键或外键字段
- 设置唯一完整性约束的字段
不适合建索引字段:
- 在查询中很少被使用的字段
- 拥有许多重复值的字段
创建索引:
创建索引:就是在表的一个字段或者多个字段上建立索引
普通索引index:加速查找
唯一索引:
- 主键索引(primary key):加速查找+约束(不为空、不能重复)
- 唯一索引(unique):加速查找+约束(不能重复)
联合索引:
- primary key(id,name):联合主键索引
- unique(id,name):联合唯一索引
- index(id,name):联合普通索引
创建普通索引:
普通索引:创建索引时,不附加任何限制条件(唯一、非空等限制),该索引可以创建在任何列上。
语法:create table 表名( ... ,index|key [索引名](列名, [(长度)] [asc|desc]) ); //长度和asc|desc可省略
案例:create table uid( id int, ..., index index_id(id) );
createtable uid( id int,
...,
index index_id(id)
);
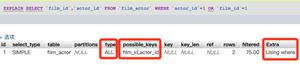
通过explain查看索引是否被执行:
explain select*from uid where id=001;
在已经存在的字段上建立索引:
语法:create index 索引名 on 表名 (列名 [(长度)] [asc|desc])
案例:
createindex index_id on uid(id);
通过alter来创建索引:
语法:altert able 表名 add index|key 索引名 (列名 [(长度)] [asc|desc])
案例:
altertable uid addindex index_id(id);
创建唯一索引:
唯一索引:就是限制某个或者多个字段的值必须唯一,通过该类型的索引可以快速的查询某条记录
语法:create table 表名( ... , unique index|key [索引名](列名 [(长度)] [asc|desc]) );
案例:
createtable uid(id int,...,
uniqueindex index_id(id));
已有的表上建索引:
案例
createuniqueindex index_id on uid(id);
通过alter添加索引:
案例
altertable uid adduniqueindex index_id(id);
创建全文索引
全文索引主要关联在数据类型为char、varchar和text的字段上,以便能够快速的查询数据量较大的字符串类型的字段
语法:create table 表名( ... , fulltext index|key [索引名](列名 [(长度)] [asc|desc]) );
创建多列索引(联合索引)
多列索引:是指创建索引的字段不是一个字段,而是多个字段,虽然可以通过关联的字段进行查询,但是只有查询条件中使用了所关联的字段中的第一个字段,多列索引才会被使用。
语法:create table 表名( ... , index|key [索引名](列名1 [(长度)] [asc|desc]) ,列名2 [(长度)] [asc|desc]) );
案例
createtable uid( ...,
name varchar(20),
loc varchar(40),
index index_name_loc(name, loc)
);
已经存在的表上创建索引:
案例
createindex index_name_loc on uid(name, loc);
altertable uid addindex index_name_loc(name,loc);
多个单列索引在多条件查询时只会生效第一个索引!所以多条件联合查询时最好建联合索引!
最左前缀原则:
顾名思义是最左优先,以最左边的为起点任何连续的索引都能匹配上,
注:如果第一个字段是范围查询需要单独建一个索引
注:在创建联合索引时,要根据业务需求,where子句中使用最频繁的一列放在最左边。这样的话扩展性较好,比如 userid 经常需要作为查询条件,而 mobile 不常常用,则需要把 userid 放在联合索引的第一位置,即最左边
联合索引本质:
当创建(a,b,c)联合索引时,相当于创建了(a)单列索引,(a,b)联合索引以及(a,b,c)联合索引
想要索引生效的话,只能使用 a,和a,b,和a,b,c三种组合;当然,我们上面测试过,a,c组合也可以,但实际上只用到了a的索引,c并没有用到!
联合索引总结:
需要加索引的字段,要在where条件中;
数据量少的字段不需要加索引(因为建索引有开销,速度反而慢);
如果where条件中是or关系,加索引不起作用;
联合索引比每个列分别建索引更有优势,因为建索引有开销,顺序也要注意,一般不超过7,8个,应该将严格的索引放在前面,这样筛选力度会更大,效率更高。
删除索引:
语法:drop index index_name on table_name;
案例
dropindex index_id on uid;
https://www.cnblogs.com/bypp/p/7755307.html
https://blog.csdn.net/fengxiaolu311/article/details/82716294
以上是 索引——谈谈你对索引的认识和理解 的全部内容, 来源链接: utcz.com/z/534061.html